
Redis
一:Redis客户端工具
Another Redis DeskTop Manager
Redis Desktop Manager
二:网址
https://db-engines.com/en/
http://redis.cn/
三:简介
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
key-value(string,hash,list,set,sorted set)
memcache也是key-value,但是value没有类型的分类
四:安装redis
redis6.x一下
# 1.下载
wget http://download.redis.io/releases/redis-6.0.6.tar.gz
或者直接下载 redis.cn
tar -zxvf redis-6.0.6.tar.gz
# 2.编译
直接 make
# 3.如果报错就安装gcc,不报错则跳过
yum install gcc
# 4.清理之前的make
make distclean
# 5.安装redis,这一步可以跳过,直接安装到系统中
默认安装到/usr/local得话:make install
指定安装到某个目录: make install PREFIX=/usr/local/redis-6.0.6
redis6.x
# 1.下载
wget http://download.redis.io/releases/redis-6.0.6.tar.gz
或者直接下载 redis.cn
tar -zxvf redis-6.0.6.tar.gz
# 2.编译
查看gcc版本:gcc -v
如果不是5.3版本以上,则执行下面命令
yum -y install centos-release-scl
yum -y install devtoolset-9-gcc-c++ devtoolset-9-binutils
设置版本生效(永久)(echo "source /opt/rh/devtoolset-9/enable" >>/etc/profile),(source /etc/profile)并再次查看版本(gcc -v)
设置版本生效(临时)(scl enable devtoolset-9 bash),并再次查看版本(gcc -v)
make distclean
直接 make # 因为redis6.0.6加上多线程atomic,如果直接输入make,就会报错
# 3.如果报错就安装gcc,不报错则跳过
yum install gcc
# 4.安装redis,将一些可执行文件放到指定的目录中
默认安装到/usr/local得话:make install
指定安装到某个目录: make install PREFIX=/usr/local/redis-6.0.6
# 5.将redis创建一个环境变量
echo "export REDIS_HOME=/usr/local/software/redis-6.0.6" >>/etc/profile
echo "export PATH=$PATH:$REDIS_HOME/bin" >>/etc/profile
vim /etc/profile # 查看是否已经添加进去
source /etc/profile
# 6(1).安装redis作为一个服务,使用systemctl
# 如果出现这个问题
Welcome to the redis service installer
This script will help you easily set up a running redis server
This systems seems to use systemd.
Please take a look at the provided example service unit files in this directory, and adapt and install them. Sorry!
# 在/lib/systemd/system 目录下创建一个 redis.service,输入以下:
Description=Redis
After=network.target
[Service]
ExecStart=/usr/local/software/redis-6.0.6/bin/redis-server /usr/local/software/redis-6.0.6/redis.conf --daemonize no
ExecStop=/usr/local/software/redis-6.0.6/bin/redis-cli -h 127.0.0.1 -p 6379 shutdown
[Install]
WantedBy=multi-user.target
# 创建软连接 为了系统重启时自启动服务准备
ln -s /lib/systemd/system/redis.service /etc/systemd/system/multi-user.target.wants/redis.service
# 刷新配置
systemctl daemon-reload
# 启动redis
systemctl start redis
# 停止redis
systemctl stop redis
# 重启redis
systemctl restart redis
# 6(2).安装redis作为一个服务,使用server
需要注释install_service.sh文件中:
#bail if this system is managed by systemd
#_pid_1_exe="$(readlink -f /proc/1/exe)"
#if [ "${_pid_1_exe##*/}" = systemd ]
#then
# echo "This systems seems to use systemd."
# echo "Please take a look at the provided example service unit files in this directory, and adapt and install them. Sorry!"
# exit 1
#fi
运行:./install_service.sh
Selected config:
Port : 6379
Config file : /etc/redis/6379.conf
Log file : /var/log/redis_6379.log
Data dir : /var/lib/redis/6379
Executable : /usr/local/software/redis-6.0.6/bin/redis-server
Cli Executable : /usr/local/software/redis-6.0.6/bin/redis-cli
Copied /tmp/6379.conf => /etc/init.d/redis_6379
# 查看状态
service redis_6379 status
# 启动
service redis_6379 start
# 停止
service redis_6379 stop
# 直接杀死进程
kill -9 PID
如果遇到启动错误
rm -rf /var/run/redis_6379.pid
五:单机使用
epoll
内核 客户端连接
# 阻塞BIO,阻塞时期
之前:获得文件标识符 read from a file descriptor,0是标准输入,1是标准输出,2是报错异常处理
socket在包没到达前是阻塞的blocking BIO
yum install man man-pages
# 非阻塞NIO,同步非阻塞时期
遍历轮询,如果有1000个fd,那么代表用户进程轮询1000次kernel,成本很大
# 多路复用NIO,epoll
redis进入命令
# 进入
redis-cli 默认6379
redis默认有0-15数据库
# 帮助
redis-cli -h
# 查看命令,要先进入redis
127.0.0.1:6379> help @generic
127.0.0.1:6379> help @String
# 切换数据库
select number
string
介绍
tring 是最基本的 key-value 结构,key 是唯一标识,value 是具体的值,value其实不仅是字符串, 也可以是数字(整数或浮点数),value 最多可以容纳的数据长度是 512M。
内部实现
String 类型的底层的数据结构实现主要是 int 和 SDS(简单动态字符串)。
SDS 和我们认识的 C 字符串不太一样,之所以没有使用 C 语言的字符串表示,因为 SDS 相比于 C 的原生字符串:
- SDS 不仅可以保存文本数据,还可以保存二进制数据 。因为
SDS使用len属性的值而不是空字符来判断字符串是否结束,并且 SDS 的所有 API 都会以处理二进制的方式来处理 SDS 存放在buf[]数组里的数据。所以 SDS 不光能存放文本数据,而且能保存图片、音频、视频、压缩文件这样的二进制数据。 - SDS 获取字符串长度的时间复杂度是 O(1) 。因为 C 语言的字符串并不记录自身长度,所以获取长度的复杂度为 O(n);而 SDS 结构里用
len属性记录了字符串长度,所以复杂度为O(1)。 - Redis 的 SDS API 是安全的,拼接字符串不会造成缓冲区溢出 。因为 SDS 在拼接字符串之前会检查 SDS 空间是否满足要求,如果空间不够会自动扩容,所以不会导致缓冲区溢出的问题。
字符串对象的内部编码(encoding)有 3 种 : int、raw和 embstr 。
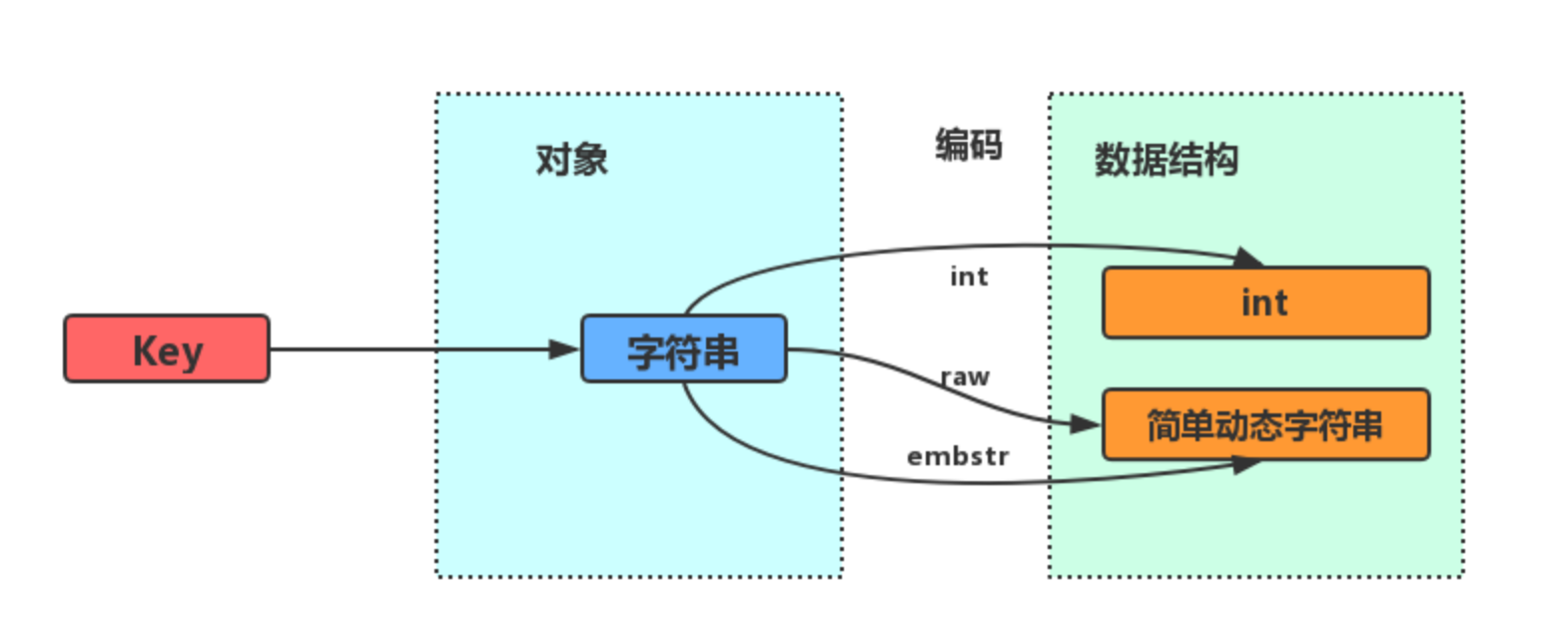
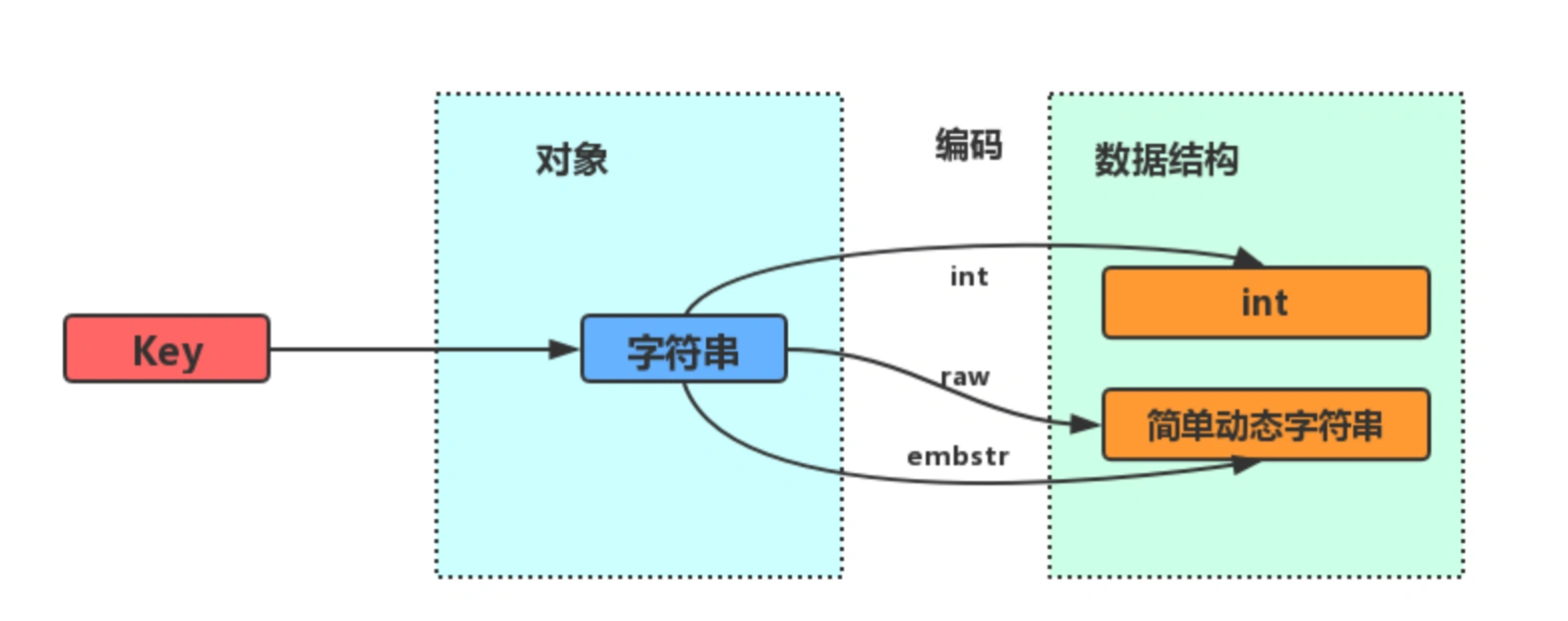
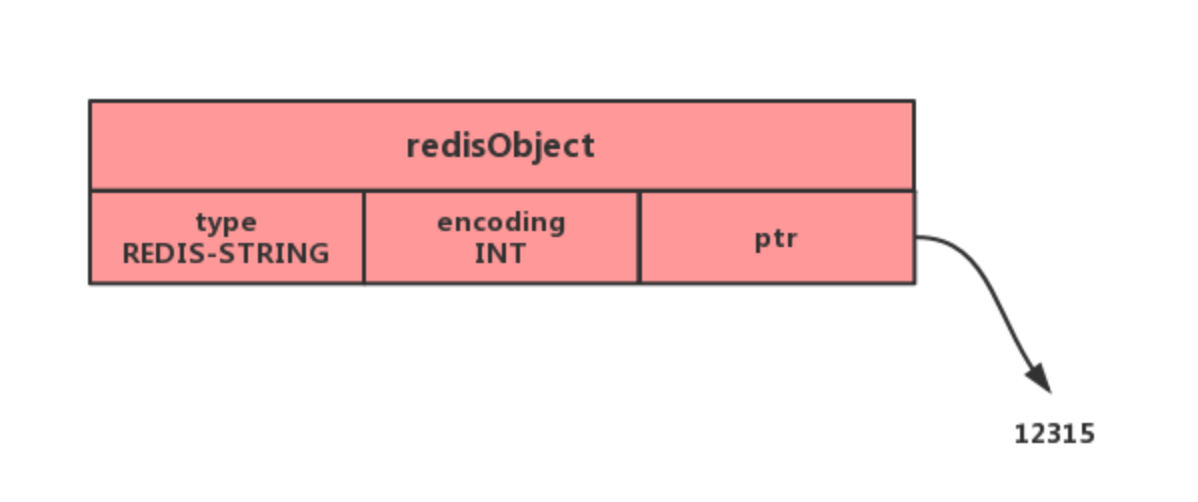
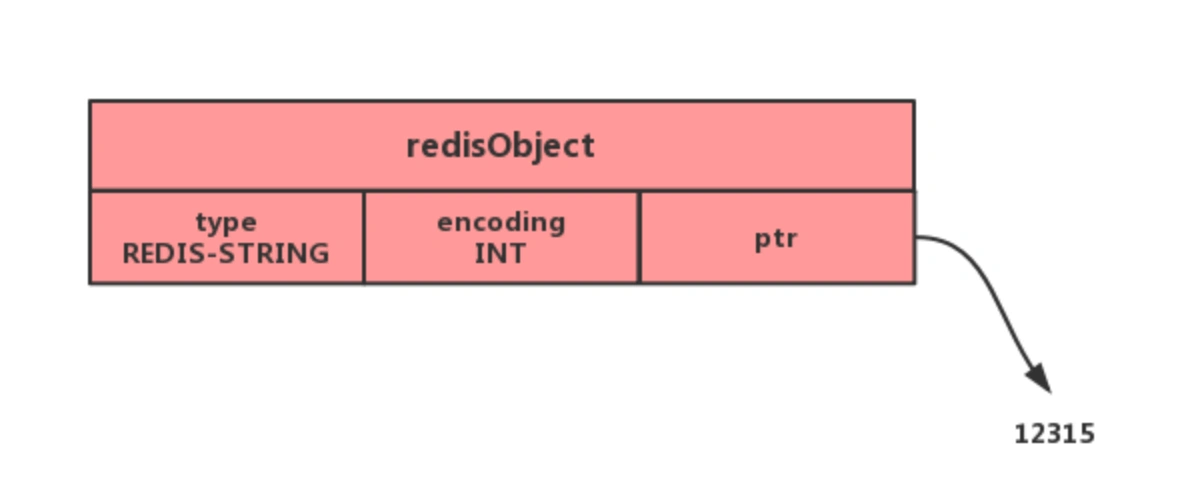
如果一个字符串对象保存的是整数值,并且这个整数值可以用 long类型来表示,那么字符串对象会将整数值保存在字符串对象结构的 ptr属性里面(将 void*转换成 long),并将字符串对象的编码设置为 int。
如果字符串对象保存的是一个字符串,并且这个字符申的长度小于等于 32 字节(redis 2.+版本),那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串,并将对象的编码设置为 embstr, embstr编码是专门用于保存短字符串的一种优化编码方式:


如果字符串对象保存的是一个字符串,并且这个字符串的长度大于 32 字节(redis 2.+版本),那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串,并将对象的编码设置为 raw:
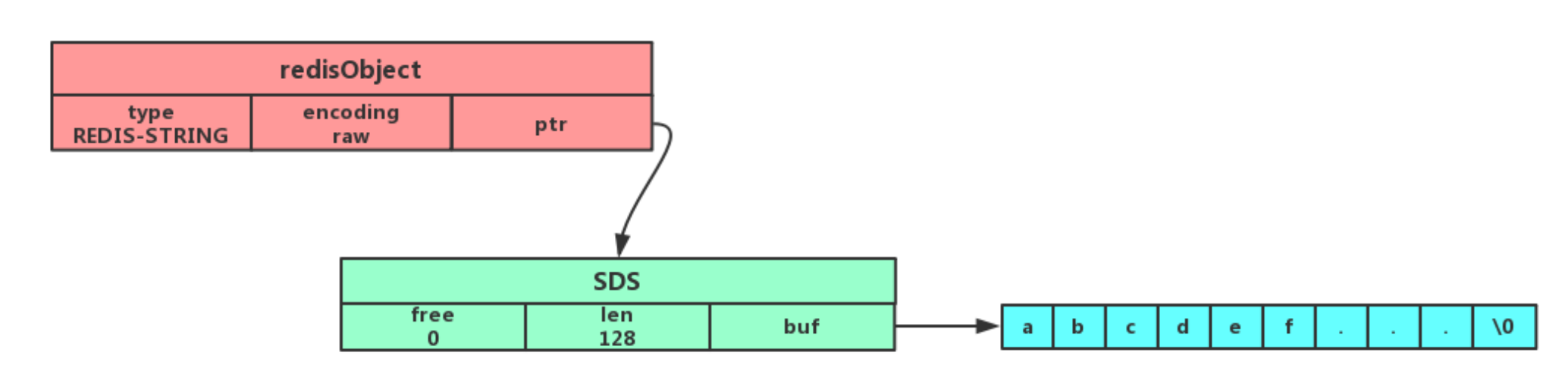
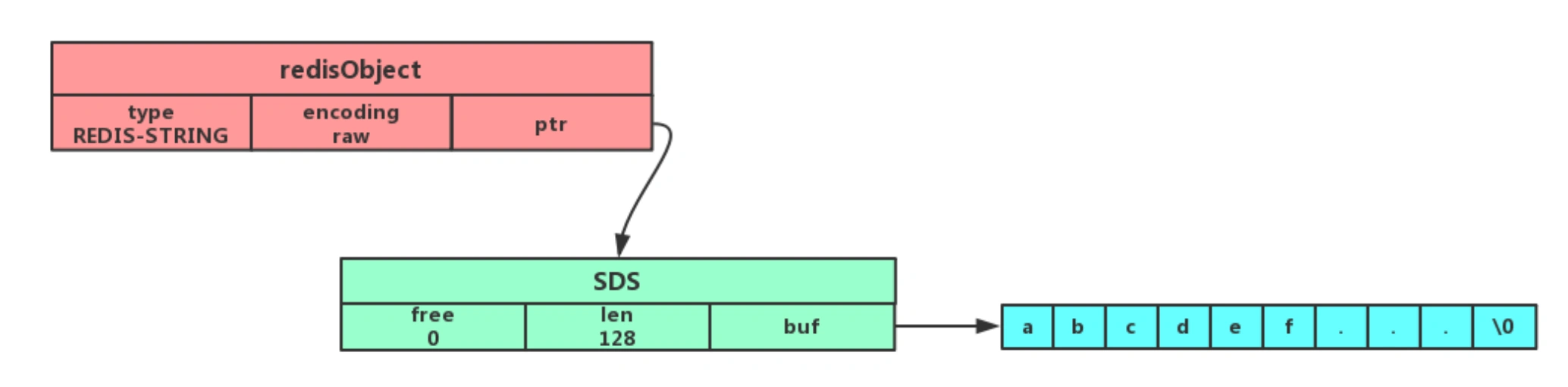
注意,embstr 编码和 raw 编码的边界在 redis 不同版本中是不一样的:
- redis 2.+ 是 32 字节
- redis 3.0-4.0 是 39 字节
- redis 5.0 是 44 字节
可以看到 embstr和 raw编码都会使用 SDS来保存值,但不同之处在于 embstr会通过一次内存分配函数来分配一块连续的内存空间来保存 redisObject和 SDS,而 raw编码会通过调用两次内存分配函数来分别分配两块空间来保存 redisObject和 SDS。Redis这样做会有很多好处:
embstr编码将创建字符串对象所需的内存分配次数从raw编码的两次降低为一次;- 释放
embstr编码的字符串对象同样只需要调用一次内存释放函数; - 因为
embstr编码的字符串对象的所有数据都保存在一块连续的内存里面可以更好的利用 CPU 缓存提升性能。
但是 embstr 也有缺点的:
- 如果字符串的长度增加需要重新分配内存时,整个redisObject和sds都需要重新分配空间,所以 embstr编码的字符串对象实际上是只读的 ,redis没有为embstr编码的字符串对象编写任何相应的修改程序。当我们对embstr编码的字符串对象执行任何修改命令(例如append)时,程序会先将对象的编码从embstr转换成raw,然后再执行修改命令。
常用指令
set
127.0.0.1:6379> set k1 hello
OK
get
127.0.0.1:6379> get k2 # 不存在为null
(nil)
127.0.0.1:6379> get k1
"hello"
set key value nx
127.0.0.1:6379> set k1 hello1 nx # nx是如果已存在则不能修改,可以用于分布式事务
(nil)
set key value XX
127.0.0.1:6379> get k2
(nil)
127.0.0.1:6379> set k2 sasasa XX # XX是如果之前为nil则不能修改
(nil)
append
127.0.0.1:6379> append k1 world # 追加
(integer) 10
127.0.0.1:6379> get k1
"helloworld"
type && Object encoding
127.0.0.1:6379> type k1 # 查看value值的类型是什么
string
127.0.0.1:6379> set k2 12
OK
127.0.0.1:6379> type k2
string
127.0.0.1:6379> Object encoding k2
"int"
127.0.0.1:6379> get k1
"helloworld"
127.0.0.1:6379> append k1 12 # 后面新增
(integer) 12
127.0.0.1:6379> object encoding k1 # 发现改变了
"raw"
127.0.0.1:6379> set k3 12 # 查看int类型的长度
OK
127.0.0.1:6379> object encoding k3
"int"
127.0.0.1:6379> strlen k3
(integer) 2
127.0.0.1:6379> set k4 99 # 继续测试int类型的长度
OK
127.0.0.1:6379> object encoding k4
"int"
127.0.0.1:6379> append k4 99
(integer) 4
127.0.0.1:6379> object encoding k4
"raw"
127.0.0.1:6379> incr k4
(integer) 10000
127.0.0.1:6379> object encoding k4
"int"
127.0.0.1:6379> strlen k4
(integer) 5
127.0.0.1:6379> set k6 你 # 测试汉字的长度,结果是3位,因为连接的机器用的是UTF-8的编码格式,如果是GBK,结果就会是两位
OK
127.0.0.1:6379> object encoding k6
"embstr"
127.0.0.1:6379> strlen k6
(integer) 3
# 结论:因为redis拿的是字节流,所以虽然有些类型是int,但是并不会按照字符编码的格式比如按int类型是4字节去取,而且统一的string。为了保证二进制安全。
# 如果以redis-cli --raw来进入redis的话,就会自动按照现在机器的编码格式来进行展示get key得到的结果,否则显示的就是十六进制码。如果之前utf-8进行set的key,在另一种编码下get得到的就是十六进制(直接以redis-cli进入redis)或者乱码(以redis-cli --raw进入redis).
# 总之结论就是redis是二进制安全的。redis是没有数据类型的概念,所以要在服务的定好编码格式。
# redis操作是原子的,如果有一个命令失败了,那么一行命令全部失败。比如msetnx k1 value1 ke value2,如果k1之前存在,那么k2也会同时失败
exists
# 判断某个 key 是否存在
> EXISTS k1
(integer) 1
strlen
# 返回 key 所储存的字符串值的长度
> STRLEN name
(integer) 3
del
# 删除某个 key 对应的值
> DEL name
(integer) 1
mset
# 批量设置 key-value 类型的值
> MSET key1 value1 key2 value2
OK
mget
# 批量获取多个 key 对应的 value
> MGET key1 key2
1) "value1"
2) "value2"
incr
# 设置 key-value 类型的值
> SET number 0
OK
# 将 key 中储存的数字值增一
> INCR number
(integer) 1
incrby
# 将key中存储的数字值加 10
> INCRBY number 10
(integer) 11
decr
# 将 key 中储存的数字值减一
> DECR number
(integer) 10
decrby
# 将key中存储的数字值减 10
> DECRBY number 10
(integer) 0
expire
# 设置 key 在 60 秒后过期(该方法是针对已经存在的key设置过期时间)
> EXPIRE name 60
(integer) 1
ttl
# 查看数据还有多久过期
> TTL name
(integer) 51
set key value EX time
#设置 key-value 类型的值,并设置该key的过期时间为 60 秒
> SET key value EX 60
OK
> SETEX key 60 value
OK
setnx
# 不存在就插入(not exists)
>SETNX key value
(integer) 1
应用场景
缓存对象
使用 String 来缓存对象有两种方式:
直接缓存整个对象的 JSON,命令例子: SET user:1 ‘{“name”:“xiaolin”, “age”:18}’。
采用将 key 进行分离为 user:ID:属性,采用 MSET 存储,用 MGET 获取各属性值,命令例子: MSET user:1:name xiaolin user:1:age 18 user:2:name xiaomei user:2:age 20。
常规计数
因为 Redis 处理命令是单线程,所以执行命令的过程是原子的。因此 String 数据类型适合计数场景,比如计算访问次数、点赞、转发、库存数量等等。
比如计算文章的阅读量:
初始化文章的阅读量
SET aritcle:readcount:1001 0
OK
#阅读量+1
INCR aritcle:readcount:1001
(integer) 1
#阅读量+1
INCR aritcle:readcount:1001
(integer) 2
#阅读量+1
INCR aritcle:readcount:1001
(integer) 3获取对应文章的阅读量
GET aritcle:readcount:1001
“3”
分布式锁
SET 命令有个 NX 参数可以实现「key不存在才插入」,可以用它来实现分布式锁:
如果 key 不存在,则显示插入成功,可以用来表示加锁成功;
如果 key 存在,则会显示插入失败,可以用来表示加锁失败。
一般而言,还会对分布式锁加上过期时间,分布式锁的命令如下:
SET lock_key unique_value NX PX 10000
可以看到,解锁是有两个操作,这时就需要 Lua 脚本来保证解锁的原子性,因为 Redis 在执行 Lua 脚本时,可以以原子性的方式执行,保证了锁释放操作的原子性。
// 释放锁时,先比较 unique_value 是否相等,避免锁的误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
共享 Session 信息
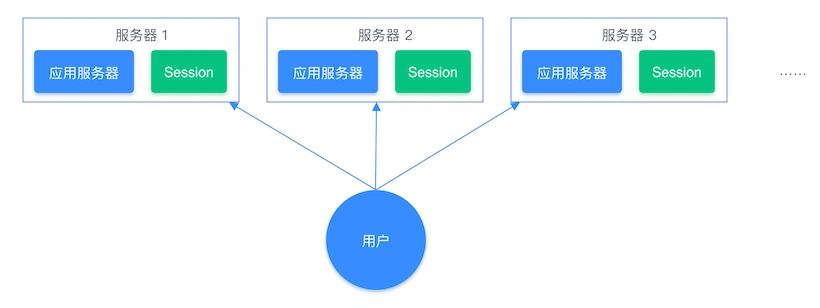
通常我们在开发后台管理系统时,会使用 Session 来保存用户的会话(登录)状态,这些 Session 信息会被保存在服务器端,但这只适用于单系统应用,如果是分布式系统此模式将不再适用。
例如用户一的 Session 信息被存储在服务器一,但第二次访问时用户一被分配到服务器二,这个时候服务器并没有用户一的 Session 信息,就会出现需要重复登录的问题,问题在于分布式系统每次会把请求随机分配到不同的服务器。
分布式系统单独存储 Session 流程图:
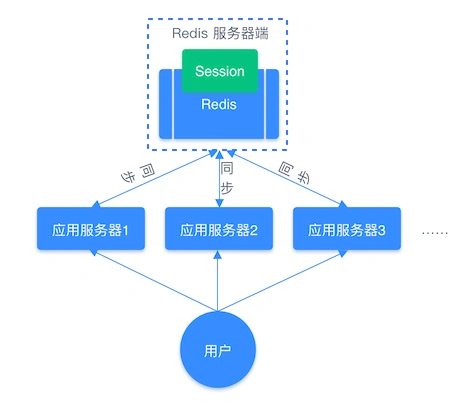
因此,我们需要借助 Redis 对这些 Session 信息进行统一的存储和管理,这样无论请求发送到那台服务器,服务器都会去同一个 Redis 获取相关的 Session 信息,这样就解决了分布式系统下 Session 存储的问题。
分布式系统使用同一个 Redis 存储 Session 流程图:
list
介绍
List 列表是简单的字符串列表, 按照插入顺序排序 ,可以从头部或尾部向 List 列表添加元素。
列表的最大长度为 2^32 - 1,也即每个列表支持超过 40 亿个元素。
内部实现
List 类型的底层数据结构是由双向链表或压缩列表实现的:
- 如果列表的元素个数小于
512个(默认值,可由list-max-ziplist-entries配置),列表每个元素的值都小于64字节(默认值,可由list-max-ziplist-value配置),Redis 会使用压缩列表作为 List 类型的底层数据结构; - 如果列表的元素不满足上面的条件,Redis 会使用双向链表作为 List 类型的底层数据结构;
但是 在 Redis 3.2 版本之后,List 数据类型底层数据结构就只由 quicklist 实现了,替代了双向链表和压缩列表 。
常用命令
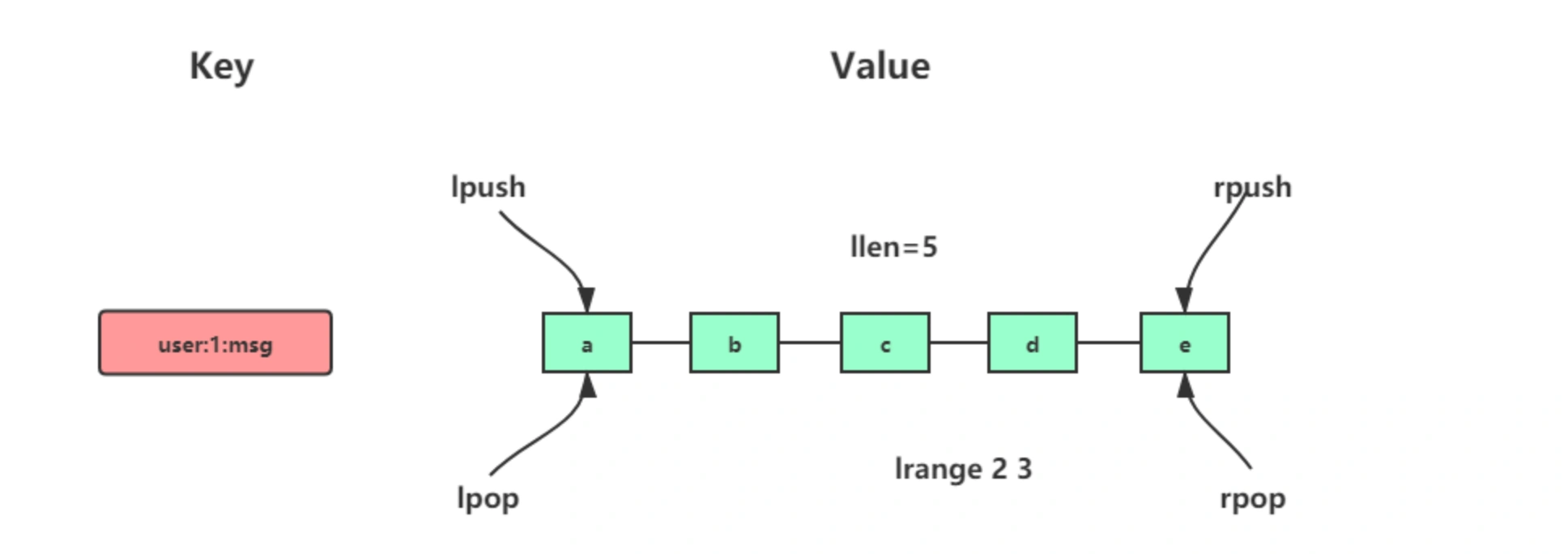
所有的list命令都是l或者R开头的,如果是b开头的则是表示阻塞,l指的是从左边进(倒序),R指的是从右边进(顺序),头插法和尾插法的区别。
# 1,将一个或多个值插入到列表头部
lpush key value1 value2 .....
# 2.将一个值插入到已存在的列表头部
lpushx key value
# 3,将一个或多个值插入到列表尾部
rpush key value1 value2 .....
# 4.将一个值插入到已存在的列表尾部
rpushx key value
# 5.获取指定范围list的内容[start,end]
lrange key start end
lrange key 0 -1 是指全部显示
# 6.移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止
blpop key
# 7.移出并获取列表的第一个元素
lpop key
# 8.移除列表的最后一个元素,返回值为移除的元素
rpop key
# 9.通过索引获取列表中的元素
lindex key index
# 10.获取列表的长度
llen key
# 11.移除列表元素,count如果是正数,那么就从前往后移除,如果是负数,则是从后往前移除
lrem key count(表示移除几个) value
# 12.通过索引设置列表元素的值(当想删除index的值时,可以设置index上特有的内容,在lrem移除这个特殊的value)
lset key index value
# 13.对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除,保留[start,stop],如果是[0,-1],那么啥也没删,因为保留了所有,如果要删除全部,那么就[1,0],只要保证strat大于end就行
ltrim key start stop
# 14.在列表的元素前或者后插入元素
linsert key before|after pivot(列表中的value) value(要插入的value)
应用场景
消息队列
消息队列在存取消息时,必须要满足三个需求,分别是 消息保序、处理重复的消息和保证消息可靠性 。
Redis 的 List 和 Stream 两种数据类型,就可以满足消息队列的这三个需求。我们先来了解下基于 List 的消息队列实现方法,后面在介绍 Stream 数据类型时候,在详细说说 Stream。
1、如何满足消息保序需求?
List 本身就是按先进先出的顺序对数据进行存取的,所以,如果使用 List 作为消息队列保存消息的话,就已经能满足消息保序的需求了。
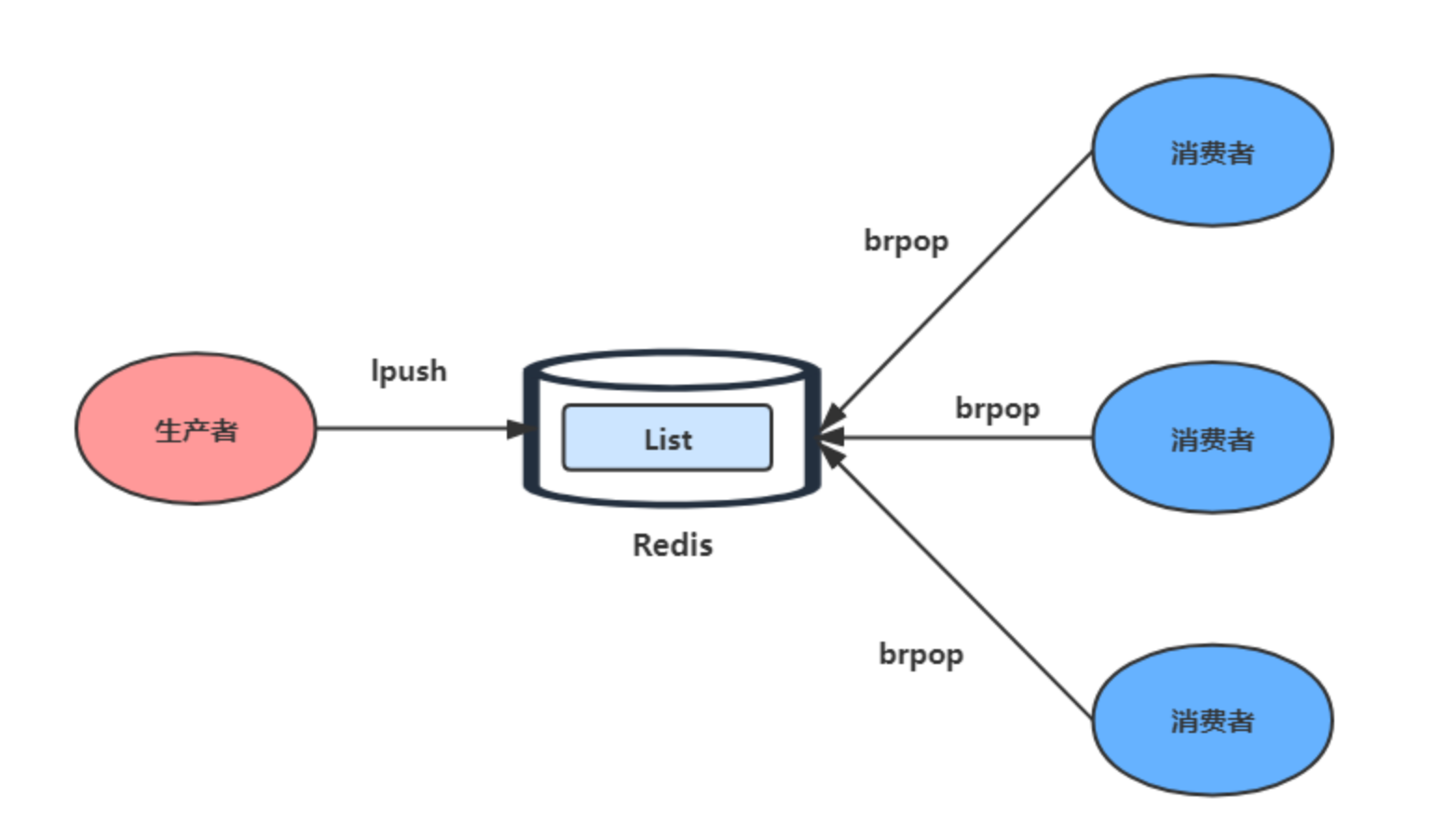
List 可以使用 LPUSH + RPOP (或者反过来,RPUSH+LPOP)命令实现消息队列。

- 生产者使用
LPUSH key value[value...]将消息插入到队列的头部,如果 key 不存在则会创建一个空的队列再插入消息。 - 消费者使用
RPOP key依次读取队列的消息,先进先出。
不过,在消费者读取数据时,有一个潜在的性能风险点。
在生产者往 List 中写入数据时,List 并不会主动地通知消费者有新消息写入,如果消费者想要及时处理消息,就需要在程序中不停地调用 RPOP 命令(比如使用一个while(1)循环)。如果有新消息写入,RPOP命令就会返回结果,否则,RPOP命令返回空值,再继续循环。
所以,即使没有新消息写入List,消费者也要不停地调用 RPOP 命令,这就会导致消费者程序的 CPU 一直消耗在执行 RPOP 命令上,带来不必要的性能损失。
为了解决这个问题,Redis提供了 BRPOP 命令。 BRPOP命令也称为阻塞式读取,客户端在没有读到队列数据时,自动阻塞,直到有新的数据写入队列,再开始读取新数据 。和消费者程序自己不停地调用RPOP命令相比,这种方式能节省CPU开销。
2、如何处理重复的消息?
消费者要实现重复消息的判断,需要 2 个方面的要求:
- 每个消息都有一个全局的 ID。
- 消费者要记录已经处理过的消息的 ID。当收到一条消息后,消费者程序就可以对比收到的消息 ID 和记录的已处理过的消息 ID,来判断当前收到的消息有没有经过处理。如果已经处理过,那么,消费者程序就不再进行处理了。
但是 List 并不会为每个消息生成 ID 号,所以我们需要自行为每个消息生成一个全局唯一ID ,生成之后,我们在用 LPUSH 命令把消息插入 List 时,需要在消息中包含这个全局唯一 ID。
例如,我们执行以下命令,就把一条全局 ID 为 111000102、库存量为 99 的消息插入了消息队列:
> LPUSH mq "111000102:stock:99"
(integer) 1
3、如何保证消息可靠性?
当消费者程序从 List 中读取一条消息后,List 就不会再留存这条消息了。所以,如果消费者程序在处理消息的过程出现了故障或宕机,就会导致消息没有处理完成,那么,消费者程序再次启动后,就没法再次从 List 中读取消息了。
为了留存消息,List 类型提供了 BRPOPLPUSH 命令,这个命令的 作用是让消费者程序从一个 List 中读取消息,同时,Redis 会把这个消息再插入到另一个 List(可以叫作备份 List)留存 。
这样一来,如果消费者程序读了消息但没能正常处理,等它重启后,就可以从备份 List 中重新读取消息并进行处理了。
好了,到这里可以知道基于 List 类型的消息队列,满足消息队列的三大需求(消息保序、处理重复的消息和保证消息可靠性)。
- 消息保序:使用 LPUSH + RPOP;
- 阻塞读取:使用 BRPOP;
- 重复消息处理:生产者自行实现全局唯一 ID;
- 消息的可靠性:使用 BRPOPLPUSH
List 作为消息队列有什么缺陷?
List 不支持多个消费者消费同一条消息 ,因为一旦消费者拉取一条消息后,这条消息就从 List 中删除了,无法被其它消费者再次消费。
要实现一条消息可以被多个消费者消费,那么就要将多个消费者组成一个消费组,使得多个消费者可以消费同一条消息,但是 List 类型并不支持消费组的实现 。
这就要说起 Redis 从 5.0 版本开始提供的 Stream 数据类型了,Stream 同样能够满足消息队列的三大需求,而且它还支持「消费组」形式的消息读取。
阻塞队列
blpop key timeout(阻塞时间,如果是0则一直阻塞,除非有数据进入key,则会立即弹出)
实现简单阻塞队列:
hash
介绍
实际就是key-(key-value)类型的.应用场景:各种点赞、收藏、详情页。因为有自增和增加且是key-value。
内部实现
Hash 类型的底层数据结构是由压缩列表或哈希表实现的:
- 如果哈希类型元素个数小于
512个(默认值,可由hash-max-ziplist-entries配置),所有值小于64字节(默认值,可由hash-max-ziplist-value配置)的话,Redis 会使用压缩列表作为 Hash 类型的底层数据结构; - 如果哈希类型元素不满足上面条件,Redis 会使用哈希表作为 Hash 类型的 底层数据结构。
在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了 。
常用命令
Redis Hash 是一个string类型的field(字段)和value(值)的映射表,hash特别适合存储对象
# 1.将哈希表 key 中的字段 field 的值设为 value
hset key field value
# 2.同时将多个 field-value (域-值)对设置到哈希表 key 中
hmset key field1 value1 field2 value2 ...
# 3.获取存储在哈希表中指定字段的值
hget key field
# 4.获取所有给定字段的值
hget key field1 field2 ...
# 5.获取在哈希表中指定 key 的所有字段和值
hgetall key
# 6.获取所有哈希表中的字段
hkeys key
# 7.获取哈希表中所有值
hvals key
# 8.删除一个或多个哈希表字段
hdel key field1 field2 ....
# 9.获取哈希表中字段的数量
hlen key
# 10.查看哈希表 key 中,指定的字段是否存在
hexists key field
# 11.只有在字段 field 不存在时,设置哈希表字段的值
hsetnx key field value
# 12.为哈希表 key 中的指定字段的整数值加上增量 increment
hincrby key field increment
# 13.为哈希表 key 中的指定字段的浮点数值加上增量 increment
hincrbyfloat key field increment
# 14.迭代哈希表中的键值对
hscan key cursor [MATCH pattern] [COUNT count]
cursor - 游标。
pattern - 匹配的模式。
count - 指定从数据集里返回多少元素,默认值为 10 。
实例
127.0.0.1:6379> set k1::name 'hello world'
OK
127.0.0.1:6379> set k1::age 12
OK
127.0.0.1:6379> get k1
(nil)
127.0.0.1:6379> get k1::age
"12"
127.0.0.1:6379> keys k1*
1) "k1::name"
2) "k1::age"
127.0.0.1:6379> hset zhang name 12
(integer) 1
127.0.0.1:6379> hset zhang age 14
(integer) 1
127.0.0.1:6379> hget zhang name
"12"
127.0.0.1:6379> hmget zhang name age
1) "12"
2) "14"
127.0.0.1:6379> hgetall zhang
1) "name"
2) "12"
3) "age"
4) "14"
应用场景
1.缓存对象
Hash 类型的 (key,field, value) 的结构与对象的(对象id, 属性, 值)的结构相似,也可以用来存储对象。
在介绍 String 类型的应用场景时有所介绍,String + Json也是存储对象的一种方式,那么存储对象时,到底用 String + json 还是用 Hash 呢?
一般对象用 String + Json 存储,对象中某些频繁变化的属性可以考虑抽出来用 Hash 类型存储。
2.购物车
以用户 id 为 key,商品 id 为 field,商品数量为 value,恰好构成了购物车的3个要素,如下图所示。
涉及的命令如下:
- 添加商品:
HSET cart:{用户id} {商品id} 1 - 添加数量:
HINCRBY cart:{用户id} {商品id} 1 - 商品总数:
HLEN cart:{用户id} - 删除商品:
HDEL cart:{用户id} {商品id} - 获取购物车所有商品:
HGETALL cart:{用户id}
当前仅仅是将商品ID存储到了Redis 中,在回显商品具体信息的时候,还需要拿着商品 id 查询一次数据库,获取完整的商品的信息。
set
介绍
无序且不能有重复数据。
一个集合最多可以存储 2^32-1 个元素。概念和数学中个的集合基本类似,可以交集,并集,差集等等,所以 Set 类型除了支持集合内的增删改查,同时还支持多个集合取交集、并集、差集。
Set 类型和 List 类型的区别如下:
- List 可以存储重复元素,Set 只能存储非重复元素;
- List 是按照元素的先后顺序存储元素的,而 Set 则是无序方式存储元素的。
常用命令
# 1.向集合添加一个或多个成员,成员是无序的
sadd key value1 value2 ....
# 2.获取集合的成员数
scard key
# 3.返回集合中的所有成员
smembers key
# 4.随机移除并返回集合中的一个随机元素
spop key
# 5.判断 member 元素是否是集合 key 的成员
sismember key member
# 6.返回第一个集合与其他集合之间的差异
sdiff key1 key2 .....
# 7.返回给定所有集合的差集并存储在 destination 中
sdiffstore destination key1 key2....
# 8.返回给定所有集合的交集
sinter key1 key2 ...
# 9.返回给定所有集合的交集并存储在 destination 中
sinterstore destination key1 key2
# 10.将 member 元素从 source 集合移动到 destination 集合
smove source destination member
# 11.返回集合中一个或多个随机数,如果count为正数,不能超过总数量,如果为负数,则可以取出带重复的成员,并且满足count的数量
srandmember key [count]
# 12.移除集合中一个或多个成员
srem key member1 member2 ....
# 13.返回所有给定集合的并集
sunion key1 key2 ...
# 14.所有给定集合的并集存储在 destination 集合中
sunionstore destination key1 key2 ....oneNet
应用场景
集合的主要几个特性,无序、不可重复、支持并交差等操作。
因此 Set 类型比较适合用来数据去重和保障数据的唯一性,还可以用来统计多个集合的交集、错集和并集等,当我们存储的数据是无序并且需要去重的情况下,比较适合使用集合类型进行存储。
但是要提醒你一下,这里有一个潜在的风险。 Set 的差集、并集和交集的计算复杂度较高,在数据量较大的情况下,如果直接执行这些计算,会导致 Redis 实例阻塞 。
在主从集群中,为了避免主库因为 Set 做聚合计算(交集、差集、并集)时导致主库被阻塞,我们可以选择一个从库完成聚合统计,或者把数据返回给客户端,由客户端来完成聚合统计。
1.点赞
Set 类型可以保证一个用户只能点一个赞,这里举例子一个场景,key 是文章id,value 是用户id。
uid:1 、uid:2、uid:3 三个用户分别对 article:1 文章点赞了。
uid:1 用户对文章 article:1 点赞
SADD article:1 uid:1
(integer) 1
uid:2 用户对文章 article:1 点赞
SADD article:1 uid:2
(integer) 1
uid:3 用户对文章 article:1 点赞
SADD article:1 uid:3
(integer) 1
uid:1 取消了对 article:1 文章点赞。
SREM article:1 uid:1
(integer) 1
获取 article:1 文章所有点赞用户 :
> SMEMBERS article:1 1) "uid:3" 2) "uid:2"
获取 article:1 文章的点赞用户数量:
SCARD article:1
(integer) 2
判断用户 uid:1 是否对文章 article:1 点赞了:
SISMEMBER article:1 uid:1
(integer) 0 # 返回0说明没点赞,返回1则说明点赞了
2.共同关注
Set 类型支持交集运算,所以可以用来计算共同关注的好友、公众号等。
key 可以是用户id,value 则是已关注的公众号的id。
uid:1 用户关注公众号 id 为 5、6、7、8、9,uid:2 用户关注公众号 id 为 7、8、9、10、11。
# uid:1 用户关注公众号 id 为 5、6、7、8、9 > SADD uid:1 5 6 7 8 9 (integer) 5 # uid:2 用户关注公众号 id 为 7、8、9、10、11 > SADD uid:2 7 8 9 10 11 (integer) 5
uid:1 和 uid:2 共同关注的公众号:
# 获取共同关注 > SINTER uid:1 uid:2 1) "7" 2) "8" 3) "9"
给 uid:2 推荐 uid:1 关注的公众号:
> SDIFF uid:1 uid:2 1) "5" 2) "6"
验证某个公众号是否同时被 uid:1 或 uid:2 关注:
> SISMEMBER uid:1 5
(integer) 1 # 返回0,说明关注了
> SISMEMBER uid:2 5
(integer) 0 # 返回0,说明没关注
3.抽奖活动
存储某活动中中奖的用户名 ,Set 类型因为有去重功能,可以保证同一个用户不会中奖两次。
key为抽奖活动名,value为员工名称,把所有员工名称放入抽奖箱 :
>SADD lucky Tom Jerry John Sean Marry Lindy Sary Mark
(integer) 5
如果允许重复中奖,可以使用 SRANDMEMBER 命令。
# 抽取 1 个一等奖:
> SRANDMEMBER lucky 1
1) "Tom"
# 抽取 2 个二等奖:
> SRANDMEMBER lucky 2
1) "Mark"
2) "Jerry"
# 抽取 3 个三等奖:
> SRANDMEMBER lucky 3
1) "Sary"
2) "Tom"
3) "Jerry"
如果不允许重复中奖,可以使用 SPOP 命令。
# 抽取一等奖1个
> SPOP lucky 1
1) "Sary"
# 抽取二等奖2个
> SPOP lucky 2
1) "Jerry"
2) "Mark"
# 抽取三等奖3个
> SPOP lucky 3
1) "John"
2) "Sean"
3) "Lindy"
sorted set || Zset
介绍
Zset 类型(有序集合类型)相比于 Set 类型多了一个排序属性 score(分值),对于有序集合 ZSet 来说,每个存储元素相当于有两个值组成的,一个是有序结合的元素值,一个是排序值。
有序集合保留了集合不能有重复成员的特性(分值可以重复),但不同的是,有序集合中的元素可以排序。
内部实现
Zset 类型的底层数据结构是由压缩列表或跳表实现的:
- 如果有序集合的元素个数小于
128个,并且每个元素的值小于64字节时,Redis 会使用压缩列表作为 Zset 类型的底层数据结构; - 如果有序集合的元素不满足上面的条件,Redis 会使用跳表作为 Zset 类型的底层数据结构;
在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了。
常用命令
Zset 运算操作(相比于 Set 类型,ZSet 类型没有支持差集运算,只有并集和交集):
有序集合,需要有排序的维度(分值)
物理内存是左小右大顺序存储
# 1.向有序集合添加一个或多个成员,或者更新已存在成员的分数
zadd key score1 member1 score2 member2 ...
# 2.获取有序集合的成员数
zcard key
# 3.计算在有序集合中指定区间分数的成员数
zcount min max (正无穷是+inf 负无穷是-inf)
# 4.通过索引区间返回有序集合指定区间内的成员
zrange key start stop [withscores] (zrange key 0 -1 代表的是返回全部成员)
# 5.通过分数返回有序集合指定区间内的成员,withscores是否带上分数,(这里的min和max是指大于等于)
zrangebyscore key min max [withscores] [limit]
zrangebyscore key 6 9 # 大于等于6,小于等于9
zrangebyscore key (6 (9 # 大于6,小于9
zrangebyscore key -inf +inf # 大于等于负无穷,小于等于正无穷
zrangebyscore key -inf +inf withscores # 带上每个成员的分数
# 6.在有序集合中计算指定字典区间内成员数量
zlexcount key member1 member2
# 7.通过字典区间返回有序集合的成员
zrangebylex key member1 member2
# 8.返回有序集合中指定成员的索引
zrank key member
# 9.移除有序集合中的一个或多个成员
zrem key member1 member2 ...
# 10.移除有序集合中给定的字典区间的所有成员
zremrangebylex key minMember maxMember
# 11.移除有序集合中给定的排名区间(索引)的所有成员
zremrangebyrank key start stop
# 12.移除有序集合中给定的分数区间的所有成员
zremrangebyscore key minScore maxScore
# 13.返回有序集中指定区间内的成员,通过索引,分数从高到低,即倒叙排序
zrevrange key start stop [withscores]
# 14.返回有序集中指定分数区间内的成员,分数从高到低排序
zrevrangebyscore key maxscores minscores [withscores]
# 15.返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序
zrevrank key member (就是返回成员逆序排序后的排名)
# 16.返回有序集中,成员的分数值
zscore key member
# 17.有序集合中对指定成员的分数加上增量 increment
zincrby key increment member
# 18.计算给定的一个或多个有序集的交集并将结果集存储在新的有序集合 destination 中
zinterstore destination numkeys key1 key2 .... # numkeys是指key的个数,后面就必须接上这个数量的key
# 19.计算给定的一个或多个有序集的并集,并存储在新的 key 中
zunionstore destination numkeys key1 [key2 ...]
# 20.迭代有序集合中的元素(包括元素成员和元素分值)
zscan key cursor [MATCH pattern] [COUNT count]
实例
127.0.0.1:6379> zadd k 1 zhang 2 li 4 san # 存储
(integer) 3
127.0.0.1:6379> zcount k 1 2 # 统计分数在1到2之间的个数
(integer) 2
127.0.0.1:6379> zcard k # 展示一共有多少个数据
(integer) 3
127.0.0.1:6379> zrange k 0 -1 # 显示所有数据
1) "zhang"
2) "li"
3) "san"
127.0.0.1:6379> zrevrange k 0 -1 # 逆序显示所有数据
1) "san"
2) "li"
3) "zhang"
127.0.0.1:6379> zrange k 0 -1 withscores # 显示分数和所有的数据
1) "zhang"
2) "1"
3) "li"
4) "2"
5) "san"
6) "4"
# 查询并集
127.0.0.1:6379> zadd k 1 ping 2 xiang 3 li 4 orange
(integer) 4
127.0.0.1:6379> zadd k1 1 ping 2 xiang 3 boluo 4 liulian
(integer) 4
127.0.0.1:6379> zrange k 0 -1 withscores
1) "ping"
2) "1"
3) "xiang"
4) "2"
5) "li"
6) "3"
7) "orange"
8) "4"
127.0.0.1:6379> zrange k1 0 -1 withscores
1) "ping"
2) "1"
3) "xiang"
4) "2"
5) "boluo"
6) "3"
7) "liulian"
8) "4"
127.0.0.1:6379> zunionstore k2 2 k k1
(integer) 6
127.0.0.1:6379> zrange k2 0 -1 withscores # 并集相同的key的score会相加,然后在新集合中重新排序
1) "ping"
2) "2"
3) "boluo"
4) "3"
5) "li"
6) "3"
7) "liulian"
8) "4"
9) "orange"
10) "4"
11) "xiang"
12) "4"
sorted set排序是怎么实现的?
跳跃表:skip list set是链表 最底下一层是所有数据,倒数第二层是间接挑选底层数据复制。随机造层,平衡树
应用场景
Zset 类型(Sorted Set,有序集合) 可以根据元素的权重来排序,我们可以自己来决定每个元素的权重值。比如说,我们可以根据元素插入 Sorted Set 的时间确定权重值,先插入的元素权重小,后插入的元素权重大。
在面对需要展示最新列表、排行榜等场景时,如果数据更新频繁或者需要分页显示,可以优先考虑使用 Sorted Set。
1.排行榜
有序集合比较典型的使用场景就是排行榜。例如学生成绩的排名榜、游戏积分排行榜、视频播放排名、电商系统中商品的销量排名等。
我们以博文点赞排名为例,小林发表了五篇博文,分别获得赞为 200、40、100、50、150。
# arcticle:1 文章获得了200个赞
> ZADD user:xiaolin:ranking 200 arcticle:1
(integer) 1
# arcticle:2 文章获得了40个赞
> ZADD user:xiaolin:ranking 40 arcticle:2
(integer) 1
# arcticle:3 文章获得了100个赞
> ZADD user:xiaolin:ranking 100 arcticle:3
(integer) 1
# arcticle:4 文章获得了50个赞
> ZADD user:xiaolin:ranking 50 arcticle:4
(integer) 1
# arcticle:5 文章获得了150个赞
> ZADD user:xiaolin:ranking 150 arcticle:5
(integer) 1
文章 arcticle:4 新增一个赞,可以使用 ZINCRBY 命令(为有序集合key中元素member的分值加上increment):
> ZINCRBY user:xiaolin:ranking 1 arcticle:4
"51"
查看某篇文章的赞数,可以使用 ZSCORE 命令(返回有序集合key中元素个数):
> ZSCORE user:xiaolin:ranking arcticle:4
"50"
获取小林文章赞数最多的 3 篇文章,可以使用 ZREVRANGE 命令(倒序获取有序集合 key 从start下标到stop下标的元素):
# WITHSCORES 表示把 score 也显示出来
> ZREVRANGE user:xiaolin:ranking 0 2 WITHSCORES
1) "arcticle:1"
2) "200"
3) "arcticle:5"
4) "150"
5) "arcticle:3"
6) "100"
获取小林 100 赞到 200 赞的文章,可以使用 ZRANGEBYSCORE 命令(返回有序集合中指定分数区间内的成员,分数由低到高排序):
> ZRANGEBYSCORE user:xiaolin:ranking 100 200 WITHSCORES
1) "arcticle:3"
2) "100"
3) "arcticle:5"
4) "150"
5) "arcticle:1"
6) "200"
2.电话、姓名排序
使用有序集合的 ZRANGEBYLEX 或 ZREVRANGEBYLEX 可以帮助我们实现电话号码或姓名的排序,我们以 ZRANGEBYLEX (返回指定成员区间内的成员,按 key 正序排列,分数必须相同)为例。
注意:不要在分数不一致的 SortSet 集合中去使用 ZRANGEBYLEX和 ZREVRANGEBYLEX 指令,因为获取的结果会不准确。
1、电话排序
我们可以将电话号码存储到 SortSet 中,然后根据需要来获取号段:
> ZADD phone 0 13100111100 0 13110114300 0 13132110901
(integer) 3
> ZADD phone 0 13200111100 0 13210414300 0 13252110901
(integer) 3
> ZADD phone 0 13300111100 0 13310414300 0 13352110901
(integer) 3
获取所有号码:
> ZRANGEBYLEX phone - +
1) "13100111100"
2) "13110114300"
3) "13132110901"
4) "13200111100"
5) "13210414300"
6) "13252110901"
7) "13300111100"
8) "13310414300"
9) "13352110901"
获取 132 号段的号码:
> ZRANGEBYLEX phone [132 (133
1) "13200111100"
2) "13210414300"
3) "13252110901"
获取132、133号段的号码:
> ZRANGEBYLEX phone [132 (134
1) "13200111100"
2) "13210414300"
3) "13252110901"
4) "13300111100"
5) "13310414300"
6) "13352110901"
2、姓名排序
> zadd names 0 Toumas 0 Jake 0 Bluetuo 0 Gaodeng 0 Aimini 0 Aidehua
(integer) 6
获取所有人的名字:
> ZRANGEBYLEX names - +
1) "Aidehua"
2) "Aimini"
3) "Bluetuo"
4) "Gaodeng"
5) "Jake"
6) "Toumas"
获取名字中大写字母A开头的所有人:
> ZRANGEBYLEX names [A (B
1) "Aidehua"
2) "Aimini"
获取名字中大写字母 C 到 Z 的所有人:
> ZRANGEBYLEX names [C [Z
1) "Gaodeng"
2) "Jake"
3) "Toumas"
bitmap
介绍
Bitmap,即位图,是一串连续的二进制数组(0和1),可以通过偏移量(offset)定位元素。BitMap通过最小的单位bit来进行 0|1的设置,表示某个元素的值或者状态,时间复杂度为O(1)。
由于 bit 是计算机中最小的单位,使用它进行储存将非常节省空间,特别适合一些数据量大且使用 二值统计的场景 。
内部实现
Bitmap 本身是用 String 类型作为底层数据结构实现的一种统计二值状态的数据类型。
String 类型是会保存为二进制的字节数组,所以,Redis 就把字节数组的每个 bit 位利用起来,用来表示一个元素的二值状态,你可以把 Bitmap 看作是一个 bit 数组。
常用命令
基本操作
# 设置值,其中value只能是 0 和 1
SETBIT key offset value
# 获取值
GETBIT key offset
# 获取指定范围内值为 1 的个数
# start 和 end 以字节为单位
BITCOUNT key start end
运算操作
# BitMap间的运算
# operations 位移操作符,枚举值
AND 与运算 &
OR 或运算 |
XOR 异或 ^
NOT 取反 ~
# result 计算的结果,会存储在该key中
# key1 … keyn 参与运算的key,可以有多个,空格分割,not运算只能一个key
# 当 BITOP 处理不同长度的字符串时,较短的那个字符串所缺少的部分会被看作 0。返回值是保存到 destkey 的字符串的长度(以字节byte为单位),和输入 key 中最长的字符串长度相等。
BITOP [operations] [result] [key1] [keyn…]
# 返回指定key中第一次出现指定value(0/1)的位置
BITPOS [key] [value]
整合测试
# 其实也是属于string的
127.0.0.1:6379> help setbit
SETBIT key offset value
summary: Sets or clears the bit at offset in the string value stored at key
since: 2.2.0
group: string
# 案例1
127.0.0.1:6379> setbit k1 1 1 # 偏移量是1 ,也就是从左往右偏移一位0100 0000
(integer) 0
127.0.0.1:6379> object encoding k1
"raw"
127.0.0.1:6379> strlen k1
(integer) 1
127.0.0.1:6379> get k1
"@"
# 案例2
127.0.0.1:6379> setbit k2 0 1
(integer) 0
127.0.0.1:6379> get k2 # 偏移量是0,也就是1000 0000
"\x80"
# 案例3 strlen,统计bitmap的长度是按字节来
127.0.0.1:6379> get k1 # 这里是0100 0000
"@"
127.0.0.1:6379> setbit k1 7 1
(integer) 0
127.0.0.1:6379> get k1 # 到这里是0100 0001 ,也就是1+2^6=65,到ASCII码是A
"A"
127.0.0.1:6379> strlen k1 # 没超过8位,所以还是一位
(integer) 1
# 案例3
127.0.0.1:6379> setbit k1 9 1
(integer) 0
127.0.0.1:6379> strlen k1 # 到这里长度为2,因为是0100 0001 0100 0000,其中0100 0001是A,0100 0000是@
(integer) 2
127.0.0.1:6379> get k1
"A@"
# 案例4
127.0.0.1:6379> help bitpos # 查找指定bit出现的位置,以字节(也就是8位bit)为单位
BITPOS key bit [start] [end] # start和end是表示字节数,从第start个字节到第end个字节,从0开始计数
summary: Find first bit set or clear in a string
since: 2.8.7
group: string
127.0.0.1:6379> get k1 # 0000 0001
"\x01"
127.0.0.1:6379> bitpos k1 1 0 0 # 查找第1个字节中(因为start和end都是0,也就是第一个字节)第一次出现在整个bitmap二进制位的位置,是在第7位(从0开始)
(integer) 7
# 案例5,查找指定字节中出现的1的次数
127.0.0.1:6379> help bitcount
BITCOUNT key [start end]
summary: Count set bits in a string
since: 2.6.0
group: string
127.0.0.1:6379> get k1 # 01000001 01000000
"A@"
127.0.0.1:6379> bitcount k1 0 1 # 在第一个字节到第二个字节中,1出现了3次
(integer) 3
# 案例6,比较运算,and or not(非运算只能有一个key) xor(异或)
127.0.0.1:6379> help bitop
BITOP operation destkey key [key ...]
summary: Perform bitwise operations between strings
since: 2.6.0
group: string
127.0.0.1:6379> get k1 # 0100 0001
"A"
127.0.0.1:6379> get k2 # 0100 0010
"B"
127.0.0.1:6379> bitop and k3 k1 k2 # 将k1和k2作与操作,并将结果存放到k3中,与操作是同时为1才为1,否则为0,所以最后得出的结果是0100 0000
(integer) 1
127.0.0.1:6379> get k3 # k3的结果是0100 0000
"@"
127.0.0.1:6379> bitop or k4 k1 k2 # 进行或操作
(integer) 1
127.0.0.1:6379> get k4 # 0100 0011
"C"
127.0.0.1:6379> bitop not k5 k1 #进行非操作 0100 0001----> 1011 1110
(integer) 1
127.0.0.1:6379> get k5 #1011 1110--->b e
"\xbe"
127.0.0.1:6379> bitop xor k6 k1 k2 # 异或操作 0100 0001 和0100 0010---->0000 0011
(integer) 1
127.0.0.1:6379> get k6
"\x03"
setbit、bitcount、bitop、bitpos
ASCII码
[root@VM-4-2-centos ~]# man ascii
ASCII(7) Linux Programmer's Manual ASCII(7)
NAME
ascii - 在八进制,十进制,十六进制中的 ASCII 字符集编码
描述
ASCII 是美国对于信息交换的标准代码,它是7位码,许多8位码(比如 ISO 8859-1, Linux 的默认字符集)容纳 ASCII 作为它们的下半部分。对应的国际 ASSII 是 ISO 646。
下列的表格包含这 128 ASCII 字符.
注意 C 程序 '\X' 扩展(转义).
Oct Dec Hex Char Oct Dec Hex Char
──────────────────────────────────────────────────────────────────
000 0 00 NUL '\0' 100 64 40 @
001 1 01 SOH 101 65 41 A
002 2 02 STX 102 66 42 B
003 3 03 ETX 103 67 43 C
004 4 04 EOT 104 68 44 D
005 5 05 ENQ 105 69 45 E
006 6 06 ACK 106 70 46 F
007 7 07 BEL '\a' 107 71 47 G
010 8 08 BS '\b' 110 72 48 H
011 9 09 HT '\t' 111 73 49 I
012 10 0A LF '\n' 112 74 4A J
应用场景
1.统计用户登录天数,且窗口随机
极端情况下,一个字节是统计一天的打卡,如果这天打开了,设置为0000 0001,这样窗口随机获取的时候就是按字节来bitcount就可以了,一个人一年最大是365字节
一亿个人10年打卡的记录就是365G
127.0.0.1:6379> setbit zhang 7 1 # 设置第一天打卡
(integer) 0
127.0.0.1:6379> setbit zhang 15 1 # 设置第二天打卡
(integer) 0
127.0.0.1:6379> setbit zhang 2911 1 # 设置第364天打卡
(integer) 0
127.0.0.1:6379> setbit zhang 2919 1 # 设置第365天打卡
(integer) 0
127.0.0.1:6379> strlen zhang # 365字节
(integer) 365
127.0.0.1:6379> get zhang
"\x01\x01\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x01\x01"
127.0.0.1:6379> bitcount zhang -2 -1 # 统计一年最后两天打卡几次
(integer) 2
127.0.0.1:6379> getrange zhang -2 -1 # 获取最后两天的打卡情况
"\x01\x01"
如果不需要统计次数,实际上可以一天是1个bit,这样一个人一年才365bit,也就是45.7字节,取整是46字节
2.送礼物时,库存备货多少,假设有2亿用户
用户有僵尸用户、冷热用户/忠诚用户(活跃用户)。所以主要是统计活跃用户统计
这时候天数是key, 每个人映射bit的第几位,如果当天登录就设置为1,使用bitop的or运算,统计连续几天登录的人的个数
127.0.0.1:6379> setbit 20220619 1 1
(integer) 0
127.0.0.1:6379> setbit 20220619 3 1
(integer) 0
127.0.0.1:6379> setbit 20220619 7 1
(integer) 0
127.0.0.1:6379> setbit 20220620 1 1
(integer) 0
127.0.0.1:6379> setbit 20220620 2 1
(integer) 0
127.0.0.1:6379> bitop or destkey 20220619 20220620
(integer) 1
127.0.0.1:6379> get destkey
"q"
127.0.0.1:6379> bitcount destkey # 两天一共有4个人登录,去除掉重复登录的人的个数
(integer) 4
3.判断用户登录状态
Bitmap 提供了 GETBIT、SETBIT 操作,通过一个偏移值 offset 对 bit 数组的 offset 位置的 bit 位进行读写操作,需要注意的是 offset 从 0 开始。
只需要一个 key = login_status 表示存储用户登陆状态集合数据, 将用户 ID 作为 offset,在线就设置为 1,下线设置 0。通过 GETBIT判断对应的用户是否在线。 50000 万 用户只需要 6 MB 的空间。
假如我们要判断 ID = 10086 的用户的登陆情况:
第一步,执行以下指令,表示用户已登录。
SETBIT login_status 10086 1
第二步,检查该用户是否登陆,返回值 1 表示已登录。
GETBIT login_status 10086
第三步,登出,将 offset 对应的 value 设置成 0。
SETBIT login_status 10086 0
4.连续签到用户总数
如何统计出这连续 7 天连续打卡用户总数呢?
我们把每天的日期作为 Bitmap 的 key,userId 作为 offset,若是打卡则将 offset 位置的 bit 设置成 1。
key 对应的集合的每个 bit 位的数据则是一个用户在该日期的打卡记录。
一共有 7 个这样的 Bitmap,如果我们能对这 7 个 Bitmap 的对应的 bit 位做 『与』运算。同样的 UserID offset 都是一样的,当一个 userID 在 7 个 Bitmap 对应对应的 offset 位置的 bit = 1 就说明该用户 7 天连续打卡。
结果保存到一个新 Bitmap 中,我们再通过 BITCOUNT 统计 bit = 1 的个数便得到了连续打卡 3 天的用户总数了。
Redis 提供了 BITOP operation destkey key [key ...]这个指令用于对一个或者多个 key 的 Bitmap 进行位元操作。
opration可以是and、OR、NOT、XOR。当 BITOP 处理不同长度的字符串时,较短的那个字符串所缺少的部分会被看作0。空的key也被看作是包含0的字符串序列。
举个例子,比如将三个 bitmap 进行 AND 操作,并将结果保存到 destmap 中,接着对 destmap 执行 BITCOUNT 统计。
# 与操作
BITOP AND destmap bitmap:01 bitmap:02 bitmap:03
# 统计 bit 位 = 1 的个数
BITCOUNT destmap
即使一天产生一个亿的数据,Bitmap 占用的内存也不大,大约占 12 MB 的内存(10^8/8/1024/1024),7 天的 Bitmap 的内存开销约为 84 MB。同时我们最好给 Bitmap 设置过期时间,让 Redis 删除过期的打卡数据,节省内存。
HyperLogLog
介绍
Redis HyperLogLog 是 Redis 2.8.9 版本新增的数据类型,是一种用于「统计基数」的数据集合类型,基数统计就是指统计一个集合中不重复的元素个数。但要注意,HyperLogLog 是统计规则是基于概率完成的,不是非常准确,标准误算率是 0.81%。
所以,简单来说 HyperLogLog 提供不精确的去重计数 。
HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的内存空间总是固定的、并且是很小的。
在 Redis 里面, 每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数 ,和元素越多就越耗费内存的 Set 和 Hash 类型相比,HyperLogLog 就非常节省空间。
这什么概念?举个例子给大家对比一下。
用 Java 语言来说,一般 long 类型占用 8 字节,而 1 字节有 8 位,即:1 byte = 8 bit,即 long 数据类型最大可以表示的数是:2^63-1。对应上面的 2^64个数,假设此时有 2^63-1这么多个数,从 0 ~ 2^63-1,按照 long以及 1k = 1024 字节的规则来计算内存总数,就是:((2^63-1) * 8/1024)K,这是很庞大的一个数,存储空间远远超过 12K,而 HyperLogLog 却可以用 12K 就能统计完。
内部实现
涉及到很多数学运算
https://en.wikipedia.org/wiki/HyperLogLog
常用命令
HyperLogLog 命令很少,就三个。
# 添加指定元素到 HyperLogLog 中
PFADD key element [element ...]
# 返回给定 HyperLogLog 的基数估算值。
PFCOUNT key [key ...]
# 将多个 HyperLogLog 合并为一个 HyperLogLog
PFMERGE destkey sourcekey [sourcekey ...]
应用场景
百万级网页 UV 计数
Redis HyperLogLog 优势在于只需要花费 12 KB 内存,就可以计算接近 2^64 个元素的基数,和元素越多就越耗费内存的 Set 和 Hash 类型相比,HyperLogLog 就非常节省空间。
所以,非常适合统计百万级以上的网页 UV 的场景。
在统计 UV 时,你可以用 PFADD 命令(用于向 HyperLogLog 中添加新元素)把访问页面的每个用户都添加到 HyperLogLog 中。
PFADD page1:uv user1 user2 user3 user4 user5
接下来,就可以用 PFCOUNT 命令直接获得 page1 的 UV 值了,这个命令的作用就是返回 HyperLogLog 的统计结果。
PFCOUNT page1:uv
不过,有一点需要你注意一下,HyperLogLog 的统计规则是基于概率完成的,所以它给出的统计结果是有一定误差的,标准误算率是 0.81%。
这也就意味着,你使用 HyperLogLog 统计的 UV 是 100 万,但实际的 UV 可能是 101 万。虽然误差率不算大,但是,如果你需要精确统计结果的话,最好还是继续用 Set 或 Hash 类型。
GEO
介绍
Redis GEO 是 Redis 3.2 版本新增的数据类型,主要用于存储地理位置信息,并对存储的信息进行操作。
在日常生活中,我们越来越依赖搜索“附近的餐馆”、在打车软件上叫车,这些都离不开基于位置信息服务(Location-Based Service,LBS)的应用。LBS 应用访问的数据是和人或物关联的一组经纬度信息,而且要能查询相邻的经纬度范围,GEO 就非常适合应用在 LBS 服务的场景中。
内部实现
GEO 本身并没有设计新的底层数据结构,而是直接使用了 Sorted Set 集合类型。
GEO 类型使用 GeoHash 编码方法实现了经纬度到 Sorted Set 中元素权重分数的转换,这其中的两个关键机制就是「对二维地图做区间划分」和「对区间进行编码」。一组经纬度落在某个区间后,就用区间的编码值来表示,并把编码值作为 Sorted Set 元素的权重分数。
这样一来,我们就可以把经纬度保存到 Sorted Set 中,利用 Sorted Set 提供的“按权重进行有序范围查找”的特性,实现 LBS 服务中频繁使用的“搜索附近”的需求。
常用命令
# 存储指定的地理空间位置,可以将一个或多个经度(longitude)、纬度(latitude)、位置名称(member)添加到指定的 key 中。
GEOADD key longitude latitude member [longitude latitude member ...]
# 从给定的 key 里返回所有指定名称(member)的位置(经度和纬度),不存在的返回 nil。
GEOPOS key member [member ...]
# 返回两个给定位置之间的距离。
GEODIST key member1 member2 [m|km|ft|mi]
# 根据用户给定的经纬度坐标来获取指定范围内的地理位置集合。
GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]
应用场景
滴滴叫车
这里以滴滴叫车的场景为例,介绍下具体如何使用 GEO 命令:GEOADD 和 GEORADIUS 这两个命令。
假设车辆 ID 是 33,经纬度位置是(116.034579,39.030452),我们可以用一个 GEO 集合保存所有车辆的经纬度,集合 key 是 cars:locations。
执行下面的这个命令,就可以把 ID 号为 33 的车辆的当前经纬度位置存入 GEO 集合中:
GEOADD cars:locations 116.034579 39.030452 33
当用户想要寻找自己附近的网约车时,LBS 应用就可以使用 GEORADIUS 命令。
例如,LBS 应用执行下面的命令时,Redis 会根据输入的用户的经纬度信息(116.054579,39.030452 ),查找以这个经纬度为中心的 5 公里内的车辆信息,并返回给 LBS 应用。
GEORADIUS cars:locations 116.054579 39.030452 5 km ASC COUNT 10
Stream
介绍
Redis Stream 是 Redis 5.0 版本新增加的数据类型,Redis 专门为消息队列设计的数据类型。
在 Redis 5.0 Stream 没出来之前,消息队列的实现方式都有着各自的缺陷,例如:
- 发布订阅模式,不能持久化也就无法可靠的保存消息,并且对于离线重连的客户端不能读取历史消息的缺陷;
- List 实现消息队列的方式不能重复消费,一个消息消费完就会被删除,而且生产者需要自行实现全局唯一 ID。
基于以上问题,Redis 5.0 便推出了 Stream 类型也是此版本最重要的功能,用于完美地实现消息队列,它支持消息的持久化、支持自动生成全局唯一 ID、支持 ack 确认消息的模式、支持消费组模式等,让消息队列更加的稳定和可靠
常用命令
Stream 消息队列操作命令:
- XADD:插入消息,保证有序,可以自动生成全局唯一 ID;
- XLEN :查询消息长度;
- XREAD:用于读取消息,可以按 ID 读取数据;
- XDEL : 根据消息 ID 删除消息;
- DEL :删除整个 Stream;
- XRANGE :读取区间消息
- XREADGROUP:按消费组形式读取消息;
- XPENDING 和 XACK:
- XPENDING 命令可以用来查询每个消费组内所有消费者「已读取、但尚未确认」的消息;
- XACK 命令用于向消息队列确认消息处理已完成;
应用场景
1.消息队列
生产者通过 XADD 命令插入一条消息:
# * 表示让 Redis 为插入的数据自动生成一个全局唯一的 ID
# 往名称为 mymq 的消息队列中插入一条消息,消息的键是 name,值是 xiaolin
> XADD mymq * name xiaolin
"1654254953808-0"
插入成功后会返回全局唯一的 ID:“1654254953808-0”。消息的全局唯一 ID 由两部分组成:
- 第一部分“1654254953808”是数据插入时,以毫秒为单位计算的当前服务器时间;
- 第二部分表示插入消息在当前毫秒内的消息序号,这是从 0 开始编号的。例如,“1654254953808-0”就表示在“1654254953808”毫秒内的第 1 条消息。
消费者通过 XREAD 命令从消息队列中读取消息时,可以指定一个消息 ID,并从这个消息 ID 的下一条消息开始进行读取(注意是输入消息 ID 的下一条信息开始读取,不是查询输入ID的消息)。
# 从 ID 号为 1654254953807-0 的消息开始,读取后续的所有消息(示例中一共 1 条)。
> XREAD STREAMS mymq 1654254953807-0
1) 1) "mymq"
2) 1) 1) "1654254953808-0"
2) 1) "name"
2) "xiaolin"
如果 想要实现阻塞读(当没有数据时,阻塞住),可以调用 XRAED 时设定 BLOCK 配置项 ,实现类似于 BRPOP 的阻塞读取操作。
比如,下面这命令,设置了 BLOCK 10000 的配置项,10000 的单位是毫秒,表明 XREAD 在读取最新消息时,如果没有消息到来,XREAD 将阻塞 10000 毫秒(即 10 秒),然后再返回。
# 命令最后的“$”符号表示读取最新的消息
> XREAD BLOCK 10000 STREAMS mymq $
(nil)
(10.00s)
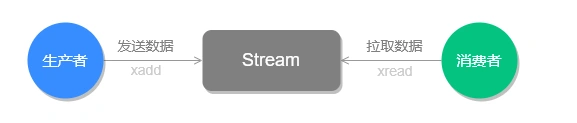
Stream 的基础方法,使用 xadd 存入消息和 xread 循环阻塞读取消息的方式可以实现简易版的消息队列,交互流程如下图所示:

前面介绍的这些操作 List 也支持的,接下来看看 Stream 特有的功能。
Stream 可以以使用 XGROUP 创建消费组 ,创建消费组之后,Stream 可以使用 XREADGROUP 命令让消费组内的消费者读取消息。
创建两个消费组,这两个消费组消费的消息队列是 mymq,都指定从第一条消息开始读取:
# 创建一个名为 group1 的消费组,0-0 表示从第一条消息开始读取。
> XGROUP CREATE mymq group1 0-0
OK
# 创建一个名为 group2 的消费组,0-0 表示从第一条消息开始读取。
> XGROUP CREATE mymq group2 0-0
OK
消费组 group1 内的消费者 consumer1 从 mymq 消息队列中读取所有消息的命令如下:
# 命令最后的参数“>”,表示从第一条尚未被消费的消息开始读取。
> XREADGROUP GROUP group1 consumer1 STREAMS mymq >
1) 1) "mymq"
2) 1) 1) "1654254953808-0"
2) 1) "name"
2) "xiaolin"
消息队列中的消息一旦被消费组里的一个消费者读取了,就不能再被该消费组内的其他消费者读取了,即同一个消费组里的消费者不能消费同一条消息 。
比如说,我们执行完刚才的 XREADGROUP 命令后,再执行一次同样的命令,此时读到的就是空值了:
> XREADGROUP GROUP group1 consumer1 STREAMS mymq >
(nil)
但是, 不同消费组的消费者可以消费同一条消息(但是有前提条件,创建消息组的时候,不同消费组指定了相同位置开始读取消息) 。
比如说,刚才 group1 消费组里的 consumer1 消费者消费了一条 id 为 1654254953808-0 的消息,现在用 group2 消费组里的 consumer1 消费者消费消息:
> XREADGROUP GROUP group2 consumer1 STREAMS mymq >
1) 1) "mymq"
2) 1) 1) "1654254953808-0"
2) 1) "name"
2) "xiaolin"
因为我创建两组的消费组都是从第一条消息开始读取,所以可以看到第二组的消费者依然可以消费 id 为 1654254953808-0 的这一条消息。因此,不同的消费组的消费者可以消费同一条消息。
使用消费组的目的是让组内的多个消费者共同分担读取消息,所以,我们通常会让每个消费者读取部分消息,从而实现消息读取负载在多个消费者间是均衡分布的。
例如,我们执行下列命令,让 group2 中的 consumer1、2、3 各自读取一条消息。
# 让 group2 中的 consumer1 从 mymq 消息队列中消费一条消息
> XREADGROUP GROUP group2 consumer1 COUNT 1 STREAMS mymq >
1) 1) "mymq"
2) 1) 1) "1654254953808-0"
2) 1) "name"
2) "xiaolin"
# 让 group2 中的 consumer2 从 mymq 消息队列中消费一条消息
> XREADGROUP GROUP group2 consumer2 COUNT 1 STREAMS mymq >
1) 1) "mymq"
2) 1) 1) "1654256265584-0"
2) 1) "name"
2) "xiaolincoding"
# 让 group2 中的 consumer3 从 mymq 消息队列中消费一条消息
> XREADGROUP GROUP group2 consumer3 COUNT 1 STREAMS mymq >
1) 1) "mymq"
2) 1) 1) "1654256271337-0"
2) 1) "name"
2) "Tom"
基于 Stream 实现的消息队列,如何保证消费者在发生故障或宕机再次重启后,仍然可以读取未处理完的消息?
Streams 会自动使用内部队列(也称为 PENDING List)留存消费组里每个消费者读取的消息,直到消费者使用 XACK 命令通知 Streams“消息已经处理完成”。
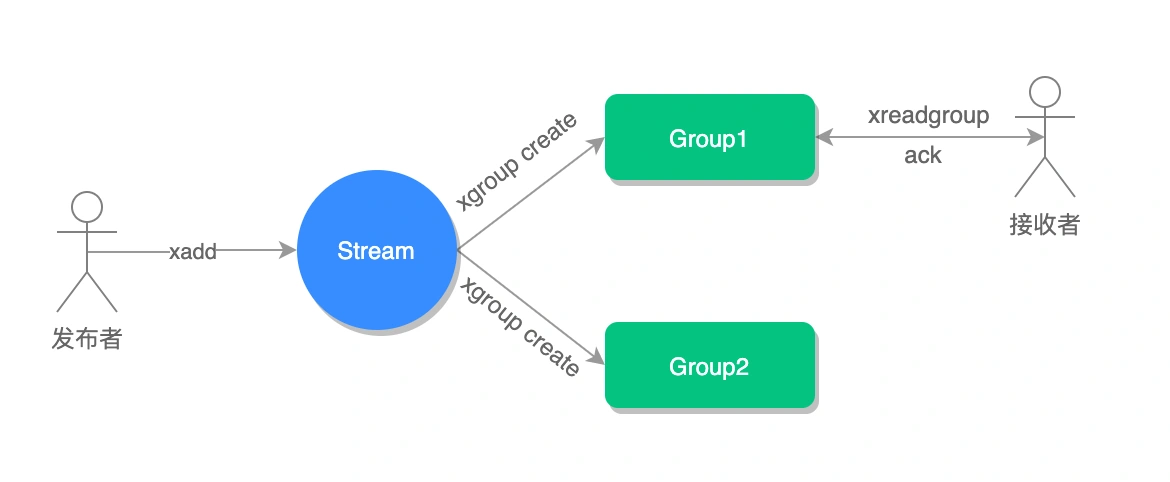
消费确认增加了消息的可靠性,一般在业务处理完成之后,需要执行 XACK 命令确认消息已经被消费完成,整个流程的执行如下图所示:
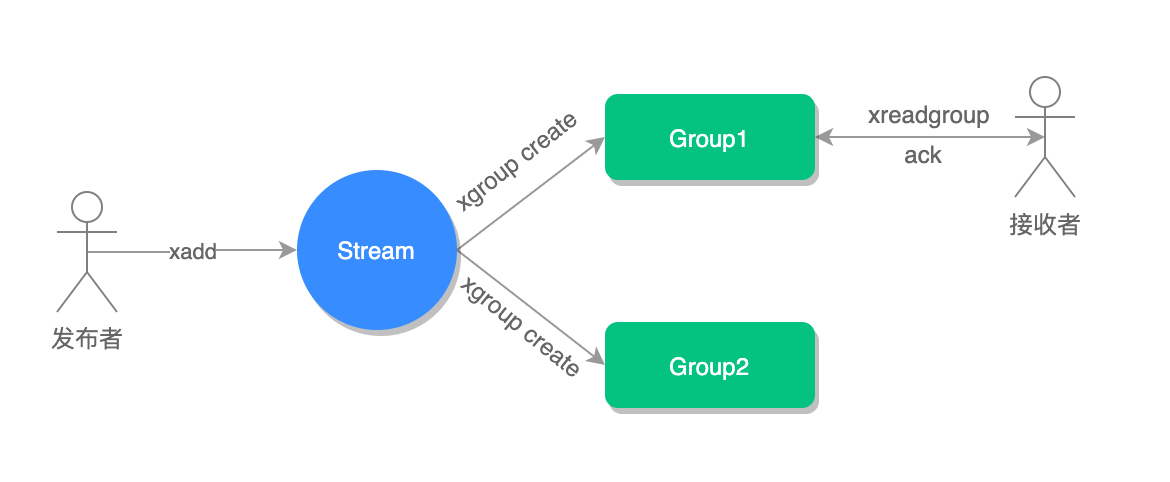
如果消费者没有成功处理消息,它就不会给 Streams 发送 XACK 命令,消息仍然会留存。此时, 消费者可以在重启后,用 XPENDING 命令查看已读取、但尚未确认处理完成的消息 。
例如,我们来查看一下 group2 中各个消费者已读取、但尚未确认的消息个数,命令如下:
127.0.0.1:6379> XPENDING mymq group2
1) (integer) 3
2) "1654254953808-0" # 表示 group2 中所有消费者读取的消息最小 ID
3) "1654256271337-0" # 表示 group2 中所有消费者读取的消息最大 ID
4) 1) 1) "consumer1"
2) "1"
2) 1) "consumer2"
2) "1"
3) 1) "consumer3"
2) "1"
如果想查看某个消费者具体读取了哪些数据,可以执行下面的命令:
# 查看 group2 里 consumer2 已从 mymq 消息队列中读取了哪些消息
> XPENDING mymq group2 - + 10 consumer2
1) 1) "1654256265584-0"
2) "consumer2"
3) (integer) 410700
4) (integer) 1
可以看到,consumer2 已读取的消息的 ID 是 1654256265584-0。
一旦消息 1654256265584-0 被 consumer2 处理了,consumer2 就可以使用 XACK 命令通知 Streams,然后这条消息就会被删除 。
> XACK mymq group2 1654256265584-0
(integer) 1
当我们再使用 XPENDING 命令查看时,就可以看到,consumer2 已经没有已读取、但尚未确认处理的消息了。
> XPENDING mymq group2 - + 10 consumer2
(empty array)
好了,基于 Stream 实现的消息队列就说到这里了,小结一下:
- 消息保序:XADD/XREAD
- 阻塞读取:XREAD block
- 重复消息处理:Stream 在使用 XADD 命令,会自动生成全局唯一 ID;
- 消息可靠性:内部使用 PENDING List 自动保存消息,使用 XPENDING 命令查看消费组已经读取但是未被确认的消息,消费者使用 XACK 确认消息;
- 支持消费组形式消费数据
Redis 基于 Stream 消息队列与专业的消息队列有哪些差距?
一个专业的消息队列,必须要做到两大块:
- 消息不丢。
- 消息可堆积。
1、Redis Stream 消息会丢失吗?
使用一个消息队列,其实就分为三大块: 生产者、队列中间件、消费者 ,所以要保证消息就是保证三个环节都不能丢失数据。
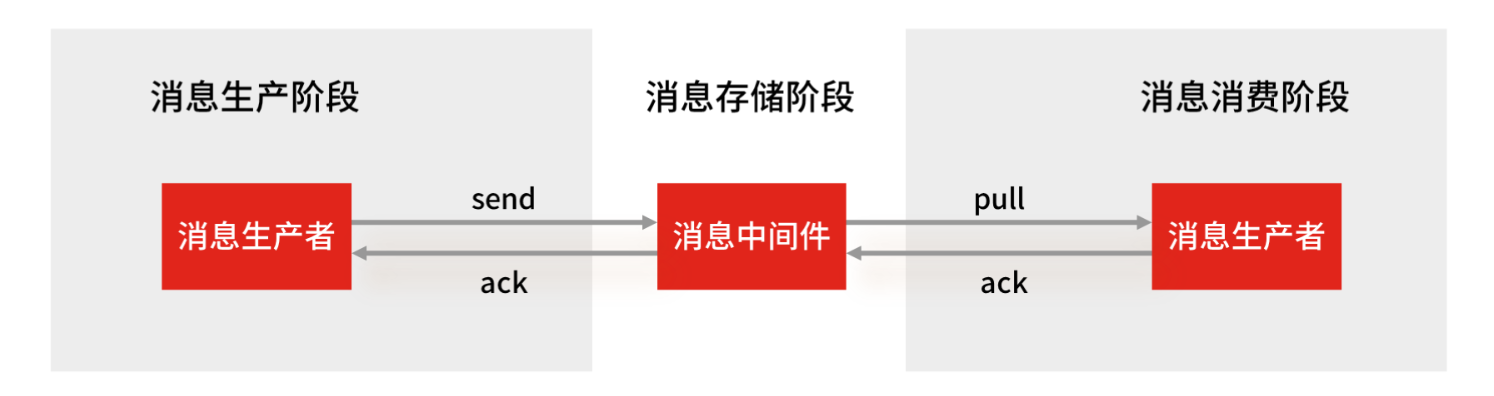
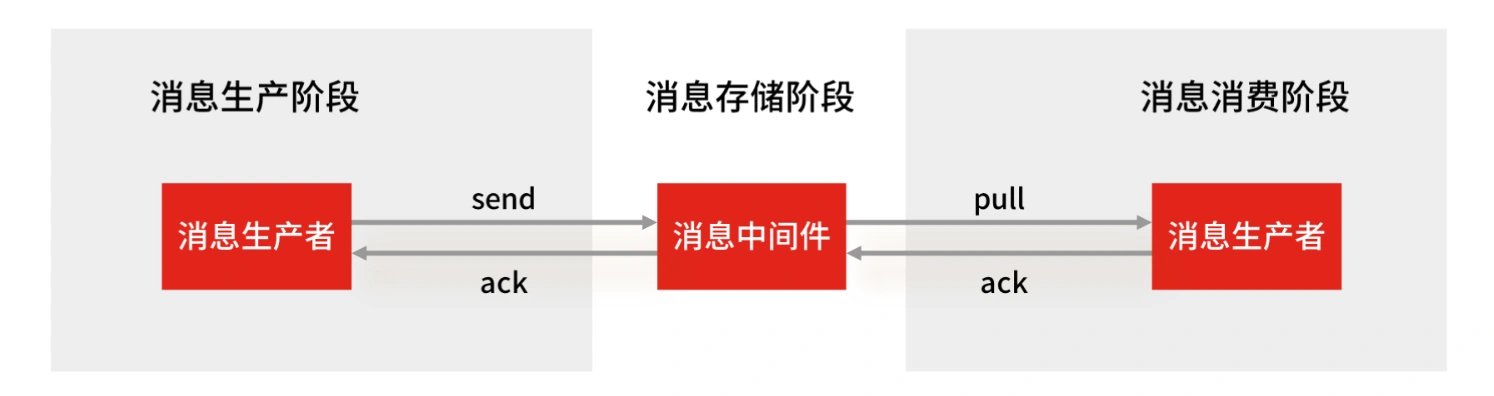
Redis Stream 消息队列能不能保证三个环节都不丢失数据?
- Redis 生产者会不会丢消息?生产者会不会丢消息,取决于生产者对于异常情况的处理是否合理。 从消息被生产出来,然后提交给 MQ 的过程中,只要能正常收到 ( MQ 中间件) 的 ack 确认响应,就表示发送成功,所以只要处理好返回值和异常,如果返回异常则进行消息重发,那么这个阶段是不会出现消息丢失的。
- Redis 消费者会不会丢消息?不会,因为 Stream ( MQ 中间件)会自动使用内部队列(也称为 PENDING List)留存消费组里每个消费者读取的消息,但是未被确认的消息。消费者可以在重启后,用 XPENDING 命令查看已读取、但尚未确认处理完成的消息。等到消费者执行完业务逻辑后,再发送消费确认 XACK 命令,也能保证消息的不丢失。
- Redis 消息中间件会不会丢消息? 会 ,Redis 在以下 2 个场景下,都会导致数据丢失:
- AOF 持久化配置为每秒写盘,但这个写盘过程是异步的,Redis 宕机时会存在数据丢失的可能
- 主从复制也是异步的,主从切换时,也存在丢失数据的可能 (opens new window)。
可以看到,Redis 在队列中间件环节无法保证消息不丢。像 RabbitMQ 或 Kafka 这类专业的队列中间件,在使用时是部署一个集群,生产者在发布消息时,队列中间件通常会写「多个节点」,也就是有多个副本,这样一来,即便其中一个节点挂了,也能保证集群的数据不丢失。
2、Redis Stream 消息可堆积吗?
Redis 的数据都存储在内存中,这就意味着一旦发生消息积压,则会导致 Redis 的内存持续增长,如果超过机器内存上限,就会面临被 OOM 的风险。
所以 Redis 的 Stream 提供了可以指定队列最大长度的功能,就是为了避免这种情况发生。
当指定队列最大长度时,队列长度超过上限后,旧消息会被删除,只保留固定长度的新消息。这么来看,Stream 在消息积压时,如果指定了最大长度,还是有可能丢失消息的。
但 Kafka、RabbitMQ 专业的消息队列它们的数据都是存储在磁盘上,当消息积压时,无非就是多占用一些磁盘空间。
因此,把 Redis 当作队列来使用时,会面临的 2 个问题:
- Redis 本身可能会丢数据;
- 面对消息挤压,内存资源会紧张;
所以,能不能将 Redis 作为消息队列来使用,关键看你的业务场景:
- 如果你的业务场景足够简单,对于数据丢失不敏感,而且消息积压概率比较小的情况下,把 Redis 当作队列是完全可以的。
- 如果你的业务有海量消息,消息积压的概率比较大,并且不能接受数据丢失,那么还是用专业的消息队列中间件吧。
补充:Redis 发布/订阅机制为什么不可以作为消息队列?
发布订阅机制存在以下缺点,都是跟丢失数据有关:
- 发布/订阅机制没有基于任何数据类型实现,所以不具备「数据持久化」的能力,也就是发布/订阅机制的相关操作,不会写入到 RDB 和 AOF 中,当 Redis 宕机重启,发布/订阅机制的数据也会全部丢失。
- 发布订阅模式是“发后既忘”的工作模式,如果有订阅者离线重连之后不能消费之前的历史消息。
- 当消费端有一定的消息积压时,也就是生产者发送的消息,消费者消费不过来时,如果超过 32M 或者是 60s 内持续保持在 8M 以上,消费端会被强行断开,这个参数是在配置文件中设置的,默认值是
client-output-buffer-limit pubsub 32mb 8mb 60。
所以,发布/订阅机制只适合即使通讯的场景,比如构建哨兵集群的场景采用了发布/订阅机制。redis的key过期删除策略
设置过期时间
expire <key> <n>:设置 key 在 n 秒后过期,比如 expire key 100 表示设置 key 在 100 秒后过期;pexpire <key> <n>:设置 key 在 n 毫秒后过期,比如 pexpire key2 100000 表示设置 key2 在 100000 毫秒(100 秒)后过期。expireat <key> <n>:设置 key 在某个时间戳(精确到秒)之后过期,比如 expireat key3 1655654400 表示 key3 在时间戳 1655654400 后过期(精确到秒);pexpireat <key> <n>:设置 key 在某个时间戳(精确到毫秒)之后过期,比如 pexpireat key4 1655654400000 表示 key4 在时间戳 1655654400000 后过期(精确到毫秒)
当然,在设置字符串时,也可以同时对 key 设置过期时间,共有 3 种命令:
set <key> <value> ex <n>:设置键值对的时候,同时指定过期时间(精确到秒);set <key> <value> px <n>:设置键值对的时候,同时指定过期时间(精确到毫秒);setex <key> <n> <valule>:设置键值对的时候,同时指定过期时间(精确到秒)。
查看key的过期时间
ttl <key>
取消过期时间
persist <key>
怎么判断过期时间
每当我们对一个 key 设置了过期时间时,Redis 会把该 key 带上过期时间存储到一个 过期字典 (expires dict)中,也就是说「过期字典」保存了数据库中所有 key 的过期时间。
过期字典存储在 redisDb 结构中,如下:
typedef struct redisDb {
dict *dict; /* 数据库键空间,存放着所有的键值对 */
dict *expires; /* 键的过期时间 */
....
} redisDb;
过期字典数据结构结构如下:
- 过期字典的 key 是一个指针,指向某个键对象;
- 过期字典的 value 是一个 long long 类型的整数,这个整数保存了 key 的过期时间;
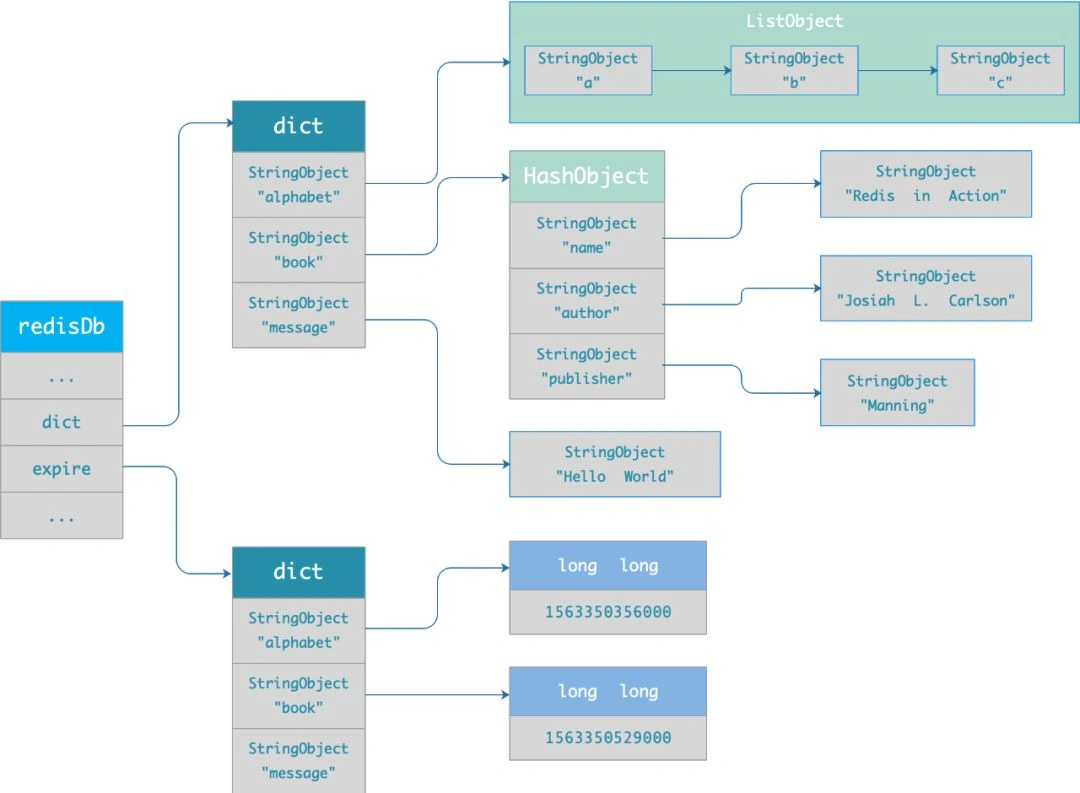
查询key值的流程:
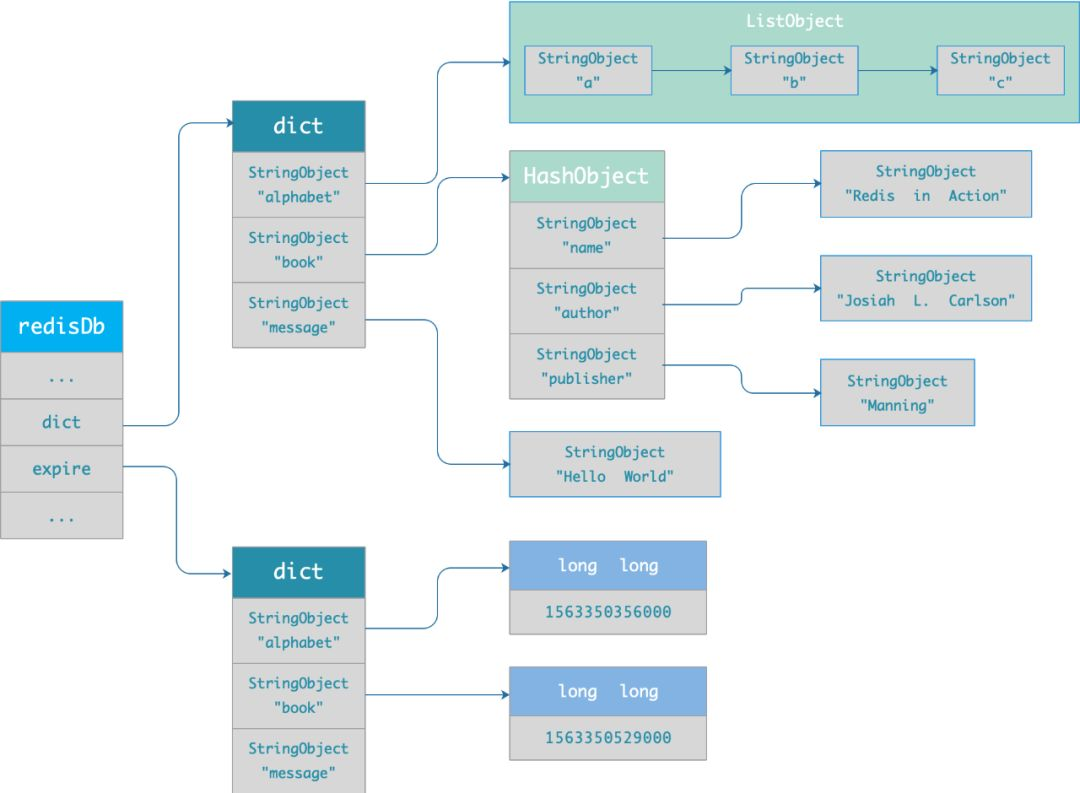 字典实际上是哈希表,哈希表的最大好处就是让我们可以用 O(1) 的时间复杂度来快速查找。当我们查询一个 key 时,Redis 首先检查该 key 是否存在于过期字典中:
字典实际上是哈希表,哈希表的最大好处就是让我们可以用 O(1) 的时间复杂度来快速查找。当我们查询一个 key 时,Redis 首先检查该 key 是否存在于过期字典中:
- 如果不在,则正常读取键值;
- 如果存在,则会获取该 key 的过期时间,然后与当前系统时间进行比对,如果比系统时间大,那就没有过期,否则判定该 key 已过期。
过期删除策略
常见有三种过期删除策略:
- 定时删除;
- 惰性删除;
- 定期删除;
定时删除策略
做法:在设置 key 的过期时间时,同时创建一个定时事件,当时间到达时,由事件处理器自动执行 key 的删除操作。
优点:可以保证过期 key 会被尽快删除,也就是内存可以被尽快地释放。因此,定时删除对内存是最友好的。
缺点:在过期 key 比较多的情况下,删除过期 key 可能会占用相当一部分 CPU 时间,在内存不紧张但 CPU 时间紧张的情况下,将 CPU 时间用于删除和当前任务无关的过期键上,无疑会对服务器的响应时间和吞吐量造成影响。所以,定时删除策略对 CPU 不友好。
惰性删除策略
做法:不主动删除过期键,每次从数据库访问 key 时,都检测 key 是否过期,如果过期则删除该 key。
优点:因为每次访问时,才会检查 key 是否过期,所以此策略只会使用很少的系统资源,因此,惰性删除策略对 CPU 时间最友好。
缺点:如果一个 key 已经过期,而这个 key 又仍然保留在数据库中,那么只要这个过期 key 一直没有被访问,它所占用的内存就不会释放,造成了一定的内存空间浪费。所以,惰性删除策略对内存不友好。
定期删除策略
做法:每隔一段时间「随机」从数据库中取出一定数量的 key 进行检查,并删除其中的过期key。
优点:通过限制删除操作执行的时长和频率,来减少删除操作对 CPU 的影响,同时也能删除一部分过期的数据减少了过期键对空间的无效占用。
缺点:
- 内存清理方面没有定时删除效果好,同时没有惰性删除使用的系统资源少。
- 难以确定删除操作执行的时长和频率。如果执行的太频繁,定期删除策略变得和定时删除策略一样,对CPU不友好;如果执行的太少,那又和惰性删除一样了,过期 key 占用的内存不会及时得到释放。
redis设置过期删除策略
Redis 选择「惰性删除+定期删除」这两种策略配和使用。
惰性删除实现
Redis 的惰性删除策略由 db.c 文件中的 expireIfNeeded 函数实现,代码如下:
int expireIfNeeded(redisDb *db, robj *key) {
// 判断 key 是否过期
if (!keyIsExpired(db,key)) return 0;
....
/* 删除过期键 */
....
// 如果 server.lazyfree_lazy_expire 为 1 表示异步删除,反之同步删除;
return server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) :
dbSyncDelete(db,key);
}
Redis 在访问或者修改 key 之前,都会调用 expireIfNeeded 函数对其进行检查,检查 key 是否过期:
- 如果过期,则删除该 key,至于选择异步删除,还是选择同步删除,根据
lazyfree_lazy_expire参数配置决定(Redis 4.0版本开始提供参数),然后返回 null 客户端; - 如果没有过期,不做任何处理,然后返回正常的键值对给客户端;
定期删除实现
Redis的定期删除策略:
做法:每隔一段时间「随机」从数据库中取出一定数量的 key 进行检查,并删除其中的过期key。
1、这个间隔检查的时间是多长呢?
在 Redis 中,默认每秒进行 10 次过期检查一次数据库,此配置可通过 Redis 的配置文件 redis.conf 进行配置,配置键为 hz 它的默认值是 hz 10。
特别强调下,每次检查数据库并不是遍历过期字典中的所有 key,而是从数据库中随机抽取一定数量的 key 进行过期检查。
2、随机抽查的数量是多少呢?
我查了下源码,定期删除的实现在 expire.c 文件下的 activeExpireCycle 函数中,其中随机抽查的数量由 ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP 定义的,它是写死在代码中的,数值是 20。
也就是说,数据库每轮抽查时,会随机选择 20 个 key 判断是否过期。
接下来,详细说说 Redis 的定期删除的流程:
- 从过期字典中随机抽取 20 个 key;
- 检查这 20 个 key 是否过期,并删除已过期的 key;
- 如果本轮检查的已过期 key 的数量,超过 5 个(20/4),也就是「已过期 key 的数量」占比「随机抽取 key 的数量」大于 25%,则继续重复步骤 1;如果已过期的 key 比例小于 25%,则停止继续删除过期 key,然后等待下一轮再检查。
可以看到,定期删除是一个循环的流程。
那 Redis 为了保证定期删除不会出现循环过度,导致线程卡死现象,为此增加了定期删除循环流程的时间上限,默认不会超过 25ms。
redis的数据结构
共有 8 种数据结构:SDS、双向链表、压缩列表、哈希表、跳表、整数集合、quicklist、listpack。
redis保存键值涉及到的结构

这些数据结构的内部细节,我先不展开讲,后面在讲哈希表数据结构的时候,在详细的说说,因为用到的数据结构是一样的。这里先大概说下图中涉及到的数据结构的名字和用途:
- redisDb 结构,表示 Redis 数据库的结构,结构体里存放了指向了 dict 结构的指针;
- dict 结构,结构体里存放了 2 个哈希表,正常情况下都是用「哈希表1」,「哈希表2」只有在 rehash 的时候才用,具体什么是 rehash,我在本文的哈希表数据结构会讲;
- ditctht 结构,表示哈希表的结构,结构里存放了哈希表数组,数组中的每个元素都是指向一个哈希表节点结构(dictEntry)的指针;
- dictEntry 结构,表示哈希表节点的结构,结构里存放了 **void * key 和 void * value 指针, key 指向的是 String 对象,而 value 则可以指向 String 对象,也可以指向集合类型的对象,比如 List 对象、Hash 对象、Set 对象和 Zset 对象 。
特别说明下,void * key 和 void * value 指针指向的是 Redis 对象 ,Redis 中的每个对象都由 redisObject 结构表示,如下图:

对象结构里包含的成员变量:
- type,标识该对象是什么类型的对象(String 对象、 List 对象、Hash 对象、Set 对象和 Zset 对象);
- encoding,标识该对象使用了哪种底层的数据结构;
- ptr,指向底层数据结构的指针 。
我画了一张 Redis 键值对数据库的全景图,你就能清晰知道 Redis 对象和数据结构的关系了:

接下里,就好好聊一下底层数据结构!
1.SDS
字符串在 Redis 中是很常用的,键值对中的键是字符串类型,值有时也是字符串类型。
Redis 是用 C 语言实现的,但是它没有直接使用 C 语言的 char* 字符数组来实现字符串,而是自己封装了一个名为简单动态字符串(simple dynamic string,SDS) 的数据结构来表示字符串,也就是 Redis 的 String 数据类型的底层数据结构是 SDS。
既然 Redis 设计了 SDS 结构来表示字符串,肯定是 C 语言的 char* 字符数组存在一些缺陷。
要了解这一点,得先来看看 char* 字符数组的结构。
C 语言字符串的缺陷
C 语言的字符串其实就是一个字符数组,即数组中每个元素是字符串中的一个字符。
比如,下图就是字符串“xiaolin”的 char* 字符数组的结构:

没学过 C 语言的同学,可能会好奇为什么最后一个字符是“\0”?
在 C 语言里,对字符串操作时,char * 指针只是指向字符数组的起始位置,而 字符数组的结尾位置就用“\0”表示,意思是指字符串的结束 。
因此,C 语言标准库中的字符串操作函数就通过判断字符是不是 “\0” 来决定要不要停止操作,如果当前字符不是 “\0” ,说明字符串还没结束,可以继续操作,如果当前字符是 “\0” 是则说明字符串结束了,就要停止操作。
举个例子,C 语言获取字符串长度的函数 strlen,就是通过字符数组中的每一个字符,并进行计数,等遇到字符为 “\0” 后,就会停止遍历,然后返回已经统计到的字符个数,即为字符串长度。下图显示了 strlen 函数的执行流程:

很明显, C 语言获取字符串长度的时间复杂度是 O(N)(这是一个可以改进的地方 )
C 语言字符串用 “\0” 字符作为结尾标记有个缺陷。假设有个字符串中有个 “\0” 字符,这时在操作这个字符串时就会 提早结束 ,比如 “xiao\0lin” 字符串,计算字符串长度的时候则会是 4,如下图:

因此,除了字符串的末尾之外, 字符串里面不能含有 “\0” 字符 ,否则最先被程序读入的 “\0” 字符将被误认为是字符串结尾,这个限制使得 C 语言的字符串只能保存文本数据,不能保存像图片、音频、视频文化这样的二进制数据( 这也是一个可以改进的地方 )
另外, C 语言标准库中字符串的操作函数是很不安全的,对程序员很不友好,稍微一不注意,就会导致缓冲区溢出。
举个例子,strcat 函数是可以将两个字符串拼接在一起。
//将 src 字符串拼接到 dest 字符串后面
char *strcat(char *dest, const char* src);
C 语言的字符串是不会记录自身的缓冲区大小的 ,所以 strcat 函数假定程序员在执行这个函数时,已经为 dest 分配了足够多的内存,可以容纳 src 字符串中的所有内容,而 一旦这个假定不成立,就会发生缓冲区溢出将可能会造成程序运行终止,(这是一个可以改进的地方 )。
而且,strcat 函数和 strlen 函数类似,时间复杂度也很高,也都需要先通过遍历字符串才能得到目标字符串的末尾。然后对于 strcat 函数来说,还要再遍历源字符串才能完成追加, 对字符串的操作效率不高 。
好了, 通过以上的分析,我们可以得知 C 语言的字符串不足之处以及可以改进的地方:
- 获取字符串长度的时间复杂度为 O(N);
- 字符串的结尾是以 “\0” 字符标识,字符串里面不能包含有 “\0” 字符,因此不能保存二进制数据;
- 字符串操作函数不高效且不安全,比如有缓冲区溢出的风险,有可能会造成程序运行终止;
Redis 实现的 SDS 的结构就把上面这些问题解决了,接下来我们一起看看 Redis 是如何解决的。
SDS 结构设计
下图就是 Redis 5.0 的 SDS 的数据结构:

结构中的每个成员变量分别介绍下:
- len,记录了字符串长度 。这样获取字符串长度的时候,只需要返回这个成员变量值就行,时间复杂度只需要 O(1)。
- alloc,分配给字符数组的空间长度 。这样在修改字符串的时候,可以通过
alloc - len计算出剩余的空间大小,可以用来判断空间是否满足修改需求,如果不满足的话,就会自动将 SDS 的空间扩展至执行修改所需的大小,然后才执行实际的修改操作,所以使用 SDS 既不需要手动修改 SDS 的空间大小,也不会出现前面所说的缓冲区溢出的问题。 - flags,用来表示不同类型的 SDS 。一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64,后面在说明区别之处。
- buf[],字符数组,用来保存实际数据 。不仅可以保存字符串,也可以保存二进制数据。
总的来说,Redis 的 SDS 结构在原本字符数组之上,增加了三个元数据:len、alloc、flags,用来解决 C 语言字符串的缺陷。
O(1)复杂度获取字符串长度
C 语言的字符串长度获取 strlen 函数,需要通过遍历的方式来统计字符串长度,时间复杂度是 O(N)。
而 Redis 的 SDS 结构因为加入了 len 成员变量,那么 获取字符串长度的时候,直接返回这个成员变量的值就行,所以复杂度只有 O(1) 。
二进制安全
因为 SDS 不需要用 “\0” 字符来标识字符串结尾了,而是 有个专门的 len 成员变量来记录长度,所以可存储包含 “\0” 的数据 。但是 SDS 为了兼容部分 C 语言标准库的函数, SDS 字符串结尾还是会加上 “\0” 字符。
因此, SDS 的 API 都是以处理二进制的方式来处理 SDS 存放在 buf[] 里的数据,程序不会对其中的数据做任何限制,数据写入的时候时什么样的,它被读取时就是什么样的。
通过使用二进制安全的 SDS,而不是 C 字符串,使得 Redis 不仅可以保存文本数据,也可以保存任意格式的二进制数据。
不会发生缓冲区溢出
C 语言的字符串标准库提供的字符串操作函数,大多数(比如 strcat 追加字符串函数)都是不安全的,因为这些函数把缓冲区大小是否满足操作需求的工作交由开发者来保证,程序内部并不会判断缓冲区大小是否足够用,当发生了缓冲区溢出就有可能造成程序异常结束。
所以,Redis 的 SDS 结构里引入了 alloc 和 len 成员变量,这样 SDS API 通过 alloc - len 计算,可以算出剩余可用的空间大小,这样在对字符串做修改操作的时候,就可以由程序内部判断缓冲区大小是否足够用。
而且, 当判断出缓冲区大小不够用时,Redis 会自动将扩大 SDS 的空间大小(小于 1MB 翻倍扩容,大于 1MB 按 1MB 扩容) ,以满足修改所需的大小。
在扩展 SDS 空间之前,SDS API 会优先检查未使用空间是否足够,如果不够的话,API 不仅会为 SDS 分配修改所必须要的空间,还会给 SDS 分配额外的「未使用空间」。
这样的好处是,下次在操作 SDS 时,如果 SDS 空间够的话,API 就会直接使用「未使用空间」,而无须执行内存分配, 有效的减少内存分配次数 。
所以,使用 SDS 即不需要手动修改 SDS 的空间大小,也不会出现缓冲区溢出的问题。
节省内存空间
SDS 结构中有个 flags 成员变量,表示的是 SDS 类型。
Redis 一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64。
这 5 种类型的主要 区别就在于,它们数据结构中的 len 和 alloc 成员变量的数据类型不同 。
比如 sdshdr16 和 sdshdr32 这两个类型,它们的定义分别如下:
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len;
uint16_t alloc;
unsigned char flags;
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len;
uint32_t alloc;
unsigned char flags;
char buf[];
};
可以看到:
- sdshdr16 类型的 len 和 alloc 的数据类型都是 uint16_t,表示字符数组长度和分配空间大小不能超过 2 的 16 次方。
- sdshdr32 则都是 uint32_t,表示表示字符数组长度和分配空间大小不能超过 2 的 32 次方。
之所以 SDS 设计不同类型的结构体,是为了能灵活保存不同大小的字符串,从而有效节省内存空间 。比如,在保存小字符串时,结构头占用空间也比较少。
除了设计不同类型的结构体,Redis 在编程上还 使用了专门的编译优化来节省内存空间 ,即在 struct 声明了 __attribute__ ((packed)) ,它的作用是: 告诉编译器取消结构体在编译过程中的优化对齐,按照实际占用字节数进行对齐 。
比如,sdshdr16 类型的 SDS,默认情况下,编译器会按照 2 字节对齐的方式给变量分配内存,这意味着,即使一个变量的大小不到 2 个字节,编译器也会给它分配 2 个字节。
举个例子,假设下面这个结构体,它有两个成员变量,类型分别是 char 和 int,如下所示:
#include <stdio.h>
struct test1 {
char a;
int b;
} test1;
int main() {
printf("%lu\n", sizeof(test1));
return 0;
}
大家猜猜这个结构体大小是多少?我先直接说答案,这个结构体大小计算出来是 8。

这是因为默认情况下,编译器是使用「字节对齐」的方式分配内存,虽然 char 类型只占一个字节,但是由于成员变量里有 int 类型,它占用了 4 个字节,所以在成员变量为 char 类型分配内存时,会分配 4 个字节,其中这多余的 3 个字节是为了字节对齐而分配的,相当于有 3 个字节被浪费掉了。
如果不想编译器使用字节对齐的方式进行分配内存,可以采用了 __attribute__ ((packed)) 属性定义结构体,这样一来,结构体实际占用多少内存空间,编译器就分配多少空间。
比如,我用 __attribute__ ((packed)) 属性定义下面的结构体 ,同样包含 char 和 int 两个类型的成员变量,代码如下所示:
#include <stdio.h>
struct __attribute__((packed)) test2 {
char a;
int b;
} test2;
int main() {
printf("%lu\n", sizeof(test2));
return 0;
}
这时打印的结果是 5(1 个字节 char + 4 字节 int)。

可以看得出,这是按照实际占用字节数进行分配内存的,这样可以节省内存空间。
2.链表
大家最熟悉的数据结构除了数组之外,我相信就是链表了。
Redis 的 List 对象的底层实现之一就是链表。C 语言本身没有链表这个数据结构的,所以 Redis 自己设计了一个链表数据结构。
链表节点结构设计
先来看看「链表节点」结构的样子:
typedef struct listNode {
//前置节点
struct listNode *prev;
//后置节点
struct listNode *next;
//节点的值
void *value;
} listNode;
有前置节点和后置节点,可以看的出,这个是一个双向链表。

链表结构设计
不过,Redis 在 listNode 结构体基础上又封装了 list 这个数据结构,这样操作起来会更方便,链表结构如下:
typedef struct list {
//链表头节点
listNode *head;
//链表尾节点
listNode *tail;
//节点值复制函数
void *(*dup)(void *ptr);
//节点值释放函数
void (*free)(void *ptr);
//节点值比较函数
int (*match)(void *ptr, void *key);
//链表节点数量
unsigned long len;
} list;
list 结构为链表提供了链表头指针 head、链表尾节点 tail、链表节点数量 len、以及可以自定义实现的 dup、free、match 函数。
举个例子,下面是由 list 结构和 3 个 listNode 结构组成的链表。
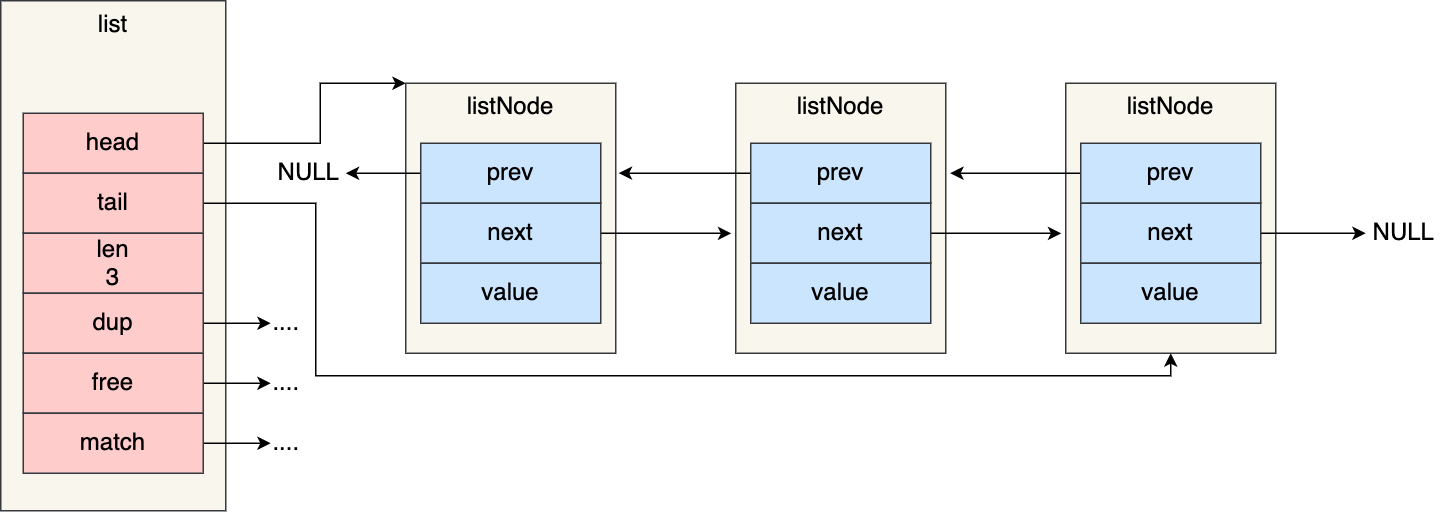
链表的优势与缺陷
Redis 的链表实现优点如下:
- listNode 链表节点的结构里带有 prev 和 next 指针, 获取某个节点的前置节点或后置节点的时间复杂度只需O(1),而且这两个指针都可以指向 NULL,所以链表是无环链表 ;
- list 结构因为提供了表头指针 head 和表尾节点 tail,所以 获取链表的表头节点和表尾节点的时间复杂度只需O(1) ;
- list 结构因为提供了链表节点数量 len,所以 获取链表中的节点数量的时间复杂度只需O(1) ;
- listNode 链表节使用 void* 指针保存节点值,并且可以通过 list 结构的 dup、free、match 函数指针为节点设置该节点类型特定的函数,因此 链表节点可以保存各种不同类型的值 ;
链表的缺陷也是有的:
- 链表每个节点之间的内存都是不连续的,意味着 无法很好利用 CPU 缓存 。能很好利用 CPU 缓存的数据结构就是数组,因为数组的内存是连续的,这样就可以充分利用 CPU 缓存来加速访问。
- 还有一点,保存一个链表节点的值都需要一个链表节点结构头的分配, 内存开销较大 。
因此,Redis 3.0 的 List 对象在数据量比较少的情况下,会采用「压缩列表」作为底层数据结构的实现,它的优势是节省内存空间,并且是内存紧凑型的数据结构。
不过,压缩列表存在性能问题(具体什么问题,下面会说),所以 Redis 在 3.2 版本设计了新的数据结构 quicklist,并将 List 对象的底层数据结构改由 quicklist 实现。
然后在 Redis 5.0 设计了新的数据结构 listpack,沿用了压缩列表紧凑型的内存布局,最终在最新的 Redis 版本,将 Hash 对象和 Zset 对象的底层数据结构实现之一的压缩列表,替换成由 listpack 实现。
3.压缩列表
压缩列表的最大特点,就是它被设计成一种内存紧凑型的数据结构,占用一块连续的内存空间,不仅可以利用 CPU 缓存,而且会针对不同长度的数据,进行相应编码,这种方法可以有效地节省内存开销。
但是,压缩列表的缺陷也是有的:
- 不能保存过多的元素,否则查询效率就会降低;
- 新增或修改某个元素时,压缩列表占用的内存空间需要重新分配,甚至可能引发连锁更新的问题。
因此,Redis 对象(List 对象、Hash 对象、Zset 对象)包含的元素数量较少,或者元素值不大的情况才会使用压缩列表作为底层数据结构。
接下来,就跟大家详细聊下压缩列表。
压缩列表结构设计
压缩列表是 Redis 为了节约内存而开发的,它是 由连续内存块组成的顺序型数据结构 ,有点类似于数组。

压缩列表在表头有三个字段:
- zlbytes ,记录整个压缩列表占用对内存字节数;
- zltail ,记录压缩列表「尾部」节点距离起始地址由多少字节,也就是列表尾的偏移量;
- zllen ,记录压缩列表包含的节点数量;
- zlend ,标记压缩列表的结束点,固定值 0xFF(十进制255)。
在压缩列表中,如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段(zllen)的长度直接定位,复杂度是 O(1)。而 查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了,因此压缩列表不适合保存过多的元素 。
另外,压缩列表节点(entry)的构成如下:
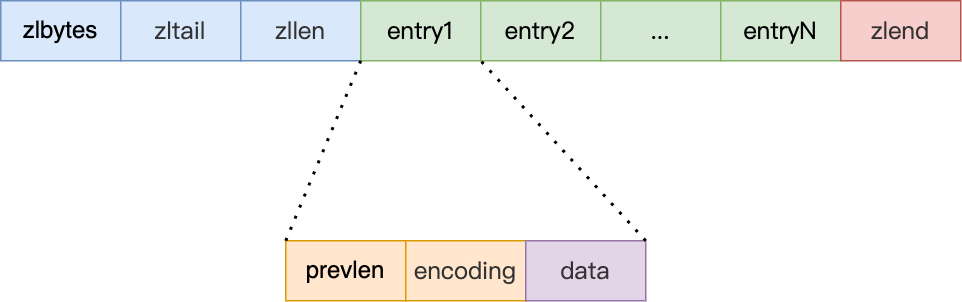
压缩列表节点包含三部分内容:
- prevlen ,记录了「前一个节点」的长度,目的是为了实现从后向前遍历;
- encoding ,记录了当前节点实际数据的「类型和长度」,类型主要有两种:字符串和整数。
- data ,记录了当前节点的实际数据,类型和长度都由
encoding决定;
当我们往压缩列表中插入数据时,压缩列表就会根据数据类型是字符串还是整数,以及数据的大小,会使用不同空间大小的 prevlen 和 encoding 这两个元素里保存的信息, 这种根据数据大小和类型进行不同的空间大小分配的设计思想,正是 Redis 为了节省内存而采用的 。
分别说下,prevlen 和 encoding 是如何根据数据的大小和类型来进行不同的空间大小分配。
压缩列表里的每个节点中的 prevlen 属性都记录了「前一个节点的长度」,而且 prevlen 属性的空间大小跟前一个节点长度值有关,比如:
- 如果 前一个节点的长度小于 254 字节 ,那么 prevlen 属性需要用 1 字节的空间来保存这个长度值;
- 如果 前一个节点的长度大于等于 254 字节 ,那么 prevlen 属性需要用 5 字节的空间来保存这个长度值;
encoding 属性的空间大小跟数据是字符串还是整数,以及字符串的长度有关,如下图(下图中的 content 表示的是实际数据,即本文的 data 字段):
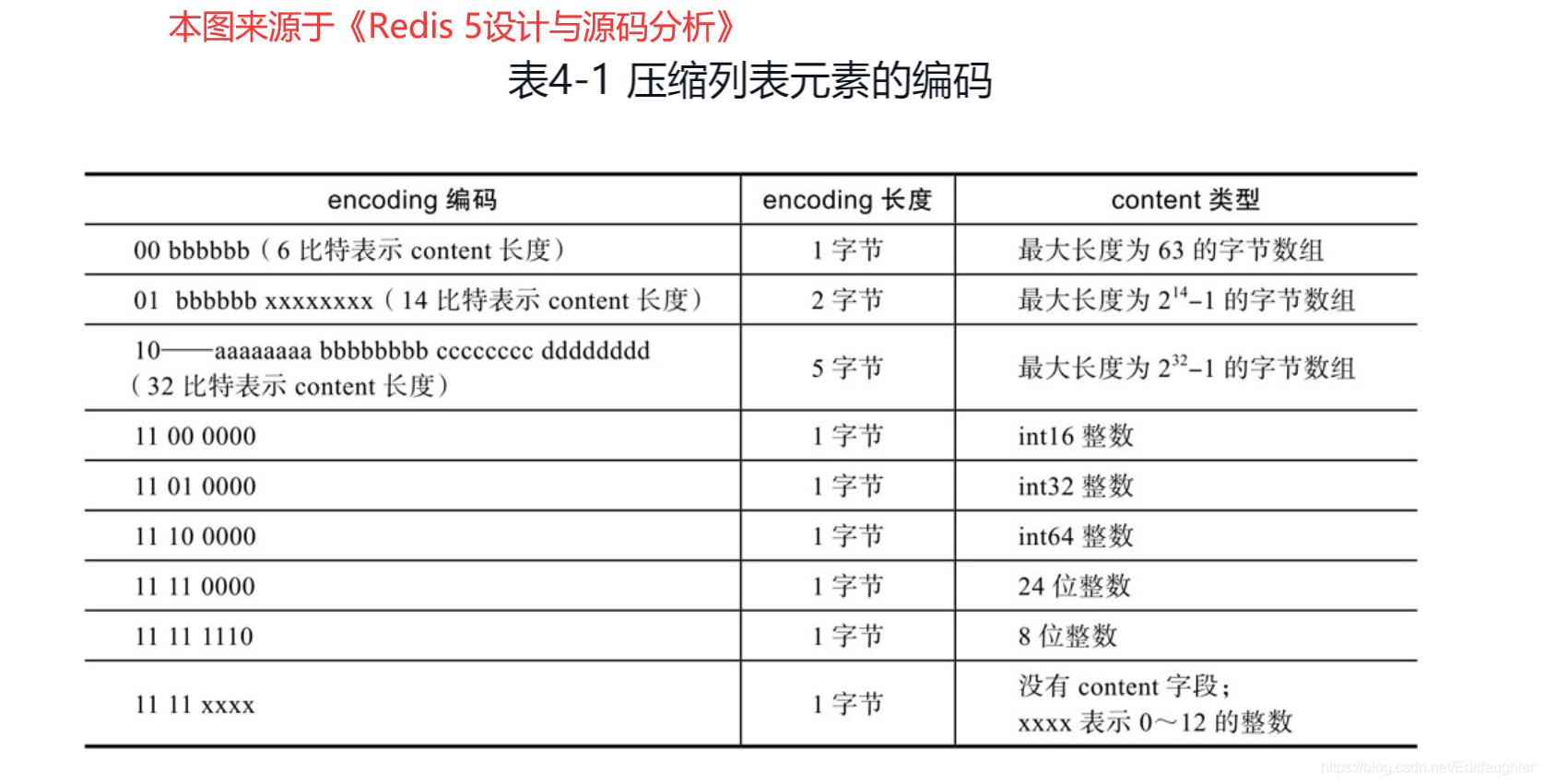
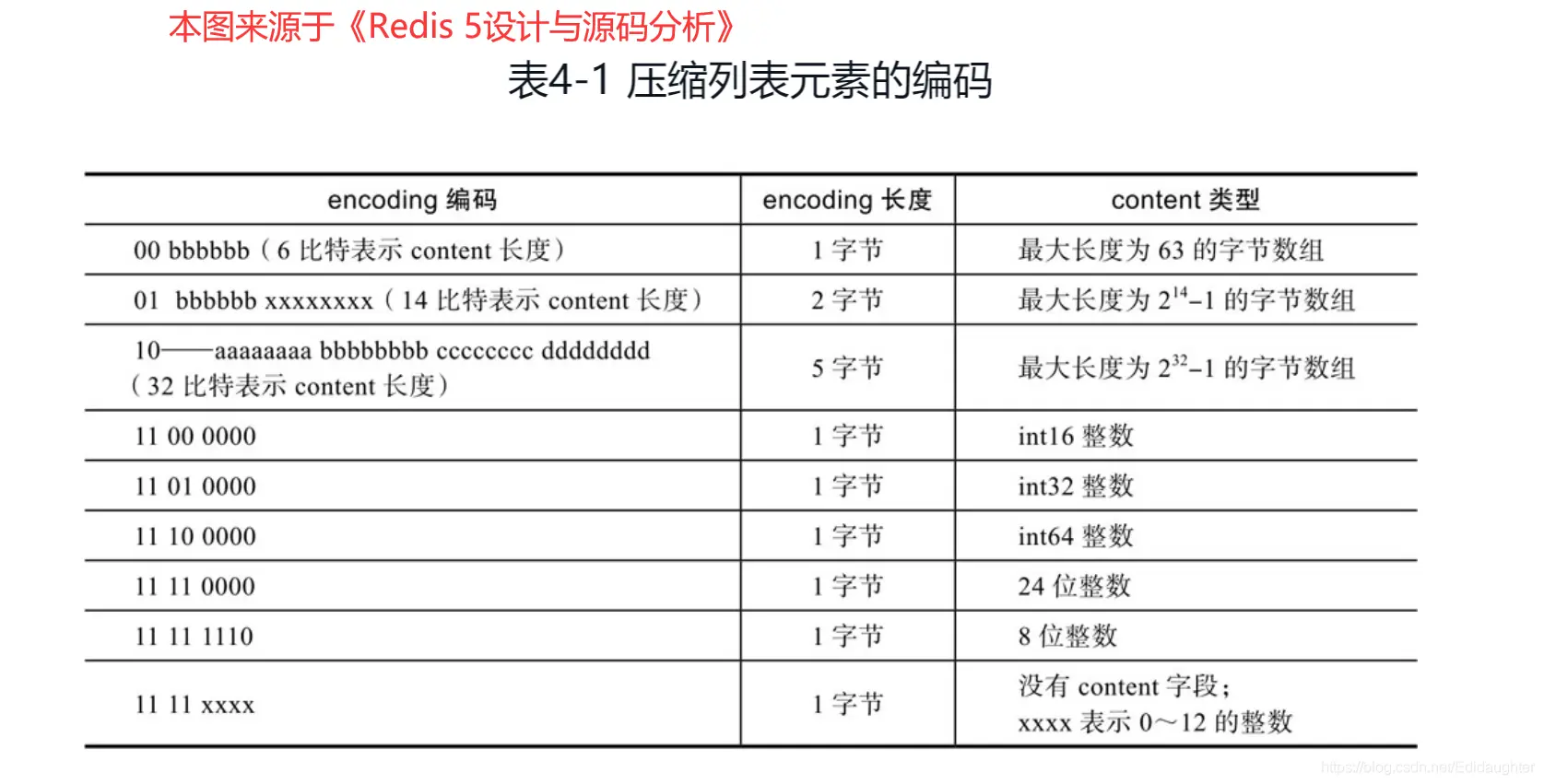
- 如果 当前节点的数据是整数 ,则 encoding 会使用 1 字节的空间进行编码,也就是 encoding 长度为 1 字节。通过 encoding 确认了整数类型,就可以确认整数数据的实际大小了,比如如果 encoding 编码确认了数据是 int16 整数,那么 data 的长度就是 int16 的大小。
- 如果 当前节点的数据是字符串,根据字符串的长度大小 ,encoding 会使用 1 字节/2字节/5字节的空间进行编码,encoding 编码的前两个 bit 表示数据的类型,后续的其他 bit 标识字符串数据的实际长度,即 data 的长度。
连锁更新
压缩列表除了查找复杂度高的问题,还有一个问题。
压缩列表新增某个元素或修改某个元素时,如果空间不不够,压缩列表占用的内存空间就需要重新分配。而当新插入的元素较大时,可能会导致后续元素的 prevlen 占用空间都发生变化,从而引起「连锁更新」问题,导致每个元素的空间都要重新分配,造成访问压缩列表性能的下降 。
前面提到,压缩列表节点的 prevlen 属性会根据前一个节点的长度进行不同的空间大小分配:
- 如果前一个 节点的长度小于 254 字节 ,那么 prevlen 属性需要用 1 字节的空间来保存这个长度值;
- 如果前一个 节点的长度大于等于 254 字节 ,那么 prevlen 属性需要用 5 字节的空间来保存这个长度值;
现在假设一个压缩列表中有多个连续的、长度在 250~253 之间的节点,如下图:

因为这些节点长度值小于 254 字节,所以 prevlen 属性需要用 1 字节的空间来保存这个长度值。
这时,如果将一个长度大于等于 254 字节的新节点加入到压缩列表的表头节点,即新节点将成为 e1 的前置节点,如下图:

因为 e1 节点的 prevlen 属性只有 1 个字节大小,无法保存新节点的长度,此时就需要对压缩列表的空间重分配操作,并将 e1 节点的 prevlen 属性从原来的 1 字节大小扩展为 5 字节大小。
多米诺牌的效应就此开始。

e1 原本的长度在 250~253 之间,因为刚才的扩展空间,此时 e1 的长度就大于等于 254 了,因此原本 e2 保存 e1 的 prevlen 属性也必须从 1 字节扩展至 5 字节大小。
正如扩展 e1 引发了对 e2 扩展一样,扩展 e2 也会引发对 e3 的扩展,而扩展 e3 又会引发对 e4 的扩展… 一直持续到结尾。
这种在特殊情况下产生的连续多次空间扩展操作就叫做「连锁更新」 ,就像多米诺牌的效应一样,第一张牌倒下了,推动了第二张牌倒下;第二张牌倒下,又推动了第三张牌倒下…,
压缩列表的缺陷
空间扩展操作也就是重新分配内存,因此 连锁更新一旦发生,就会导致压缩列表占用的内存空间要多次重新分配,这就会直接影响到压缩列表的访问性能 。
所以说, 虽然压缩列表紧凑型的内存布局能节省内存开销,但是如果保存的元素数量增加了,或是元素变大了,会导致内存重新分配,最糟糕的是会有「连锁更新」的问题 。
因此, 压缩列表只会用于保存的节点数量不多的场景 ,只要节点数量足够小,即使发生连锁更新,也是能接受的。
虽说如此,Redis 针对压缩列表在设计上的不足,在后来的版本中,新增设计了两种数据结构:quicklist(Redis 3.2 引入) 和 listpack(Redis 5.0 引入)。这两种数据结构的设计目标,就是尽可能地保持压缩列表节省内存的优势,同时解决压缩列表的「连锁更新」的问题。
4.hash表
哈希表是一种保存键值对(key-value)的数据结构。
哈希表中的每一个 key 都是独一无二的,程序可以根据 key 查找到与之关联的 value,或者通过 key 来更新 value,又或者根据 key 来删除整个 key-value等等。
在讲压缩列表的时候,提到过 Redis 的 Hash 对象的底层实现之一是压缩列表(最新 Redis 代码已将压缩列表替换成 listpack)。Hash 对象的另外一个底层实现就是哈希表。
哈希表优点在于,它 能以 O(1) 的复杂度快速查询数据 。怎么做到的呢?将 key 通过 Hash 函数的计算,就能定位数据在表中的位置,因为哈希表实际上是数组,所以可以通过索引值快速查询到数据。
但是存在的风险也是有,在哈希表大小固定的情况下,随着数据不断增多,那么哈希冲突的可能性也会越高。
解决哈希冲突的方式,有很多种。
Redis 采用了「链式哈希」来解决哈希冲突 ,在不扩容哈希表的前提下,将具有相同哈希值的数据串起来,形成链接起,以便这些数据在表中仍然可以被查询到。
接下来,详细说说哈希表。
哈希表结构设计
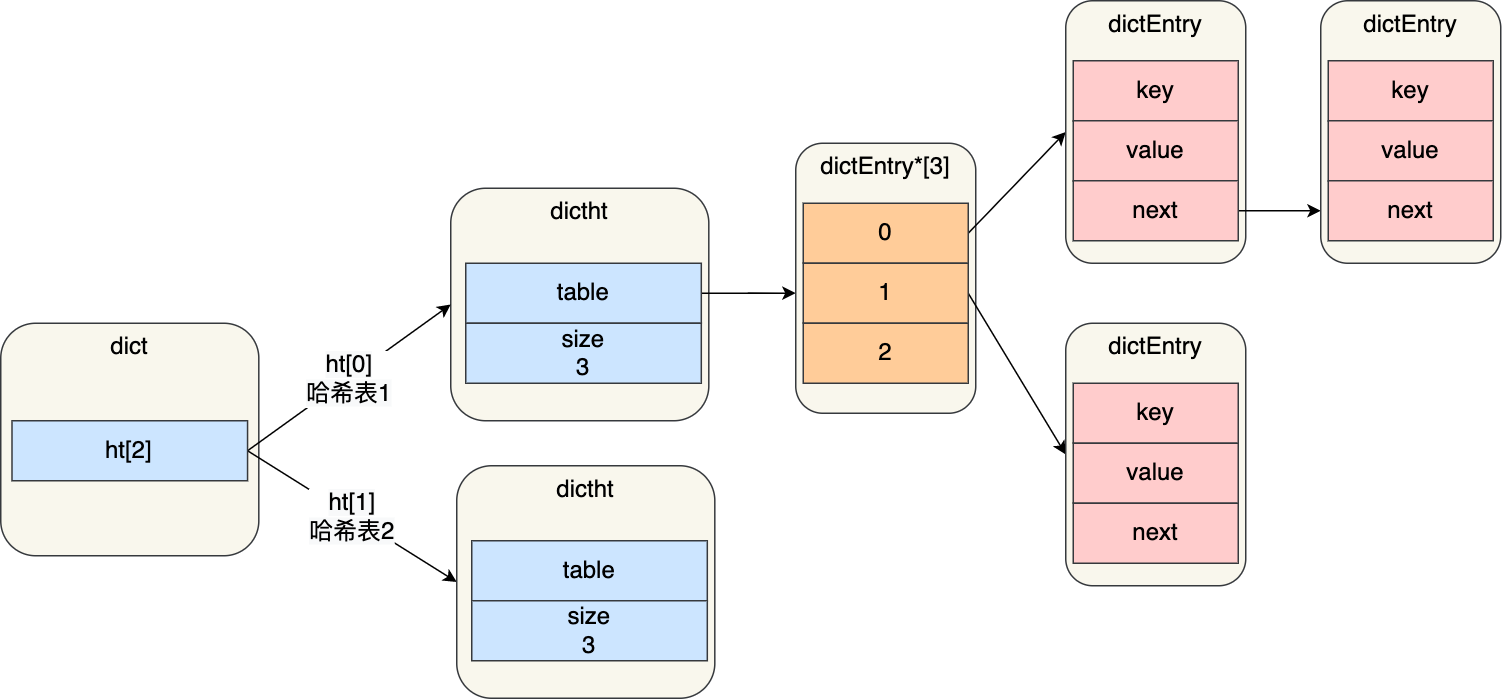
Redis 的哈希表结构如下:
typedef struct dictht {
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值
unsigned long sizemask;
//该哈希表已有的节点数量
unsigned long used;
} dictht;
可以看到,哈希表是一个数组(dictEntry **table),数组的每个元素是一个指向「哈希表节点(dictEntry)」的指针。

哈希表节点的结构如下:
typedef struct dictEntry {
//键值对中的键
void *key;
//键值对中的值
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
//指向下一个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
dictEntry 结构里不仅包含指向键和值的指针,还包含了指向下一个哈希表节点的指针,这个指针可以将多个哈希值相同的键值对链接起来,以此来解决哈希冲突的问题,这就是链式哈希。
另外,这里还跟你提一下,dictEntry 结构里键值对中的值是一个「联合体 v」定义的,因此,键值对中的值可以是一个指向实际值的指针,或者是一个无符号的 64 位整数或有符号的 64 位整数或double 类的值。这么做的好处是可以节省内存空间,因为当「值」是整数或浮点数时,就可以将值的数据内嵌在 dictEntry 结构里,无需再用一个指针指向实际的值,从而节省了内存空间。
哈希冲突
哈希表实际上是一个数组,数组里多每一个元素就是一个哈希桶。
当一个键值对的键经过 Hash 函数计算后得到哈希值,再将(哈希值 % 哈希表大小)取模计算,得到的结果值就是该 key-value 对应的数组元素位置,也就是第几个哈希桶。
什么是哈希冲突呢?
举个例子,有一个可以存放 8 个哈希桶的哈希表。key1 经过哈希函数计算后,再将「哈希值 % 8 」进行取模计算,结果值为 1,那么就对应哈希桶 1,类似的,key9 和 key10 分别对应哈希桶 1 和桶 6。

此时,key1 和 key9 对应到了相同的哈希桶中,这就发生了哈希冲突。
因此,**当有两个以上数量的 kay 被分配到了哈希表中同一个哈希桶上时,此时称这些 key 发生了冲突。
链式哈希
Redis 采用了「 链式哈希 」的方法来解决哈希冲突。
链式哈希是怎么实现的?
实现的方式就是每个哈希表节点都有一个 next 指针,用于指向下一个哈希表节点,因此多个哈希表节点可以用 next 指针构成一个单项链表, 被分配到同一个哈希桶上的多个节点可以用这个单项链表连接起来 ,这样就解决了哈希冲突。
还是用前面的哈希冲突例子,key1 和 key9 经过哈希计算后,都落在同一个哈希桶,链式哈希的话,key1 就会通过 next 指针指向 key9,形成一个单向链表。

不过,链式哈希局限性也很明显,随着链表长度的增加,在查询这一位置上的数据的耗时就会增加,毕竟链表的查询的时间复杂度是 O(n)。
要想解决这一问题,就需要进行 rehash,也就是对哈希表的大小进行扩展。
接下来,看看 Redis 是如何实现的 rehash 的。
rehash
哈希表结构设计的这一小节,我给大家介绍了 Redis 使用 dictht 结构体表示哈希表。不过,在实际使用哈希表时,Redis 定义一个 dict 结构体,这个结构体里定义了 两个哈希表(ht[2]) 。
typedef struct dict {
…
//两个Hash表,交替使用,用于rehash操作
dictht ht[2];
…
} dict;
之所以定义了 2 个哈希表,是因为进行 rehash 的时候,需要用上 2 个哈希表了。
在正常服务请求阶段,插入的数据,都会写入到「哈希表 1」,此时的「哈希表 2 」 并没有被分配空间。
随着数据逐步增多,触发了 rehash 操作,这个过程分为三步:
- 给「哈希表 2」 分配空间,一般会比「哈希表 1」 大 2 倍;
- 将「哈希表 1 」的数据迁移到「哈希表 2」 中;
- 迁移完成后,「哈希表 1 」的空间会被释放,并把「哈希表 2」 设置为「哈希表 1」,然后在「哈希表 2」 新创建一个空白的哈希表,为下次 rehash 做准备。
为了方便你理解,我把 rehash 这三个过程画在了下面这张图:
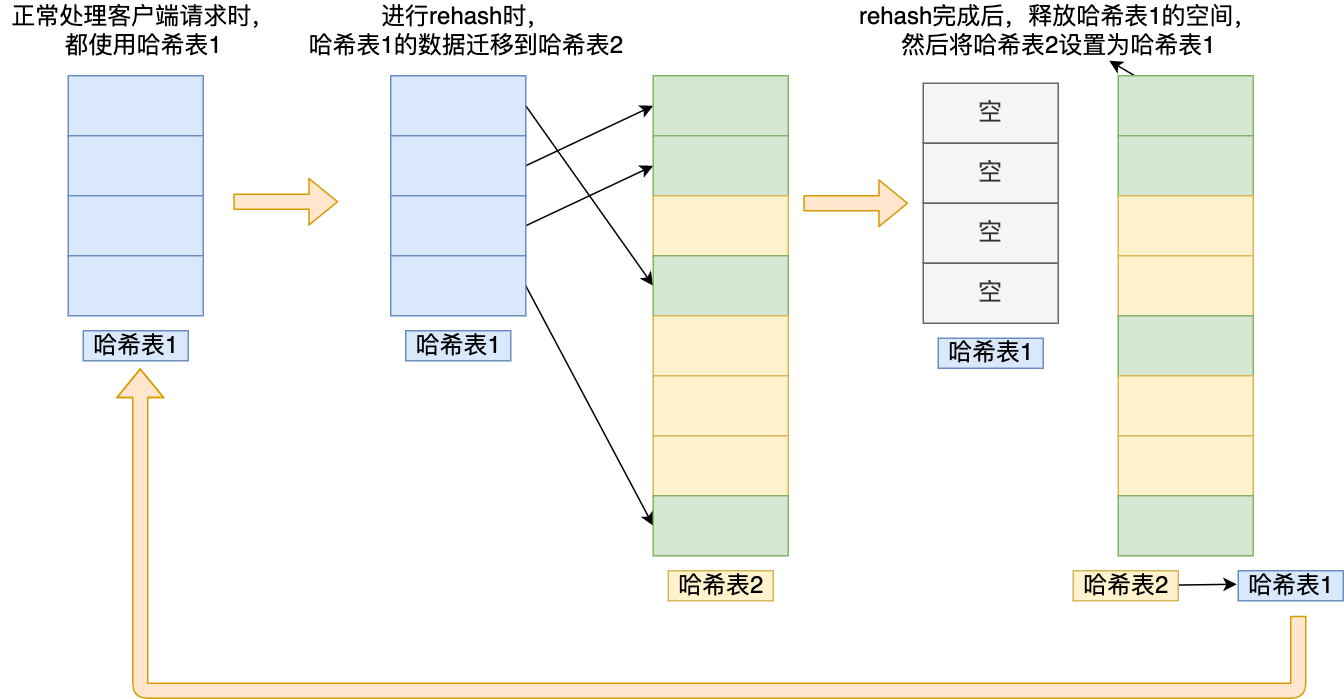
这个过程看起来简单,但是其实第二步很有问题, 如果「哈希表 1 」的数据量非常大,那么在迁移至「哈希表 2 」的时候,因为会涉及大量的数据拷贝,此时可能会对 Redis 造成阻塞,无法服务其他请求 。
渐进式 rehash
为了避免 rehash 在数据迁移过程中,因拷贝数据的耗时,影响 Redis 性能的情况,所以 Redis 采用了 渐进式 rehash ,也就是将数据的迁移的工作不再是一次性迁移完成,而是分多次迁移。
渐进式 rehash 步骤如下:
- 给「哈希表 2」 分配空间;
- 在 rehash 进行期间,每次哈希表元素进行新增、删除、查找或者更新操作时,Redis 除了会执行对应的操作之外,还会顺序将「哈希表 1 」中索引位置上的所有 key-value 迁移到「哈希表 2」 上 ;
- 随着处理客户端发起的哈希表操作请求数量越多,最终在某个时间点会把「哈希表 1 」的所有 key-value 迁移到「哈希表 2」,从而完成 rehash 操作。
这样就巧妙地把一次性大量数据迁移工作的开销,分摊到了多次处理请求的过程中,避免了一次性 rehash 的耗时操作。
在进行渐进式 rehash 的过程中,会有两个哈希表,所以在渐进式 rehash 进行期间,哈希表元素的删除、查找、更新等操作都会在这两个哈希表进行。
比如,查找一个 key 的值的话,先会在「哈希表 1」 里面进行查找,如果没找到,就会继续到哈希表 2 里面进行找到。
另外,在渐进式 rehash 进行期间,新增一个 key-value 时,会被保存到「哈希表 2 」里面,而「哈希表 1」 则不再进行任何添加操作,这样保证了「哈希表 1 」的 key-value 数量只会减少,随着 rehash 操作的完成,最终「哈希表 1 」就会变成空表。
rehash 触发条件
介绍了 rehash 那么多,还没说什么时情况下会触发 rehash 操作呢?
rehash 的触发条件跟**负载因子(load factor)**有关系。
负载因子可以通过下面这个公式计算:

触发 rehash 操作的条件,主要有两个:
- 当负载因子大于等于 1 ,并且 Redis 没有在执行 bgsave 命令或者 bgrewiteaof 命令,也就是没有执行 RDB 快照或没有进行 AOF 重写的时候,就会进行 rehash 操作。
- 当负载因子大于等于 5 时,此时说明哈希冲突非常严重了,不管有没有有在执行 RDB 快照或 AOF 重写,都会强制进行 rehash 操作。
5.整数集合
整数集合是 Set 对象的底层实现之一。当一个 Set 对象只包含整数值元素,并且元素数量不大时,就会使用整数集这个数据结构作为底层实现。
整数集合结构设计
整数集合本质上是一块连续内存空间,它的结构定义如下:
typedef struct intset {
//编码方式
uint32_t encoding;
//集合包含的元素数量
uint32_t length;
//保存元素的数组
int8_t contents[];
} intset;
可以看到,保存元素的容器是一个 contents 数组,虽然 contents 被声明为 int8_t 类型的数组,但是实际上 contents 数组并不保存任何 int8_t 类型的元素,contents 数组的真正类型取决于 intset 结构体里的 encoding 属性的值。比如:
- 如果 encoding 属性值为 INTSET_ENC_INT16,那么 contents 就是一个 int16_t 类型的数组,数组中每一个元素的类型都是 int16_t;
- 如果 encoding 属性值为 INTSET_ENC_INT32,那么 contents 就是一个 int32_t 类型的数组,数组中每一个元素的类型都是 int32_t;
- 如果 encoding 属性值为 INTSET_ENC_INT64,那么 contents 就是一个 int64_t 类型的数组,数组中每一个元素的类型都是 int64_t;
不同类型的 contents 数组,意味着数组的大小也会不同。
整数集合的升级操作
整数集合会有一个升级规则,就是当我们将一个新元素加入到整数集合里面,如果新元素的类型(int32_t)比整数集合现有所有元素的类型(int16_t)都要长时,整数集合需要先进行升级,也就是按新元素的类型(int32_t)扩展 contents 数组的空间大小,然后才能将新元素加入到整数集合里,当然升级的过程中,也要维持整数集合的有序性。
整数集合升级的过程不会重新分配一个新类型的数组,而是在原本的数组上扩展空间,然后在将每个元素按间隔类型大小分割,如果 encoding 属性值为 INTSET_ENC_INT16,则每个元素的间隔就是 16 位。
举个例子,假设有一个整数集合里有 3 个类型为 int16_t 的元素。

现在,往这个整数集合中加入一个新元素 65535,这个新元素需要用 int32_t 类型来保存,所以整数集合要进行升级操作,首先需要为 contents 数组扩容, 在原本空间的大小之上再扩容多 80 位(4x32-3x16=80),这样就能保存下 4 个类型为 int32_t 的元素 。

扩容完 contents 数组空间大小后,需要将之前的三个元素转换为 int32_t 类型,并将转换后的元素放置到正确的位上面,并且需要维持底层数组的有序性不变,整个转换过程如下:

整数集合升级有什么好处呢?
如果要让一个数组同时保存 int16_t、int32_t、int64_t 类型的元素,最简单做法就是直接使用 int64_t 类型的数组。不过这样的话,当如果元素都是 int16_t 类型的,就会造成内存浪费的情况。
整数集合升级就能避免这种情况,如果一直向整数集合添加 int16_t 类型的元素,那么整数集合的底层实现就一直是用 int16_t 类型的数组,只有在我们要将 int32_t 类型或 int64_t 类型的元素添加到集合时,才会对数组进行升级操作。
因此,整数集合升级的好处是 节省内存资源 。
整数集合支持降级操作吗?
不支持降级操作 ,一旦对数组进行了升级,就会一直保持升级后的状态。比如前面的升级操作的例子,如果删除了 65535 元素,整数集合的数组还是 int32_t 类型的,并不会因此降级为 int16_t 类型。
6.跳表
Redis 只有 Zset 对象的底层实现用到了跳表,跳表的优势是能支持平均 O(logN) 复杂度的节点查找。
zset 结构体里有两个数据结构:一个是跳表,一个是哈希表。这样的好处是既能进行高效的范围查询,也能进行高效单点查询。
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
Zset 对象在执行数据插入或是数据更新的过程中,会依次在跳表和哈希表中插入或更新相应的数据,从而保证了跳表和哈希表中记录的信息一致。
Zset 对象能支持范围查询(如 ZRANGEBYSCORE 操作),这是因为它的数据结构设计采用了跳表,而又能以常数复杂度获取元素权重(如 ZSCORE 操作),这是因为它同时采用了哈希表进行索引。
可能很多人会奇怪,为什么我开头说 Zset 对象的底层数据结构是「压缩列表」或者「跳表」,而没有说哈希表呢?
Zset 对象在使用跳表作为数据结构的时候,是使用由「哈希表+跳表」组成的 struct zset,但是我们讨论的时候,都会说跳表是 Zset 对象的底层数据结构,而不会提及哈希表,是因为 struct zset 中的哈希表只是用于以常数复杂度获取元素权重,大部分操作都是跳表实现的。
接下来,详细的说下跳表。
跳表结构设计
链表在查找元素的时候,因为需要逐一查找,所以查询效率非常低,时间复杂度是O(N),于是就出现了跳表。 跳表是在链表基础上改进过来的,实现了一种「多层」的有序链表 ,这样的好处是能快读定位数据。
那跳表长什么样呢?我这里举个例子,下图展示了一个层级为 3 的跳表。

图中头节点有 L0~L2 三个头指针,分别指向了不同层级的节点,然后每个层级的节点都通过指针连接起来:
- L0 层级共有 5 个节点,分别是节点1、2、3、4、5;
- L1 层级共有 3 个节点,分别是节点 2、3、5;
- L2 层级只有 1 个节点,也就是节点 3 。
如果我们要在链表中查找节点 4 这个元素,只能从头开始遍历链表,需要查找 4 次,而使用了跳表后,只需要查找 2 次就能定位到节点 4,因为可以在头节点直接从 L2 层级跳到节点 3,然后再往前遍历找到节点 4。
可以看到,这个查找过程就是在多个层级上跳来跳去,最后定位到元素。当数据量很大时,跳表的查找复杂度就是 O(logN)。
那跳表节点是怎么实现多层级的呢?这就需要看「跳表节点」的数据结构了,如下:
typedef struct zskiplistNode {
//Zset 对象的元素值
sds ele;
//元素权重值
double score;
//后向指针
struct zskiplistNode *backward;
//节点的level数组,保存每层上的前向指针和跨度
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
Zset 对象要同时保存「元素」和「元素的权重」,对应到跳表节点结构里就是 sds 类型的 ele 变量和 double 类型的 score 变量。每个跳表节点都有一个后向指针(struct zskiplistNode *backward),指向前一个节点,目的是为了方便从跳表的尾节点开始访问节点,这样倒序查找时很方便。
跳表是一个带有层级关系的链表,而且每一层级可以包含多个节点,每一个节点通过指针连接起来,实现这一特性就是靠跳表节点结构体中的 zskiplistLevel 结构体类型的 level 数组 。
level 数组中的每一个元素代表跳表的一层,也就是由 zskiplistLevel 结构体表示,比如 leve[0] 就表示第一层,leve[1] 就表示第二层。zskiplistLevel 结构体里定义了「指向下一个跳表节点的指针」和「跨度」,跨度时用来记录两个节点之间的距离。
比如,下面这张图,展示了各个节点的跨度。


第一眼看到跨度的时候,以为是遍历操作有关,实际上并没有任何关系,遍历操作只需要用前向指针(struct zskiplistNode *forward)就可以完成了。
跨度实际上是为了计算这个节点在跳表中的排位 。具体怎么做的呢?因为跳表中的节点都是按序排列的,那么计算某个节点排位的时候,从头节点点到该结点的查询路径上,将沿途访问过的所有层的跨度累加起来,得到的结果就是目标节点在跳表中的排位。
举个例子,查找图中节点 3 在跳表中的排位,从头节点开始查找节点 3,查找的过程只经过了一个层(L2),并且层的跨度是 3,所以节点 3 在跳表中的排位是 3。
另外,图中的头节点其实也是 zskiplistNode 跳表节点,只不过头节点的后向指针、权重、元素值都没有用到,所以图中省略了这部分。
问题来了,由谁定义哪个跳表节点是头节点呢?这就介绍「跳表」结构体了,如下所示:
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
跳表结构里包含了:
- 跳表的头尾节点,便于在O(1)时间复杂度内访问跳表的头节点和尾节点;
- 跳表的长度,便于在O(1)时间复杂度获取跳表节点的数量;
- 跳表的最大层数,便于在O(1)时间复杂度获取跳表中层高最大的那个节点的层数量;
跳表节点查询过程
查找一个跳表节点的过程时,跳表会从头节点的最高层开始,逐一遍历每一层。在遍历某一层的跳表节点时,会用跳表节点中的 SDS 类型的元素和元素的权重来进行判断,共有两个判断条件:
- 如果当前节点的权重「小于」要查找的权重时,跳表就会访问该层上的下一个节点。
- 如果当前节点的权重「等于」要查找的权重时,并且当前节点的 SDS 类型数据「小于」要查找的数据时,跳表就会访问该层上的下一个节点。
如果上面两个条件都不满足,或者下一个节点为空时,跳表就会使用目前遍历到的节点的 level 数组里的下一层指针,然后沿着下一层指针继续查找,这就相当于跳到了下一层接着查找。
举个例子,下图有个 3 层级的跳表。


如果要查找「元素:abcd,权重:4」的节点,查找的过程是这样的:
- 先从头节点的最高层开始,L2 指向了「元素:abc,权重:3」节点,这个节点的权重比要查找节点的小,所以要访问该层上的下一个节点;
- 但是该层的下一个节点是空节点( leve[2]指向的是空节点),于是就会跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve[1];
- 「元素:abc,权重:3」节点的 leve[1] 的下一个指针指向了「元素:abcde,权重:4」的节点,然后将其和要查找的节点比较。虽然「元素:abcde,权重:4」的节点的权重和要查找的权重相同,但是当前节点的 SDS 类型数据「大于」要查找的数据,所以会继续跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve[0];
- 「元素:abc,权重:3」节点的 leve[0] 的下一个指针指向了「元素:abcd,权重:4」的节点,该节点正是要查找的节点,查询结束。
跳表节点层数设置
跳表的相邻两层的节点数量的比例会影响跳表的查询性能。
举个例子,下图的跳表,第二层的节点数量只有 1 个,而第一层的节点数量有 6 个。

这时,如果想要查询节点 6,那基本就跟链表的查询复杂度一样,就需要在第一层的节点中依次顺序查找,复杂度就是 O(N) 了。所以,为了降低查询复杂度,我们就需要维持相邻层结点数间的关系。
跳表的相邻两层的节点数量最理想的比例是 2:1,查找复杂度可以降低到 O(logN) 。
下图的跳表就是,相邻两层的节点数量的比例是 2 : 1。

那怎样才能维持相邻两层的节点数量的比例为 2 : 1 呢?
如果采用新增节点或者删除节点时,来调整跳表节点以维持比例的方法的话,会带来额外的开销。
Redis 则采用一种巧妙的方法是, 跳表在创建节点的时候,随机生成每个节点的层数 ,并没有严格维持相邻两层的节点数量比例为 2 : 1 的情况。
具体的做法是, 跳表在创建节点时候,会生成范围为[0-1]的一个随机数,如果这个随机数小于 0.25(相当于概率 25%),那么层数就增加 1 层,然后继续生成下一个随机数,直到随机数的结果大于 0.25 结束,最终确定该节点的层数 。
这样的做法,相当于每增加一层的概率不超过 25%,层数越高,概率越低,层高最大限制是 64。
为什么用跳表而不用平衡树?
这里插一个常见的面试题:为什么 Zset 的实现用跳表而不用平衡树(如 AVL树、红黑树等)?
对于这个问题 (opens new window),Redis的作者 @antirez 是怎么说的:
There are a few reasons:
- They are not very memory intensive. It’s up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
- A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
- They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
简单翻译一下,主要是从内存占用、对范围查找的支持、实现难易程度这三方面总结的原因:
- 它们不是非常内存密集型的。基本上由你决定。改变关于节点具有给定级别数的概率的参数将使其比 btree 占用更少的内存。
- Zset 经常需要执行 ZRANGE 或 ZREVRANGE 的命令,即作为链表遍历跳表。通过此操作,跳表的缓存局部性至少与其他类型的平衡树一样好。
- 它们更易于实现、调试等。例如,由于跳表的简单性,我收到了一个补丁(已经在Redis master中),其中扩展了跳表,在 O(log(N) 中实现了 ZRANK。它只需要对代码进行少量修改。
我再详细补充点:
- 从内存占用上来比较,跳表比平衡树更灵活一些 。平衡树每个节点包含 2 个指针(分别指向左右子树),而跳表每个节点包含的指针数目平均为 1/(1-p),具体取决于参数 p 的大小。如果像 Redis里的实现一样,取 p=1/4,那么平均每个节点包含 1.33 个指针,比平衡树更有优势。
- 在做范围查找的时候,跳表比平衡树操作要简单 。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在跳表上进行范围查找就非常简单,只需要在找到小值之后,对第 1 层链表进行若干步的遍历就可以实现。
- 从算法实现难度上来比较,跳表比平衡树要简单得多 。平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而跳表的插入和删除只需要修改相邻节点的指针,操作简单又快速。
7.quicklist
quicklist 的结构体跟链表的结构体类似,都包含了表头和表尾,区别在于 quicklist 的节点是 quicklistNode。
typedef struct quicklist {
//quicklist的链表头
quicklistNode *head; //quicklist的链表头
//quicklist的链表头
quicklistNode *tail;
//所有压缩列表中的总元素个数
unsigned long count;
//quicklistNodes的个数
unsigned long len;
...
} quicklist;
接下来看看,quicklistNode 的结构定义:
typedef struct quicklistNode {
//前一个quicklistNode
struct quicklistNode *prev; //前一个quicklistNode
//下一个quicklistNode
struct quicklistNode *next; //后一个quicklistNode
//quicklistNode指向的压缩列表
unsigned char *zl;
//压缩列表的的字节大小
unsigned int sz;
//压缩列表的元素个数
unsigned int count : 16; //ziplist中的元素个数
....
} quicklistNode;
可以看到,quicklistNode 结构体里包含了前一个节点和下一个节点指针,这样每个 quicklistNode 形成了一个双向链表。但是链表节点的元素不再是单纯保存元素值,而是保存了一个压缩列表,所以 quicklistNode 结构体里有个指向压缩列表的指针 *zl。
我画了一张图,方便你理解 quicklist 数据结构。

在向 quicklist 添加一个元素的时候,不会像普通的链表那样,直接新建一个链表节点。而是会检查插入位置的压缩列表是否能容纳该元素,如果能容纳就直接保存到 quicklistNode 结构里的压缩列表,如果不能容纳,才会新建一个新的 quicklistNode 结构。
quicklist 会控制 quicklistNode 结构里的压缩列表的大小或者元素个数,来规避潜在的连锁更新的风险,但是这并没有完全解决连锁更新的问题。
8.listpark
quicklist 虽然通过控制 quicklistNode 结构里的压缩列表的大小或者元素个数,来减少连锁更新带来的性能影响,但是并没有完全解决连锁更新的问题。
因为 quicklistNode 还是用了压缩列表来保存元素,压缩列表连锁更新的问题,来源于它的结构设计,所以要想彻底解决这个问题,需要设计一个新的数据结构。
于是,Redis 在 5.0 新设计一个数据结构叫 listpack,目的是替代压缩列表,它最大特点是 listpack 中每个节点不再包含前一个节点的长度了,压缩列表每个节点正因为需要保存前一个节点的长度字段,就会有连锁更新的隐患。
我看了 Redis 的 Github,在最新 6.2 发行版本中,Redis Hash 对象、ZSet 对象的底层数据结构的压缩列表还未被替换成 listpack,而 Redis 的最新代码(还未发布版本)已经将所有用到压缩列表底层数据结构的 Redis 对象替换成 listpack 数据结构来实现,估计不久将来,Redis 就会发布一个将压缩列表为 listpack 的发行版本 。
listpack 结构设计
listpack 采用了压缩列表的很多优秀的设计,比如还是用一块连续的内存空间来紧凑地保存数据,并且为了节省内存的开销,listpack 节点会采用不同的编码方式保存不同大小的数据。
我们先看看 listpack 结构:

listpack 头包含两个属性,分别记录了 listpack 总字节数和元素数量,然后 listpack 末尾也有个结尾标识。图中的 listpack entry 就是 listpack 的节点了。
每个 listpack 节点结构如下:

主要包含三个方面内容:
- encoding,定义该元素的编码类型,会对不同长度的整数和字符串进行编码;
- data,实际存放的数据;
- len,encoding+data的总长度;
可以看到, listpack 没有压缩列表中记录前一个节点长度的字段了,listpack 只记录当前节点的长度,当我们向 listpack 加入一个新元素的时候,不会影响其他节点的长度字段的变化,从而避免了压缩列表的连锁更新问题 。
redis的内存淘汰策略
过期删除策略,是删除已过期的 key,而当 Redis 的运行内存已经超过 Redis 设置的最大内存之后,则会使用内存淘汰策略删除符合条件的 key,以此来保障 Redis 高效的运行。
如何设置redis最大内存
在配置文件 redis.conf 中,可以通过参数 maxmemory <bytes> 来设定最大运行内存,只有在 Redis 的运行内存达到了我们设置的最大运行内存,才会触发内存淘汰策略。 不同位数的操作系统,maxmemory 的默认值是不同的:
- 在 64 位操作系统中,maxmemory 的默认值是 0,表示没有内存大小限制,那么不管用户存放多少数据到 Redis 中,Redis 也不会对可用内存进行检查,直到 Redis 实例因内存不足而崩溃也无作为。
- 在 32 位操作系统中,maxmemory 的默认值是 3G,因为 32 位的机器最大只支持 4GB 的内存,而系统本身就需要一定的内存资源来支持运行,所以 32 位操作系统限制最大 3 GB 的可用内存是非常合理的,这样可以避免因为内存不足而导致 Redis 实例崩溃
redis内存淘汰策略有哪些?
一共有8种内存淘汰策略。8种分为不进行数据淘汰和进行数据淘汰两种。
1、不进行数据淘汰的策略
noeviction (Redis3.0之后,默认的内存淘汰策略) :它表示当运行内存超过最大设置内存时,不淘汰任何数据,而是不再提供服务,直接返回错误。
2、进行数据淘汰的策略
针对「进行数据淘汰」这一类策略,又可以细分为「在设置了过期时间的数据中进行淘汰」和「在所有数据范围内进行淘汰」这两类策略。
在设置了过期时间的数据中进行淘汰:
- volatile-random :随机淘汰设置了过期时间的任意键值;
- volatile-ttl :优先淘汰更早过期的键值。
- volatile-lru (Redis3.0 之前,默认的内存淘汰策略):淘汰所有设置了过期时间的键值中,最久未使用的键值;(根据访问时间来淘汰)
- volatile-lfu (Redis 4.0 后新增的内存淘汰策略):淘汰所有设置了过期时间的键值中,最少使用的键值;(根据访问次数来淘汰)
在所有数据范围内进行淘汰:
- allkeys-random :随机淘汰任意键值;
- allkeys-lru :淘汰整个键值中最久未使用的键值;
- allkeys-lfu (Redis 4.0 后新增的内存淘汰策略):淘汰整个键值中最少使用的键值。
如何查看内存淘汰策略
可以使用config get maxmemory-policy指令获取
127.0.0.1:6379> config get maxmemory-policy
1) "maxmemory-policy"
2) "noeviction"
可以看出,当前 Redis 使用的是 noeviction 类型的内存淘汰策略,它是 Redis 3.0 之后默认使用的内存淘汰策略,表示当运行内存超过最大设置内存时,不淘汰任何数据,但新增操作会报错。
如何修改内存淘汰策略
- 方式一:通过“
config set maxmemory-policy <策略>”命令设置。它的优点是设置之后立即生效,不需要重启 Redis 服务,缺点是重启 Redis 之后,设置就会失效。 - 方式二:通过修改 Redis 配置文件修改,设置“
maxmemory-policy <策略>”,它的优点是重启 Redis 服务后配置不会丢失,缺点是必须重启 Redis 服务,设置才能生效。
LRU和LFU算法的区别
LRU算法
LRU 全称是 Least Recently Used 翻译为 最近最少使用 ,会选择淘汰最近最少使用的数据。
传统 LRU 算法的实现是基于「链表」结构,链表中的元素按照操作顺序从前往后排列,最新操作的键会被移动到表头,当需要内存淘汰时,只需要删除链表尾部的元素即可,因为链表尾部的元素就代表最久未被使用的元素。
Redis 并没有使用这样的方式实现 LRU 算法,因为传统的 LRU 算法存在两个问题:
- 需要用链表管理所有的缓存数据,这会带来额外的空间开销;
- 当有数据被访问时,需要在链表上把该数据移动到头端,如果有大量数据被访问,就会带来很多链表移动操作,会很耗时,进而会降低 Redis 缓存性能。
redis实现LRU
Redis 实现的是一种 近似 LRU 算法 ,目的是为了更好的节约内存,它的 实现方式是在 Redis 的对象结构体中添加一个额外的字段,用于记录此数据的最后一次访问时间 。
当 Redis 进行内存淘汰时,会使用 随机采样的方式来淘汰数据 ,它是随机取 5 个值(此值可配置),然后 淘汰最久没有使用的那个 。
Redis 实现的 LRU 算法的优点:
- 不用为所有的数据维护一个大链表,节省了空间占用;
- 不用在每次数据访问时都移动链表项,提升了缓存的性能;
但是 LRU 算法有一个问题, 无法解决缓存污染问题 ,比如应用一次读取了大量的数据,而这些数据只会被读取这一次,那么这些数据会留存在 Redis 缓存中很长一段时间,造成缓存污染。
redis实现LFU
LFU 全称是 Least Frequently Used 翻译为**最近最不常用的,**LFU 算法是根据数据访问次数来淘汰数据的,它的核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。
所以, LFU 算法会记录每个数据的访问次数。当一个数据被再次访问时,就会增加该数据的访问次数。这样就解决了偶尔被访问一次之后,数据留存在缓存中很长一段时间的问题,相比于 LRU 算法也更合理一些。
LFU 算法相比于 LRU 算法的实现,多记录了「数据的访问频次」的信息。Redis 对象的结构如下:
typedef struct redisObject {
...
// 24 bits,用于记录对象的访问信息
unsigned lru:24;
...
} robj;
LRU和LFU结构区别:
在 LRU 算法中 ,Redis 对象头的 24 bits 的 lru 字段是用来记录 key 的访问时间戳,因此在 LRU 模式下,Redis可以根据对象头中的 lru 字段记录的值,来比较最后一次 key 的访问时间长,从而淘汰最久未被使用的 key。
在 LFU 算法中 ,Redis对象头的 24 bits 的 lru 字段被分成两段来存储,高 16bit 存储 ldt(Last Decrement Time),低 8bit 存储 logc(Logistic Counter)。
- ldt 是用来记录 key 的访问时间戳;
- logc 是用来记录 key 的访问频次,它的值越小表示使用频率越低,越容易淘汰,每个新加入的 key 的logc 初始值为 5。
注意,logc 并不是单纯的访问次数,而是访问频次(访问频率),因为 logc 会随时间推移而衰减的 。
在每次 key 被访问时,会先对 logc 做一个衰减操作,衰减的值跟前后访问时间的差距有关系,如果上一次访问的时间与这一次访问的时间差距很大,那么衰减的值就越大,这样实现的 LFU 算法是根据访问频率来淘汰数据的,而不只是访问次数。访问频率需要考虑 key 的访问是多长时间段内发生的。key 的先前访问距离当前时间越长,那么这个 key 的访问频率相应地也就会降低,这样被淘汰的概率也会更大。
对 logc 做完衰减操作后,就开始对 logc 进行增加操作,增加操作并不是单纯的 + 1,而是根据概率增加,如果 logc 越大的 key,它的 logc 就越难再增加。
所以,Redis 在访问 key 时,对于 logc 是这样变化的:
- 先按照上次访问距离当前的时长,来对 logc 进行衰减;
- 然后,再按照一定概率增加 logc 的值
redis.conf 提供了两个配置项,用于调整 LFU 算法从而控制 logc 的增长和衰减:
lfu-decay-time用于调整 logc 的衰减速度,它是一个以分钟为单位的数值,默认值为1,lfu-decay-time 值越大,衰减越慢;lfu-log-factor用于调整 logc 的增长速度,lfu-log-factor 值越大,logc 增长越慢。
redis的缓存策略
由于数据存储受限,系统并不是将所有数据都需要存放到缓存中的,而 只是将其中一部分热点数据缓存起来 ,所以我们要设计一个热点数据动态缓存的策略。
热点数据动态缓存的策略总体思路: 通过数据最新访问时间来做排名,并过滤掉不常访问的数据,只留下经常访问的数据 。
以电商平台场景中的例子,现在要求只缓存用户经常访问的 Top 1000 的商品。具体细节如下:
- 先通过缓存系统做一个排序队列(比如存放 1000 个商品),系统会根据商品的访问时间,更新队列信息,越是最近访问的商品排名越靠前;
- 同时系统会定期过滤掉队列中排名最后的 200 个商品,然后再从数据库中随机读取出 200 个商品加入队列中;
- 这样当请求每次到达的时候,会先从队列中获取商品 ID,如果命中,就根据 ID 再从另一个缓存数据结构中读取实际的商品信息,并返回。
在 Redis 中可以用 zadd 方法和 zrange 方法来完成排序队列和获取 200 个商品的操作。
常见的缓存更新策略
常见的缓存更新策略共有3种:
- Cache Aside(旁路缓存)策略;
- Read/Write Through(读穿 / 写穿)策略;
- Write Back(写回)策略;
实际开发中,Redis 和 MySQL 的更新策略用的是 Cache Aside,另外两种策略应用不了。
Cache Aside(旁路缓存)策略
Cache Aside(旁路缓存)策略是最常用的,应用程序直接与「数据库、缓存」交互,并负责对缓存的维护,该策略又可以细分为「读策略」和「写策略」。

写策略的步骤:
- 先更新数据库中的数据,再删除缓存中的数据。
读策略的步骤:
- 如果读取的数据命中了缓存,则直接返回数据;
- 如果读取的数据没有命中缓存,则从数据库中读取数据,然后将数据写入到缓存,并且返回给用户。
注意,写策略的步骤的顺序顺序不能倒过来,即 不能先删除缓存再更新数据库 ,原因是在「读+写」并发的时候,会出现缓存和数据库的数据不一致性的问题。
举个例子,假设某个用户的年龄是 20,请求 A 要更新用户年龄为 21,所以它会删除缓存中的内容。这时,另一个请求 B 要读取这个用户的年龄,它查询缓存发现未命中后,会从数据库中读取到年龄为 20,并且写入到缓存中,然后请求 A 继续更改数据库,将用户的年龄更新为 21。

最终,该用户年龄在缓存中是 20(旧值),在数据库中是 21(新值),缓存和数据库的数据不一致。
为什么「先更新数据库再删除缓存」不会有数据不一致的问题?
继续用「读 + 写」请求的并发的场景来分析。
假如某个用户数据在缓存中不存在,请求 A 读取数据时从数据库中查询到年龄为 20,在未写入缓存中时另一个请求 B 更新数据。它更新数据库中的年龄为 21,并且清空缓存。这时请求 A 把从数据库中读到的年龄为 20 的数据写入到缓存中。

最终,该用户年龄在缓存中是 20(旧值),在数据库中是 21(新值),缓存和数据库数据不一致。 从上面的理论上分析,先更新数据库,再删除缓存也是会出现数据不一致性的问题, 但是在实际中,这个问题出现的概率并不高 。
因为缓存的写入通常要远远快于数据库的写入 ,所以在实际中很难出现请求 B 已经更新了数据库并且删除了缓存,请求 A 才更新完缓存的情况。而一旦请求 A 早于请求 B 删除缓存之前更新了缓存,那么接下来的请求就会因为缓存不命中而从数据库中重新读取数据,所以不会出现这种不一致的情况。
Cache Aside 策略适合读多写少的场景,不适合写多的场景 ,因为当写入比较频繁时,缓存中的数据会被频繁地清理,这样会对缓存的命中率有一些影响。如果业务对缓存命中率有严格的要求,那么可以考虑两种解决方案:
- 一种做法是在更新数据时也更新缓存,只是在更新缓存前先加一个分布式锁,因为这样在同一时间只允许一个线程更新缓存,就不会产生并发问题了。当然这么做对于写入的性能会有一些影响;
- 另一种做法同样也是在更新数据时更新缓存,只是给缓存加一个较短的过期时间,这样即使出现缓存不一致的情况,缓存的数据也会很快过期,对业务的影响也是可以接受。
Read/Write Through(读穿 / 写穿)策略
Read/Write Through(读穿 / 写穿)策略原则是应用程序只和缓存交互,不再和数据库交互,而是由缓存和数据库交互,相当于更新数据库的操作由缓存自己代理了。
1、Read Through 策略
先查询缓存中数据是否存在,如果存在则直接返回,如果不存在,则由缓存组件负责从数据库查询数据,并将结果写入到缓存组件,最后缓存组件将数据返回给应用。
2、Write Through 策略
当有数据更新的时候,先查询要写入的数据在缓存中是否已经存在:
- 如果缓存中数据已经存在,则更新缓存中的数据,并且由缓存组件同步更新到数据库中,然后缓存组件告知应用程序更新完成。
- 如果缓存中数据不存在,直接更新数据库,然后返回;
下面是 Read Through/Write Through 策略的示意图:
Read Through/Write Through 策略的特点是由缓存节点而非应用程序来和数据库打交道,在我们开发过程中相比 Cache Aside 策略要少见一些,原因是我们经常使用的分布式缓存组件,无论是 Memcached 还是 Redis 都不提供写入数据库和自动加载数据库中的数据的功能。而我们在使用本地缓存的时候可以考虑使用这种策略。
Write Back(写回)策略
Write Back(写回)策略在更新数据的时候,只更新缓存,同时将缓存数据设置为脏的,然后立马返回,并不会更新数据库。对于数据库的更新,会通过批量异步更新的方式进行。
实际上,Write Back(写回)策略也不能应用到我们常用的数据库和缓存的场景中,因为 Redis 并没有异步更新数据库的功能。
Write Back 是计算机体系结构中的设计,比如 CPU 的缓存、操作系统中文件系统的缓存都采用了 Write Back(写回)策略。
Write Back 策略特别适合写多的场景 ,因为发生写操作的时候, 只需要更新缓存,就立马返回了。比如,写文件的时候,实际上是写入到文件系统的缓存就返回了,并不会写磁盘。
但是带来的问题是,数据不是强一致性的,而且会有数据丢失的风险 ,因为缓存一般使用内存,而内存是非持久化的,所以一旦缓存机器掉电,就会造成原本缓存中的脏数据丢失。所以你会发现系统在掉电之后,之前写入的文件会有部分丢失,就是因为 Page Cache 还没有来得及刷盘造成的。
这里贴一张 CPU 缓存与内存使用 Write Back 策略的流程图:
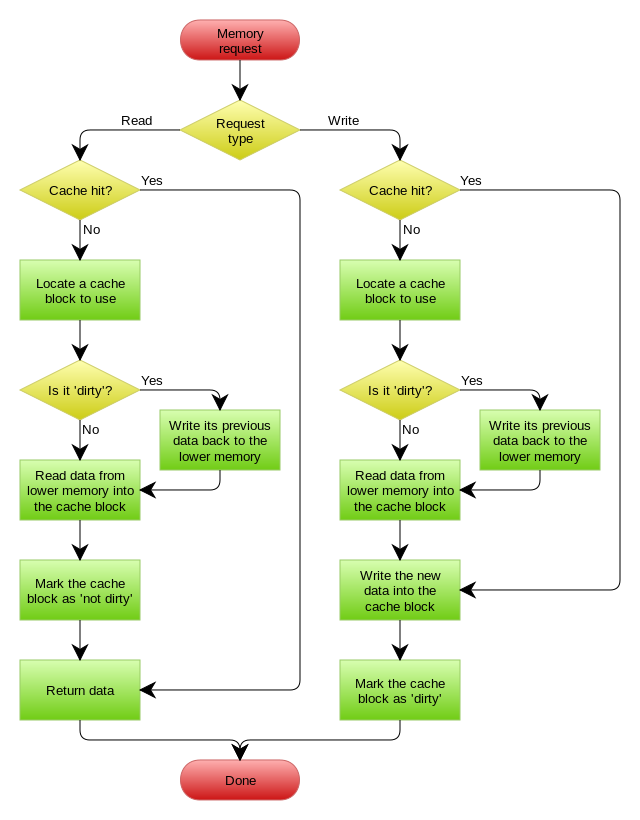
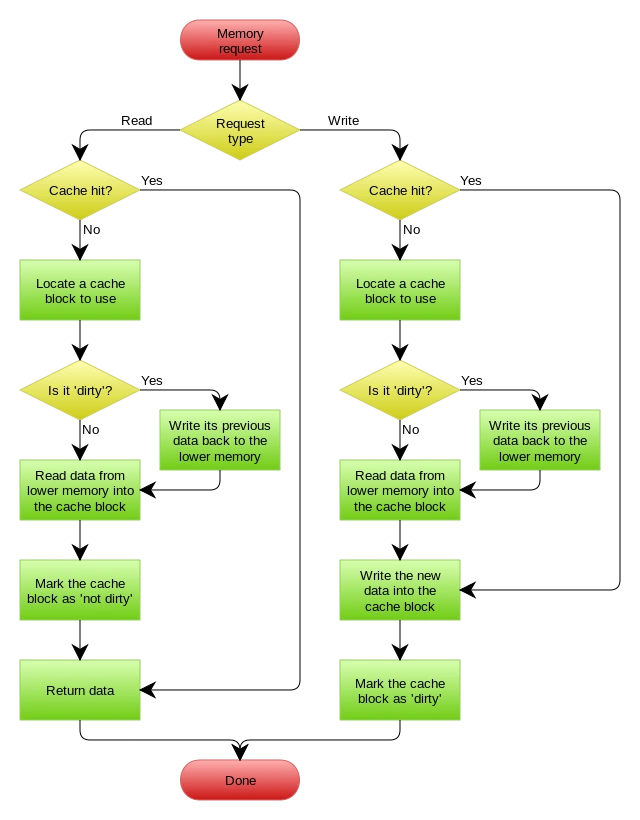
数据库和缓存如何保证一致性
结论:先更新数据库,再删除缓存,同时设置缓存失效的时间。能够最大程度保证数据库和缓存的一致性,但是仍然会出现不一致的情况,因此需要通过【消息队列来重试缓存的删除」,或者「订阅 MySQL binlog 再操作缓存」这两种方式来最终保证一致性。
先更新数据库还是先更新缓存?
由于引入了缓存,那么在数据更新时,不仅要更新数据库,而且要更新缓存,这两个更新操作存在前后的问题 :
- 先更新数据库,再更新缓存;
- 先更新缓存,再更新数据库;
先更新数据库再更新缓存
举个例子,比如「请求 A 」和「请求 B 」两个请求,同时更新「同一条」数据,则可能出现这样的顺序:

A 请求先将数据库的数据更新为 1,然后在更新缓存前,请求 B 将数据库的数据更新为 2,紧接着也把缓存更新为 2,然后 A 请求更新缓存为 1。
此时,数据库中的数据是 2,而缓存中的数据却是 1, 出现了缓存和数据库中的数据不一致的现象 。
先更新缓存再更新数据库
依然存在并发的问题

A 请求先将缓存的数据更新为 1,然后在更新数据库前,B 请求来了, 将缓存的数据更新为 2,紧接着把数据库更新为 2,然后 A 请求将数据库的数据更新为 1。
此时,数据库中的数据是 1,而缓存中的数据却是 2, 出现了缓存和数据库中的数据不一致的现象 。
所以, 无论是「先更新数据库,再更新缓存」,还是「先更新缓存,再更新数据库」,这两个方案都存在并发问题,当两个请求并发更新同一条数据的时候,可能会出现缓存和数据库中的数据不一致的现象 。
先更新数据库还是先删除缓存?
更新数据时,**不更新缓存,而是删除缓存中的数据。然后,到读取数据时,发现缓存中没了数据之后,再从数据库中读取数据,更新到缓存中。
这个策略是叫 Cache Aside 策略 ,中文是叫旁路缓存策略。
该策略又可以细分为「读策略」和「写策略」。
写策略的步骤:
- 更新数据库中的数据;
- 删除缓存中的数据。
读策略的步骤:
- 如果读取的数据命中了缓存,则直接返回数据;
- 如果读取的数据没有命中缓存,则从数据库中读取数据,然后将数据写入到缓存,并且返回给用户。
先删除缓存再更新数据库
假设某个用户的年龄是 20,请求 A 要更新用户年龄为 21,所以它会删除缓存中的内容。这时,另一个请求 B 要读取这个用户的年龄,它查询缓存发现未命中后,会从数据库中读取到年龄为 20,并且写入到缓存中,然后请求 A 继续更改数据库,将用户的年龄更新为 21。
最终,该用户年龄在缓存中是 20(旧值),在数据库中是 21(新值),缓存和数据库的数据不一致。
可以看到, 先删除缓存,再更新数据库,在「读 + 写」并发的时候,还是会出现缓存和数据库的数据不一致的问题 。
先更新数据库再删除缓存
假如某个用户数据在缓存中不存在,请求 A 读取数据时从数据库中查询到年龄为 20,在未写入缓存中时另一个请求 B 更新数据。它更新数据库中的年龄为 21,并且清空缓存。这时请求 A 把从数据库中读到的年龄为 20 的数据写入到缓存中。
最终,该用户年龄在缓存中是 20(旧值),在数据库中是 21(新值),缓存和数据库数据不一致。
从上面的理论上分析,先更新数据库,再删除缓存也是会出现数据不一致性的问题, 但是在实际中,这个问题出现的概率并不高 。
因为缓存的写入通常要远远快于数据库的写入 ,所以在实际中很难出现请求 B 已经更新了数据库并且删除了缓存,请求 A 才更新完缓存的情况。
而一旦请求 A 早于请求 B 删除缓存之前更新了缓存,那么接下来的请求就会因为缓存不命中而从数据库中重新读取数据,所以不会出现这种不一致的情况。
所以, 「先更新数据库 + 再删除缓存」的方案,是可以保证数据一致性的 。
而且阿旺为了确保万无一失,还给缓存数据加上了「 过期时间 」,就算在这期间存在缓存数据不一致,有过期时间来兜底,这样也能达到最终一致。
但是这种情况会出现一个问题,就是删除缓存失败时,会导致缓存中的数据是旧值 。
如何保证删除缓存能够成功?
通过消息队列或者订阅 MySQL binlog
- 重试机制。
- 订阅 MySQL binlog,再操作缓存。
重试机制
我们可以引入 消息队列 ,将第二个操作(删除缓存)要操作的数据加入到消息队列,由消费者来操作数据。
- 如果应用 删除缓存失败 ,可以从消息队列中重新读取数据,然后再次删除缓存,这个就是 重试机制 。当然,如果重试超过的一定次数,还是没有成功,我们就需要向业务层发送报错信息了。
- 如果 删除缓存成功 ,就要把数据从消息队列中移除,避免重复操作,否则就继续重试。
举个例子,来说明重试机制的过程。

订阅 MySQL binlog,再操作缓存
「 先更新数据库,再删缓存 」的策略的第一步是更新数据库,那么更新数据库成功,就会产生一条变更日志,记录在 binlog 里。
于是我们就可以通过订阅 binlog 日志,拿到具体要操作的数据,然后再执行缓存删除,阿里巴巴开源的 Canal 中间件就是基于这个实现的。
Canal 模拟 MySQL 主从复制的交互协议,把自己伪装成一个 MySQL 的从节点,向 MySQL 主节点发送 dump 请求,MySQL 收到请求后,就会开始推送 Binlog 给 Canal,Canal 解析 Binlog 字节流之后,转换为便于读取的结构化数据,供下游程序订阅使用。
下图是 Canal 的工作原理:

所以,如果要想保证「先更新数据库,再删缓存」策略第二个操作能执行成功,我们可以使用「消息队列来重试缓存的删除」,或者「订阅 MySQL binlog 再操作缓存」,这两种方法有一个共同的特点,都是采用异步操作缓存。
管道
yum install -y nc
[root@VM-4-2-centos ~]# echo -e "set k 99\nincr k\n get k" | nc localhost 6379
+OK
:100
$3
100
# 使用 nc localhost 6379来输入到redis中,能够批量输入命令
发布订阅
# 实时性数据:发布订阅 3天内的数据:sorted set 更老的数据:数据库全量
127.0.0.1:6379> help @pubsub
PSUBSCRIBE pattern [pattern ...]
summary: Listen for messages published to channels matching the given patterns
since: 2.0.0
PUBLISH channel message
summary: Post a message to a channel
since: 2.0.0
PUBSUB subcommand [argument [argument ...]]
summary: Inspect the state of the Pub/Sub subsystem
since: 2.8.0
PUNSUBSCRIBE [pattern [pattern ...]]
summary: Stop listening for messages posted to channels matching the given patterns
since: 2.0.0
SUBSCRIBE channel [channel ...]
summary: Listen for messages published to the given channels
since: 2.0.0
UNSUBSCRIBE [channel [channel ...]]
summary: Stop listening for messages posted to the given channels
since: 2.0.0
测试
# 订阅
127.0.0.1:6379> SUBSCRIBE test
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "test"
3) (integer) 1
1) "message"
2) "test"
3) "hello"
1) "message"
2) "test"
3) "\xe4\xbd\xa0\xe5\xa5\xbd\xe5\x95\x8a"
# 发布
127.0.0.1:6379> PUBLISH test hello
(integer) 1
127.0.0.1:6379> PUBLISH test "你好啊"
(integer) 1
事务
# 一个客户端的事务不会影响其他客户端的事务,因为redis是单线程(redis6.0以下)。谁的exec先到达,谁先执行事务
help
# 事务命令
127.0.0.1:6379> help @transactions
DISCARD -
summary: Discard all commands issued after MULTI
since: 2.0.0
EXEC -
summary: Execute all commands issued after MULTI
since: 1.2.0
MULTI -
summary: Mark the start of a transaction block
since: 1.2.0
UNWATCH -
summary: Forget about all watched keys
since: 2.2.0
WATCH key [key ...]
summary: Watch the given keys to determine execution of the MULTI/EXEC block
since: 2.2.0
MULTI 命令用于开启一个事务,它总是返回 OK 。 MULTI 执行之后, 客户端可以继续向服务器发送任意多条命令, 这些命令不会立即被执行, 而是被放到一个队列中, 当 EXEC命令被调用时, 所有队列中的命令才会被执行。
另一方面, 通过调用 DISCARD , 客户端可以清空事务队列, 并放弃执行事务。
测试
# 使用exec执行队列
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> set k12 1
QUEUED
127.0.0.1:6379> exec
1) OK
# discaed清除事务的队列
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> get k12
QUEUED
127.0.0.1:6379> DISCARD
OK
# watch监控k,如果k被更改,则事务不执行
127.0.0.1:6379> watch k··# 监控k并开启事务,但是不执行
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> keys *
QUEUED
127.0.0.1:6379> get k
QUEUED
127.0.0.1:6379> multi # 另一个客户端开启事务,修改k的值并且执行
OK
127.0.0.1:6379> set k sadadadsadsvdsv
QUEUED
127.0.0.1:6379> exec # 执行第一个客户端,发现事务直接不执行,因为监控的k被修改了
1) OK
127.0.0.1:6379> exec
(nil)
布隆过滤器
主要是解决缓存穿透。从缓存中查,查不到,然后从数据库中查也查不到。
映射函数和二进制向量,bitmap和映射函数一一对应,如果存在这个商品就放行,如果不存在就阻拦(随机放行)
布隆过滤是概率解决问题的,不可能百分百的阻挡,会大量减少放行,而且成本低。
安装
# make的时候报错
/usr/local/redis-6.2.5/RedisBloom/src/rm_tdigest.c:18:21: fatal error: tdigest.h: No such file or directory
#include "tdigest.h"
# 解决:切换到2.2版本
cd /usr/local/src
wget https://github.com/RedisBloom/RedisBloom/archive/master.zip
#下载完成后,如果没有unzip,需要先安装unzip
#yum install unzip
unzip master.zip
#解压完成后会出现一个RedisBloom-master的文件夹,进去
cd RedisBloom-master
#执行make命令需要gcc编译器,没有的需要先安装,如果报错就切换redis-bloom到2.2版本 yum install gcc
make
#make执行成功后会有一个redisbloom.so扩展库
#我安装redis的时候,make install的目录为/opt/redis6,所以我的redis命令都在/usr/local/software/redis-6.0.6/bin目录下,我把这个扩展库复制到/usr/local/software/redis-6.0.6目录下,方便使用
cp redisbloom.so /usr/local/software/redis-6.0.6/
# 重新启动redis,redisbloom.so 一定要是绝对路径
/usr/local/software/redis-6.0.6/bin/redis-server /etc/redis/6379.conf --loadmodule /usr/local/software/redis-6.0.6/redisbloom.so
redis-cli shutdown
安装完成后进入redis会有BF.xxxx一系列命令
127.0.0.1:6379> bf.add abc acc
(integer) 1
127.0.0.1:6379> BF.EXISTS abc acc
(integer) 1
127.0.0.1:6379> BF.EXISTS abc assss
(integer) 0
redis数据库和缓存的区别
缓存:实在内存中运行的,数据是可以丢的
数据库:持久化到本地,数据是不能丢的
作为缓存:热点数据,缓存应该随着访问而变化,只保存热点数据。涉及到key的有效期,随着访问,淘汰掉冷数据。
LRU,设置key过期时间,然后通过回收策略回收内存
# 最大内存
maxmemory <bytes>
# 内存满了之后采取的回收策略
maxmemory-policy noeviction
noeviction:返回错误当内存限制达到并且客户端尝试执行会让更多内存被使用的命令(大部分的写入指令,但DEL和几个例外)
allkeys-lru: 尝试回收最少使用的键(LRU),使得新添加的数据有空间存放。
volatile-lru: 尝试回收最少使用的键(LRU),但仅限于在过期集合的键,使得新添加的数据有空间存放。
allkeys-random: 回收随机的键使得新添加的数据有空间存放。
volatile-random: 回收随机的键使得新添加的数据有空间存放,但仅限于在过期集合的键。
volatile-ttl: 回收在过期集合的键,并且优先回收存活时间(TTL)较短的键,使得新添加的数据有空间存放。
# LFU:碰了多少次
# LRU:多久没碰
# key过期时间会随着访问延时吗?不会
# 设置过期时间
127.0.0.1:6379> set k1 a ex 20
OK
127.0.0.1:6379> ttl k1
(integer) 17
127.0.0.1:6379> ttl k1
(integer) 15
127.0.0.1:6379> get k1
"a"
127.0.0.1:6379> ttl k1
(integer) 6
127.0.0.1:6379> ttl k1
(integer) 2
127.0.0.1:6379> ttl k1
(integer) 1
127.0.0.1:6379> ttl k1 # -2代表结束了
(integer) -2
127.0.0.1:6379> get k1
(nil)
# 主动设置过期时间
127.0.0.1:6379> EXPIRE k1 5
(integer) 1
127.0.0.1:6379> ttl k1
(integer) 2
127.0.0.1:6379> ttl k1
(integer) -2
127.0.0.1:6379> get k1
(nil)
淘汰过期的key
Redis keys过期有两种方式:被动和主动方式。
当一些客户端尝试访问它时,key会被发现并主动的过期。
当然,这样是不够的,因为有些过期的keys,永远不会访问他们。 无论如何,这些keys应该过期,所以定时随机测试设置keys的过期时间。所有这些过期的keys将会从密钥空间删除。
具体就是Redis每秒10次做的事情:
1.测试随机的20个keys进行相关过期检测。
2.删除所有已经过期的keys。
3.如果有多于25%的keys过期,重复步奏1.
这是一个平凡的概率算法,基本上的假设是,我们的样本是这个密钥控件,并且我们不断重复过期检测,直到过期的keys的百分百低于25%,这意味着,在任何给定的时刻,最多会清除1/4的过期keys。
刷新过期时间
刷新过期时间
对已经有过期时间的key执行EXPIRE操作,将会更新它的过期时间。有很多应用有这种业务场景,例如记录会话的session。
持久化
rdb(redis database):快照 aof(append only file):日志
- AOF 文件的内容是写操作命令
- RDB 文件的内容是二进制数据
RDB
# 使用管道来实现。管道会触发一个子进程
# 使用linux的时候,子进程能看到父进程的信息吗?不能,进程之间是线程隔离的。
# 但是父进程也可以使子进程获取自己的数据,使用export命令。但是子进程的修改不会影响到父进程,
同时父进程的修改也不会破坏子进程,比如子进程休眠,父进程修改变量值,子进程休眠完获取的值是修改之前的。
# 那么创建子线程的速度是多大?如果父进程是redis,内存数据是10G?所以使用子进程来创建rdb,影响的因素一是速度,
二是内存空间。
# 使用fork()来创建子进程,速度快,空间小。当fork()子进程的时候,拷贝的是指针,
后面采用copyOnWrite写时复制,创建子进程时并不发生复制。
# 脚本在后台运行 ./test.sh &
# 管道测试
[root@VM-4-2-centos ~]# num=0
[root@VM-4-2-centos ~]# ((num++))
[root@VM-4-2-centos ~]# echo $num
1
[root@VM-4-2-centos ~]# ((num++)) | echo ok
ok
[root@VM-4-2-centos ~]# echo $num
1
[root@VM-4-2-centos ~]# echo $$ # 两个$$代表取当前进程号
9170
[root@VM-4-2-centos ~]# echo $BASHPID # 同时代表取当前进程号
9170
[root@VM-4-2-centos ~]# echo $$ | more # 出现这种情况是因为$$的优先级大于管道符|,所以实际上先拿到9170,然后在通过管道传过去
9170
[root@VM-4-2-centos ~]# echo $BASHPID | more # 展示的是子进程,把$BASHPID先传过去,然后进行替换成子进程的PID
30731
# 验证子进程是否可以获取父进程的信息
[root@VM-4-2-centos ~]# /bin/bash # 进入一个子bash
[root@VM-4-2-centos ~]# pstree
systemd─┬─YDLive─┬─YDService─┬─sh───8*[{sh}]
├─sshd─┬─sshd─┬─bash───sleep
│ │ ├─bash───bash───pstree # 这里子bash。他的父进程也是一个bash
│ │ └─bash───top
│ └─sshd───6*[sftp-server]
[root@VM-4-2-centos ~]# echo $num # 打印服进程的num
# 发现结果是null,说明子进程无法获取父进程的信息
[root@VM-4-2-centos ~]# exit # 退出子bash,进入父bash
exit
[root@VM-4-2-centos ~]# echo $num # 打印num
1
# 试验,父进程使子进程使用变量
[root@VM-4-2-centos ~]# export num
[root@VM-4-2-centos ~]# echo $num
1
[root@VM-4-2-centos ~]# /bin/bash
[root@VM-4-2-centos ~]# echo $num # 子进程获取到数据
1
[root@VM-4-2-centos ~]# ((num++))
[root@VM-4-2-centos ~]# echo $num
2
[root@VM-4-2-centos ~]# exit
exit
[root@VM-4-2-centos ~]# echo $num
1
如何生成RDB文件
有save和bgsave两种方式。区别就在于是否在「主线程」里执行:
- 执行了 save 命令,就会在主线程生成 RDB 文件,由于和执行操作命令在同一个线程,所以如果写入 RDB 文件的时间太长, 会阻塞主线程 ;
- 执行了 bgsave 命令,会创建一个子进程来生成 RDB 文件,这样可以 避免主线程的阻塞 ;、
RDB 文件的加载工作是在服务器启动时自动执行的,Redis 并没有提供专门用于加载 RDB 文件的命令。
Redis 还可以通过配置文件的选项来实现每隔一段时间自动执行一次 bgsave 命令,默认会提供以下配置:
save 900 1
save 300 10
save 60 10000
别看选项名叫 save,实际上执行的是 bgsave 命令,也就是会创建子进程来生成 RDB 快照文件。
只要满足上面条件的任意一个,就会执行 bgsave,它们的意思分别是:
- 900 秒之内,对数据库进行了至少 1 次修改;
- 300 秒之内,对数据库进行了至少 10 次修改;
- 60 秒之内,对数据库进行了至少 10000 次修改。
这里提一点,Redis 的快照是 全量快照 ,也就是说每次执行快照,都是把内存中的「所有数据」都记录到磁盘中。
所以可以认为,执行快照是一个比较重的操作,如果频率太频繁,可能会对 Redis 性能产生影响。如果频率太低,服务器故障时,丢失的数据会更多。
通常可能设置至少 5 分钟才保存一次快照,这时如果 Redis 出现宕机等情况,则意味着最多可能丢失 5 分钟数据。
这就是 RDB 快照的缺点,在服务器发生故障时,丢失的数据会比 AOF 持久化的方式更多,因为 RDB 快照是全量快照的方式,因此执行的频率不能太频繁,否则会影响 Redis 性能,而 AOF 日志可以以秒级的方式记录操作命令,所以丢失的数据就相对更少
save和bgsave。阻塞式:save命令,服务器需要关机维护时,使用save命令,确保RDB期间不会有新的写入 非阻塞式:bqsave,服务器正常运行时使用bqsave,保证RDB期间服务仍然可用
配置文件
# save ""
如果是save "" 代表关闭rdb
save 900 1 # 900秒 1次修改
save 300 10
save 60 10000
# 文件名
dbfilename dump.rdb
# 存储的目录
dir /var/lib/redis/6379
执行RDB的bgsave指令时,数据可以被修改吗?
执行 bgsave 过程中,Redis 依然可以继续处理操作命令的,也就是数据是能被修改的。
那具体如何做到到呢?关键的技术就在于写时复制技术(Copy-On-Write, COW)。
执行 bgsave 命令的时候,会通过 fork() 创建子进程,此时子进程和父进程是共享同一片内存数据的,因为创建子进程的时候,会复制父进程的页表,但是页表指向的物理内存还是一个。
只有在发生修改内存数据的情况时,物理内存才会被复制一份。
这样的目的是为了减少创建子进程时的性能损耗,从而加快创建子进程的速度,毕竟创建子进程的过程中,是会阻塞主线程的。
所以,创建 bgsave 子进程后,由于共享父进程的所有内存数据,于是就可以直接读取主线程(父进程)里的内存数据,并将数据写入到 RDB 文件。
当主线程(父进程)对这些共享的内存数据也都是只读操作,那么,主线程(父进程)和 bgsave 子进程相互不影响。
但是,如果主线程(父进程)要 修改共享数据里的某一块数据 (比如键值对 A)时,就会发生写时复制,于是这块数据的 物理内存就会被复制一份(键值对 A') ,然后 主线程在这个数据副本(键值对 A')进行修改操作 。与此同时, bgsave 子进程可以继续把原来的数据(键值对 A)写入到 RDB 文件 。
就是这样,Redis 使用 bgsave 对当前内存中的所有数据做快照,这个操作是由 bgsave 子进程在后台完成的,执行时不会阻塞主线程,这就使得主线程同时可以修改数据。
细心的同学,肯定发现了,bgsave 快照过程中,如果主线程修改了共享数据, 发生了写时复制后,RDB 快照保存的是原本的内存数据 ,而主线程刚修改的数据,是被办法在这一时间写入 RDB 文件的,只能交由下一次的 bgsave 快照。
所以 Redis 在使用 bgsave 快照过程中,如果主线程修改了内存数据,不管是否是共享的内存数据,RDB 快照都无法写入主线程刚修改的数据,因为此时主线程(父进程)的内存数据和子进程的内存数据已经分离了,子进程写入到 RDB 文件的内存数据只能是原本的内存数据。
如果系统恰好在 RDB 快照文件创建完毕后崩溃了,那么 Redis 将会丢失主线程在快照期间修改的数据。
另外,写时复制的时候会出现这么个极端的情况。
在 Redis 执行 RDB 持久化期间,刚 fork 时,主进程和子进程共享同一物理内存,但是途中主进程处理了写操作,修改了共享内存,于是当前被修改的数据的物理内存就会被复制一份。
那么极端情况下,如果所有的共享内存都被修改,则此时的内存占用是原先的 2 倍。
所以,针对写操作多的场景,我们要留意下快照过程中内存的变化,防止内存被占满了。
RDB的优缺点
优点:
- 恢复速度快,因为记录的是快照,只需要在恢复的时候直接将RDB文件读入内存中就行
缺点:
- 发生故障,丢失的记录可能比较多
缺点
不支持拉链,只有一个dump.rdb,需要运维人员定期拷贝备份
如果发生故障,数据丢失的会比较多。
优点:
类似java的序列化,恢复的速度快
AOF
append only file。将写操作记录到文件中
aof中包含rdb的全量,增加记录新的操作
开启aof
在redis.config文件中
- appendonly yes :表示是否开启AOF持久化,默认为no
- appendfilename “appendonly.aof”:AOF持久化文件的名称
aof测试
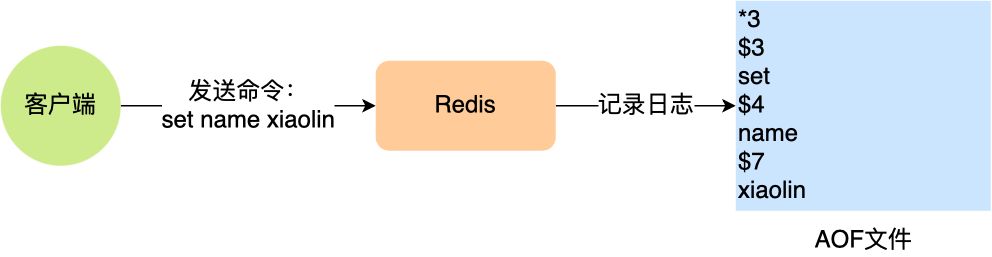
「*3」表示当前命令有三个部分,每部分都是以「$+数字」开头,后面紧跟着具体的命令、键或值。然后,这里的「数字」表示这部分中的命令、键或值一共有多少字节。例如,「$3 set」表示这部分有 3 个字节,也就是「set」命令这个字符串的长度。
不知道大家注意到没有,Redis 是先执行写操作命令后,才将该命令记录到 AOF 日志里的,这么做其实有两个好处。
第一个好处,避免额外的检查开销。
因为如果先将写操作命令记录到 AOF 日志里,再执行该命令的话,如果当前的命令语法有问题,那么如果不进行命令语法检查,该错误的命令记录到 AOF 日志里后,Redis 在使用日志恢复数据时,就可能会出错。
而如果先执行写操作命令再记录日志的话,只有在该命令执行成功后,才将命令记录到 AOF 日志里,这样就不用额外的检查开销,保证记录在 AOF 日志里的命令都是可执行并且正确的。
第二个好处, 不会阻塞当前写操作命令的执行 ,因为当写操作命令执行成功后,才会将命令记录到 AOF 日志。
当然,AOF 持久化功能也不是没有潜在风险。
第一个风险,执行写操作命令和记录日志是两个过程,那当 Redis 在还没来得及将命令写入到硬盘时,服务器发生宕机了,这个数据就会有 丢失的风险 。
第二个风险,前面说道,由于写操作命令执行成功后才记录到 AOF 日志,所以不会阻塞当前写操作命令的执行,但是 可能会给「下一个」命令带来阻塞风险 。
因为将命令写入到日志的这个操作也是在主进程完成的(执行命令也是在主进程),也就是说这两个操作是同步的。
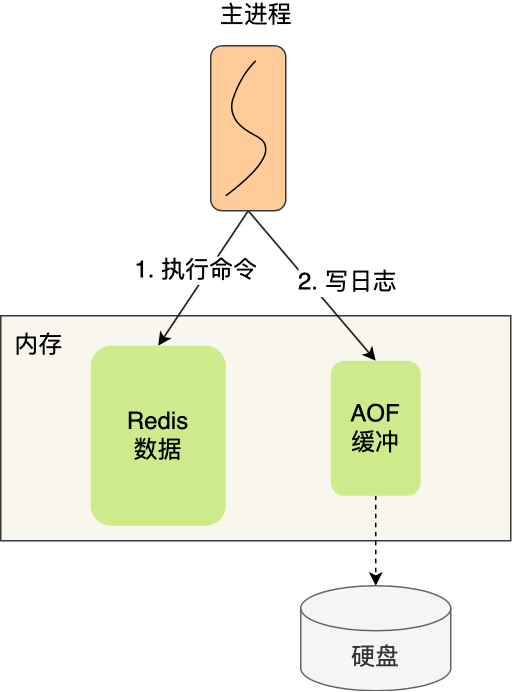
如果在将日志内容写入到硬盘时,服务器的硬盘的 I/O 压力太大,就会导致写硬盘的速度很慢,进而阻塞住了,也就会导致后续的命令无法执行。
认真分析一下,其实这两个风险都有一个共性,都跟「 AOF 日志写回硬盘的时机」有关。
aof写回硬盘策略
aof写入硬盘的步骤
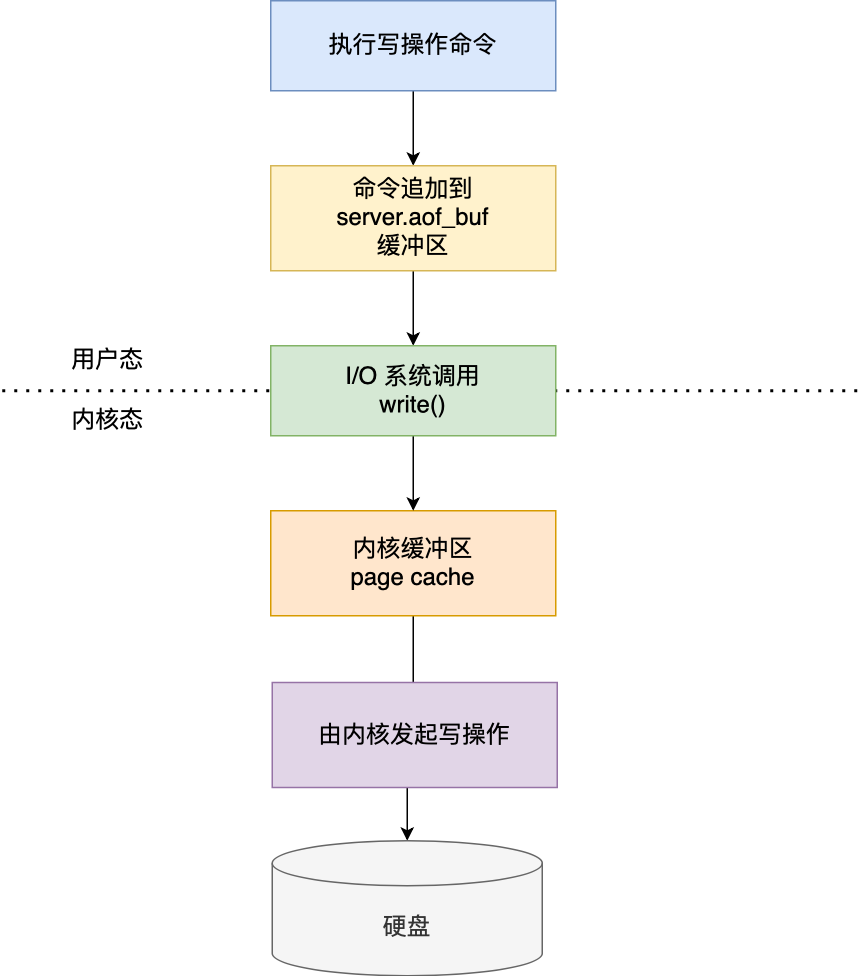
- Redis 执行完写操作命令后,会将命令追加到
server.aof_buf缓冲区; - 然后通过 write() 系统调用,将 aof_buf 缓冲区的数据写入到 AOF 文件,此时数据并没有写入到硬盘,而是拷贝到了内核缓冲区 page cache,等待内核将数据写入硬盘;
- 具体内核缓冲区的数据什么时候写入到硬盘,由内核决定。
Redis 提供了 3 种写回硬盘的策略,控制的就是上面说的第三步的过程。
在 redis.conf 配置文件中的 appendfsync 配置项可以有以下 3 种参数可填:
- Always ,这个单词的意思是「总是」,所以它的意思是每次写操作命令执行完后,同步将 AOF 日志数据写回硬盘;
- Everysec ,这个单词的意思是「每秒」,所以它的意思是每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,然后每隔一秒将缓冲区里的内容写回到硬盘;
- No ,意味着不由 Redis 控制写回硬盘的时机,转交给操作系统控制写回的时机,也就是每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,再由操作系统决定何时将缓冲区内容写回硬盘。
这 3 种写回策略都无法能完美解决「主进程阻塞」和「减少数据丢失」的问题,因为两个问题是对立的,偏向于一边的话,就会要牺牲另外一边,原因如下:
- Always 策略的话,可以最大程度保证数据不丢失,但是由于它每执行一条写操作命令就同步将 AOF 内容写回硬盘,所以是不可避免会影响主进程的性能;
- No 策略的话,是交由操作系统来决定何时将 AOF 日志内容写回硬盘,相比于 Always 策略性能较好,但是操作系统写回硬盘的时机是不可预知的,如果 AOF 日志内容没有写回硬盘,一旦服务器宕机,就会丢失不定数量的数据。
- Everysec 策略的话,是折中的一种方式,避免了 Always 策略的性能开销,也比 No 策略更能避免数据丢失,当然如果上一秒的写操作命令日志没有写回到硬盘,发生了宕机,这一秒内的数据自然也会丢失。
大家根据自己的业务场景进行选择:
- 如果要高性能,就选择 No 策略;
- 如果要高可靠,就选择 Always 策略;
- 如果允许数据丢失一点,但又想性能高,就选择 Everysec 策略。
我也把这 3 个写回策略的优缺点总结成了一张表格:
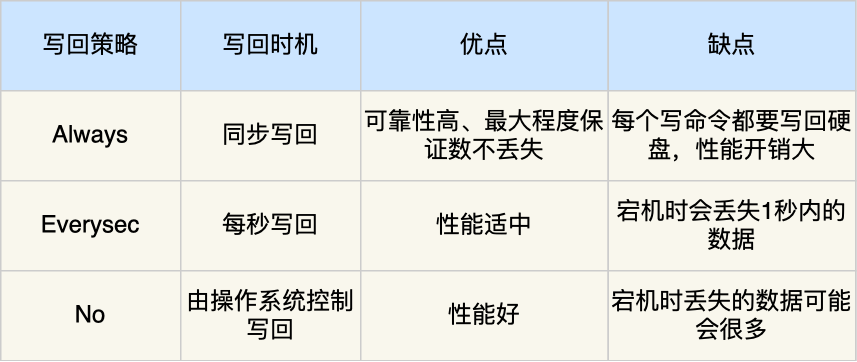
深入到源码后,你就会发现这三种策略只是在控制 fsync() 函数的调用时机。
当应用程序向文件写入数据时,内核通常先将数据复制到内核缓冲区中,然后排入队列,然后由内核决定何时写入硬盘。
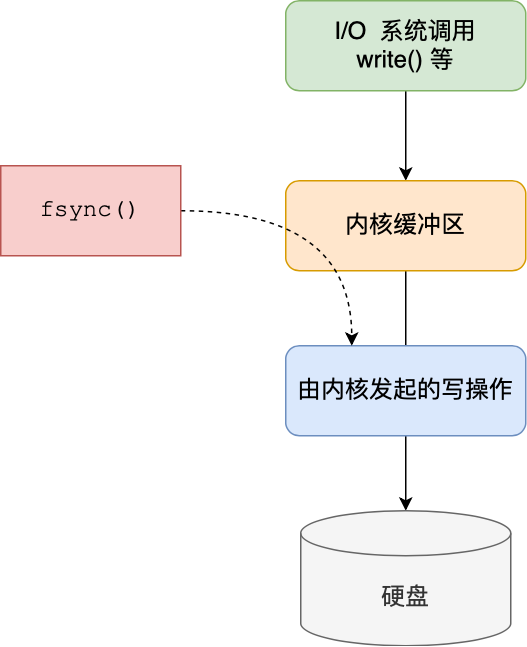
如果想要应用程序向文件写入数据后,能立马将数据同步到硬盘,就可以调用 fsync() 函数,这样内核就会将内核缓冲区的数据直接写入到硬盘,等到硬盘写操作完成后,该函数才会返回。
- Always 策略就是每次写入 AOF 文件数据后,就执行 fsync() 函数;
- Everysec 策略就会创建一个异步任务来执行 fsync() 函数;
- No 策略就是永不执行 fsync() 函数
AOF重写机制
AOF 日志是一个文件,随着执行的写操作命令越来越多,文件的大小会越来越大。
如果当 AOF 日志文件过大就会带来性能问题,比如重启 Redis 后,需要读 AOF 文件的内容以恢复数据,如果文件过大,整个恢复的过程就会很慢。
所以,Redis 为了避免 AOF 文件越写越大,提供了 AOF 重写机制 ,当 AOF 文件的大小超过所设定的阈值后,Redis 就会启用 AOF 重写机制,来压缩 AOF 文件。
AOF 重写机制是在重写时,读取当前数据库中的所有键值对,然后将每一个键值对用一条命令记录到「新的 AOF 文件」,等到全部记录完后,就将新的 AOF 文件替换掉现有的 AOF 文件。
举个例子,在没有使用重写机制前,假设前后执行了「 set name xiaolin 」和「 set name xiaolincoding 」这两个命令的话,就会将这两个命令记录到 AOF 文件。
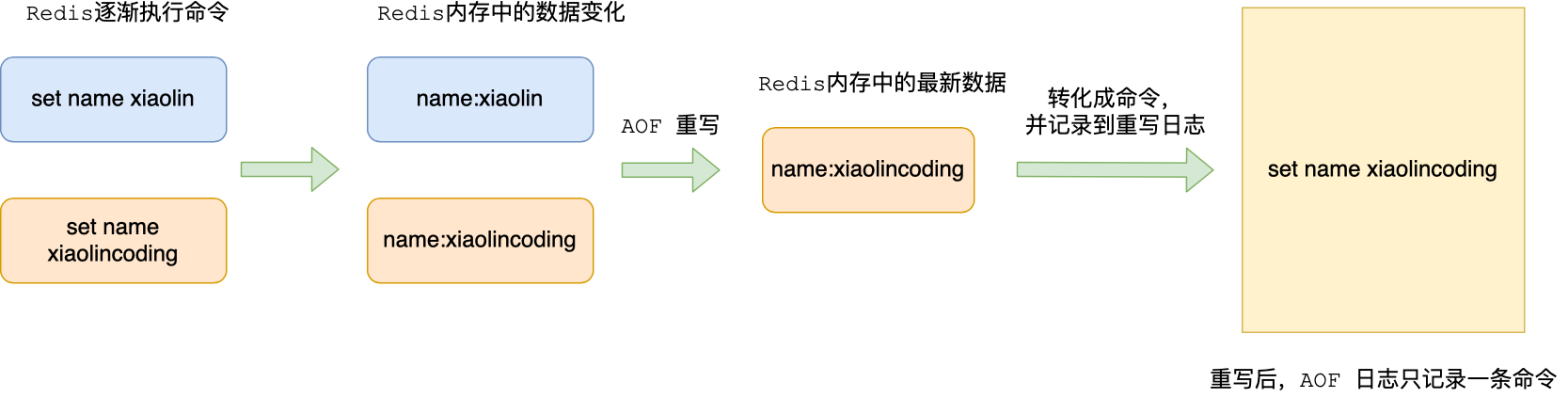
但是 在使用重写机制后,就会读取 name 最新的 value(键值对) ,然后用一条 「set name xiaolincoding」命令记录到新的 AOF 文件 ,之前的第一个命令就没有必要记录了,因为它属于「历史」命令,没有作用了。这样一来,一个键值对在重写日志中只用一条命令就行了。
重写工作完成后,就会将新的 AOF 文件覆盖现有的 AOF 文件,这就相当于压缩了 AOF 文件,使得 AOF 文件体积变小了。
然后,在通过 AOF 日志恢复数据时,只用执行这条命令,就可以直接完成这个键值对的写入了。
所以,重写机制的妙处在于,尽管某个键值对被多条写命令反复修改, 最终也只需要根据这个「键值对」当前的最新状态,然后用一条命令去记录键值对 ,代替之前记录这个键值对的多条命令,这样就减少了 AOF 文件中的命令数量。最后在重写工作完成后,将新的 AOF 文件覆盖现有的 AOF 文件。
这里说一下为什么重写 AOF 的时候,不直接复用现有的 AOF 文件,而是先写到新的 AOF 文件再覆盖过去。
因为 如果 AOF 重写过程中失败了,现有的 AOF 文件就会造成污染 ,可能无法用于恢复使用。
所以 AOF 重写过程,先重写到新的 AOF 文件,重写失败的话,就直接删除这个文件就好,不会对现有的 AOF 文件造成影响。
AOF后台重写
写入 AOF 日志的操作虽然是在主进程完成的,因为它写入的内容不多,所以一般不太影响命令的操作。
但是在触发 AOF 重写时,比如当 AOF 文件大于 64M 时,就会对 AOF 文件进行重写,这时是需要读取所有缓存的键值对数据,并为每个键值对生成一条命令,然后将其写入到新的 AOF 文件,重写完后,就把现在的 AOF 文件替换掉。
这个过程其实是很耗时的,所以重写的操作不能放在主进程里。
所以,Redis 的 重写 AOF 过程是由后台子进程 bgrewriteaof 来完成的 ,这么做可以达到两个好处:
- 子进程进行 AOF 重写期间,主进程可以继续处理命令请求,从而避免阻塞主进程;
- 子进程带有主进程的数据副本( 数据副本怎么产生的后面会说 ),这里使用子进程而不是线程,因为如果是使用线程,多线程之间会共享内存,那么在修改共享内存数据的时候,需要通过加锁来保证数据的安全,而这样就会降低性能。而使用子进程,创建子进程时,父子进程是共享内存数据的,不过这个共享的内存只能以只读的方式,而当父子进程任意一方修改了该共享内存,就会发生「写时复制」,于是父子进程就有了独立的数据副本,就不用加锁来保证数据安全。
子进程是怎么拥有主进程一样的数据副本的呢?
主进程在通过 fork 系统调用生成 bgrewriteaof 子进程时,操作系统会把主进程的「 页表 」复制一份给子进程,这个页表记录着虚拟地址和物理地址映射关系,而不会复制物理内存,也就是说,两者的虚拟空间不同,但其对应的物理空间是同一个。
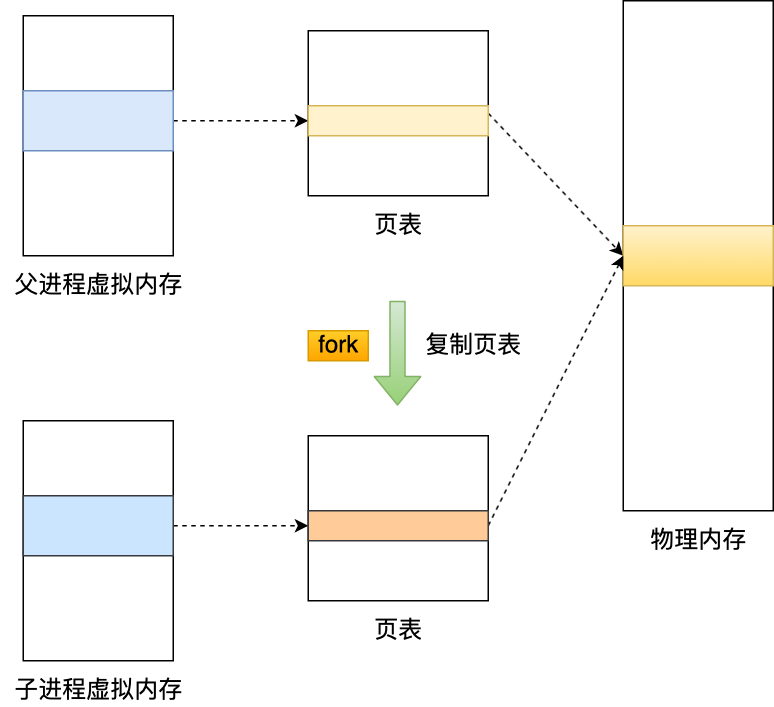
这样一来,子进程就共享了父进程的物理内存数据了,这样能够 节约物理内存资源 ,页表对应的页表项的属性会标记该物理内存的权限为 只读 。
不过,当父进程或者子进程在向这个内存发起写操作时,CPU 就会触发 缺页中断 ,这个缺页中断是由于违反权限导致的,然后操作系统会在「缺页异常处理函数」里进行 物理内存的复制 ,并重新设置其内存映射关系,将父子进程的内存读写权限设置为 可读写 ,最后才会对内存进行写操作,这个过程被称为「 写时复制( Copy On Write ) 」。
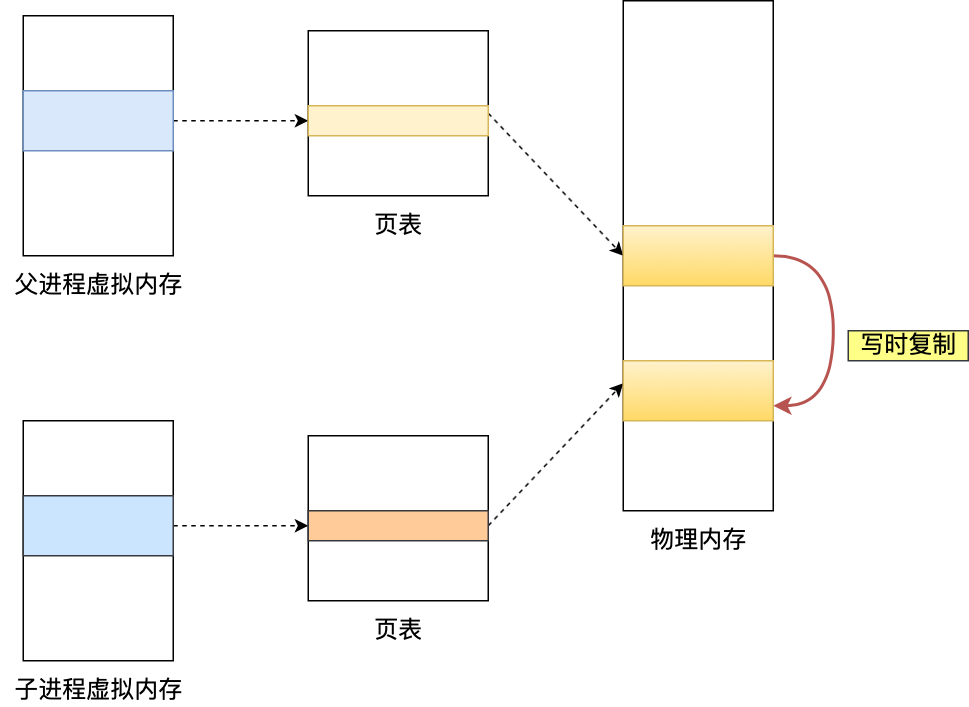
写时复制顾名思义, 在发生写操作的时候,操作系统才会去复制物理内存 ,这样是为了防止 fork 创建子进程时,由于物理内存数据的复制时间过长而导致父进程长时间阻塞的问题。
当然,操作系统复制父进程页表的时候,父进程也是阻塞中的,不过页表的大小相比实际的物理内存小很多,所以通常复制页表的过程是比较快的。
不过,如果父进程的内存数据非常大,那自然页表也会很大,这时父进程在通过 fork 创建子进程的时候,阻塞的时间也越久。
所以,有两个阶段会导致阻塞父进程:
- 创建子进程的途中,由于要复制父进程的页表等数据结构,阻塞的时间跟页表的大小有关,页表越大,阻塞的时间也越长;
- 创建完子进程后,如果子进程或者父进程修改了共享数据,就会发生写时复制,这期间会拷贝物理内存,如果内存越大,自然阻塞的时间也越长;
触发重写机制后,主进程就会创建重写 AOF 的子进程,此时父子进程共享物理内存,重写子进程只会对这个内存进行只读,重写 AOF 子进程会读取数据库里的所有数据,并逐一把内存数据的键值对转换成一条命令,再将命令记录到重写日志(新的 AOF 文件)。
但是子进程重写过程中,主进程依然可以正常处理命令。
如果此时 主进程修改了已经存在 key-value,就会发生写时复制,注意这里只会复制主进程修改的物理内存数据,没修改物理内存还是与子进程共享的 。
所以如果这个阶段修改的是一个 bigkey,也就是数据量比较大的 key-value 的时候,这时复制的物理内存数据的过程就会比较耗时,有阻塞主进程的风险。
还有个问题,重写 AOF 日志过程中,如果主进程修改了已经存在 key-value,此时这个 key-value 数据在子进程的内存数据就跟主进程的内存数据不一致了,这时要怎么办呢?
为了解决这种数据不一致问题,Redis 设置了一个 AOF 重写缓冲区 ,这个缓冲区在创建 bgrewriteaof 子进程之后开始使用。
在重写 AOF 期间,当 Redis 执行完一个写命令之后,它会 同时将这个写命令写入到 「AOF 缓冲区」和 「AOF 重写缓冲区」 。
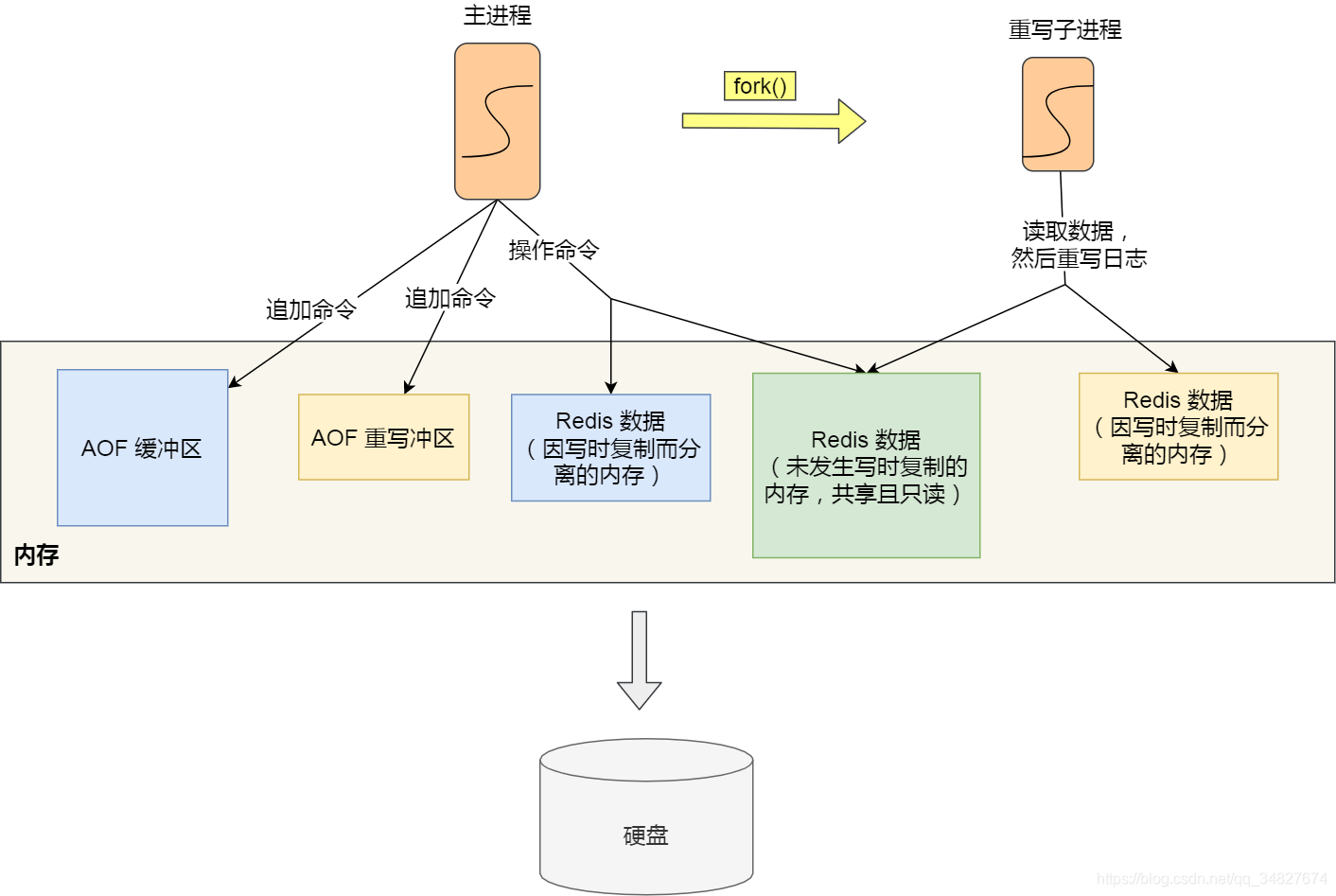
也就是说,在 bgrewriteaof 子进程执行 AOF 重写期间,主进程需要执行以下三个工作:
- 执行客户端发来的命令;
- 将执行后的写命令追加到 「AOF 缓冲区」;
- 将执行后的写命令追加到 「AOF 重写缓冲区」;
当子进程完成 AOF 重写工作( 扫描数据库中所有数据,逐一把内存数据的键值对转换成一条命令,再将命令记录到重写日志 )后,会向主进程发送一条信号,信号是进程间通讯的一种方式,且是异步的。
主进程收到该信号后,会调用一个信号处理函数,该函数主要做以下工作:
- 将 AOF 重写缓冲区中的所有内容追加到新的 AOF 的文件中,使得新旧两个 AOF 文件所保存的数据库状态一致;
- 新的 AOF 的文件进行改名,覆盖现有的 AOF 文件。
信号函数执行完后,主进程就可以继续像往常一样处理命令了。
在整个 AOF 后台重写过程中,除了发生写时复制会对主进程造成阻塞,还有信号处理函数执行时也会对主进程造成阻塞,在其他时候,AOF 后台重写都不会阻塞主进程。
AOF优缺点
优缺点
丢失的数据少
恢复的速度慢,体积大
可以同时开启rdb和aof,但是恢复的时候,只会拿aof进行恢复。
案例
假设redis运行了10年,到10年的时候,redis挂了,请问redis的aof文件多大,恢复要多长时间?
很大,比如10T。恢复的时候会不会内存溢出?
# redis4.0以前,删除抵消的命令,合并重复的命令
# redis4.0以后,将老的数据rdb装到aof文件中,将增量以指令的方式append到AOF。这样aof有rdb的快和日志的全量
RDB和AOF联合使用
尽管 RDB 比 AOF 的数据恢复速度快,但是快照的频率不好把握:
- 如果频率太低,两次快照间一旦服务器发生宕机,就可能会比较多的数据丢失;
- 如果频率太高,频繁写入磁盘和创建子进程会带来额外的性能开销。
那有没有什么方法不仅有 RDB 恢复速度快的优点和,又有 AOF 丢失数据少的优点呢?
当然有,那就是将 RDB 和 AOF 合体使用,这个方法是在 Redis 4.0 提出的,该方法叫 混合使用 AOF 日志和内存快照 ,也叫混合持久化。
如果想要开启混合持久化功能,可以在 Redis 配置文件将下面这个配置项设置成 yes:
aof-use-rdb-preamble yes
混合持久化工作在 AOF 日志重写过程 。
当开启了混合持久化时,在 AOF 重写日志时,fork 出来的重写子进程会先将与主线程共享的内存数据以 RDB 方式写入到 AOF 文件,然后主线程处理的操作命令会被记录在重写缓冲区里,重写缓冲区里的增量命令会以 AOF 方式写入到 AOF 文件,写入完成后通知主进程将新的含有 RDB 格式和 AOF 格式的 AOF 文件替换旧的的 AOF 文件。
也就是说,使用了混合持久化,AOF 文件的 前半部分是 RDB 格式的全量数据,后半部分是 AOF 格式的增量数据 。
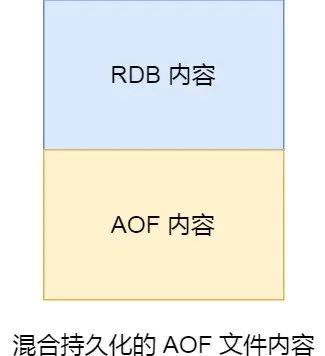
这样的好处在于,重启 Redis 加载数据的时候,由于前半部分是 RDB 内容,这样 加载的时候速度会很快 。
加载完 RDB 的内容后,才会加载后半部分的 AOF 内容,这里的内容是 Redis 后台子进程重写 AOF 期间,主线程处理的操作命令,可以使得 数据更少的丢失 。
测试
# 打开aof持久化
appendonly yes
# 关闭后台进程
daemonize no
# 注销掉日志文件,显示在前台
# logfile /var/log/redis_6379.log
# 不使用混合模式
aof-use-rdb-preamble no
bgsave调用rdb
bgrewrite调用aof重写
六:高可用
情景
由于数据都是存储在一台服务器上,如果出事就完犊子了,比如:
- 如果服务器发生了宕机,由于数据恢复是需要点时间,那么这个期间是无法服务新的请求的;
- 如果这台服务器的硬盘出现了故障,可能数据就都丢失了。
要避免这种单点故障,最好的办法是将数据备份到其他服务器上,让这些服务器也可以对外提供服务,这样即使有一台服务器出现了故障,其他服务器依然可以继续提供服务。
AFK概念
单机、单实例的问题:可能会发生单点故障、单机容量有限的、单机多数据来的时候会有压力
主备:客户端只能访问主机,备机是等主机挂掉之后访问
主从:客户端可以访问主从机
AKF:有xyz三轴概念
X:做全量和镜像
Y:业务、功能分离
Z:按照优先级和逻辑拆分
追求可用性,使用主备,一变多,需要强一致性,破坏强一致性
解决:
1.同步阻塞的方式redis--->redis1、redis2,会破坏可用性
2.异步阻塞的方式redis--->redis1、redis2,会破坏强一致性
3.折中 redis--同步阻塞--->kafka-->异步-->redis 最终数据会一致
分区容忍性
CAP定理
“CAP原则又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。”
主从复制
主服务器可以进行读写操作,当发生写操作时自动将写操作同步给从服务器,而从服务器一般是只读,并接受主服务器同步过来写操作命令,然后执行这条命令。
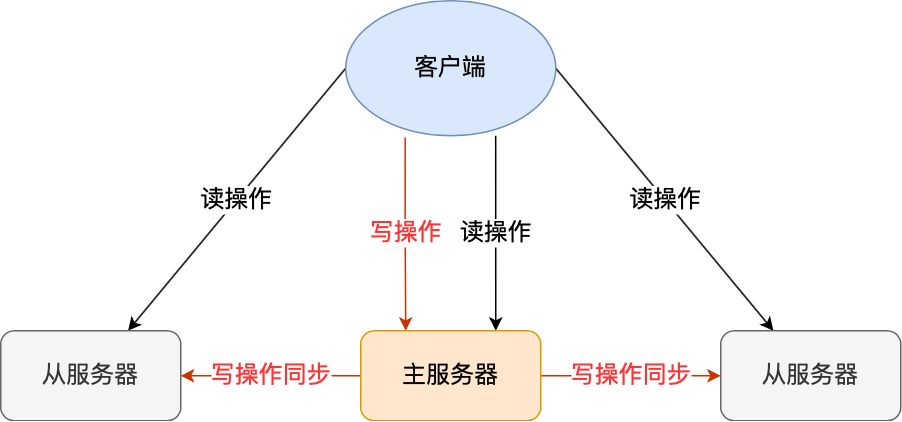
也就是说,所有的数据修改只在主服务器上进行,然后将最新的数据同步给从服务器,这样就使得主从服务器的数据是一致的。
同步这两个字说的简单,但是这个同步过程并没有想象中那么简单,要考虑的事情不是一两个。
主从复制同步机制
- 服务器B如何成为服务器A的从机
在服务器 B 上执行下面这条命令:
replicaof <服务器 A 的 IP 地址> <服务器 A 的 Redis 端口号>
接着,服务器 B 就会变成服务器 A 的「从服务器」,然后与主服务器进行第一次同步。
主从复制第一次同步
主从服务器间的第一次同步的过程可分为三个阶段:
- 第一阶段是建立链接、协商同步;
- 第二阶段是主服务器同步数据给从服务器;
- 第三阶段是主服务器发送新写操作命令给从服务器。
为了让你更清楚了解这三个阶段,我画了一张图。
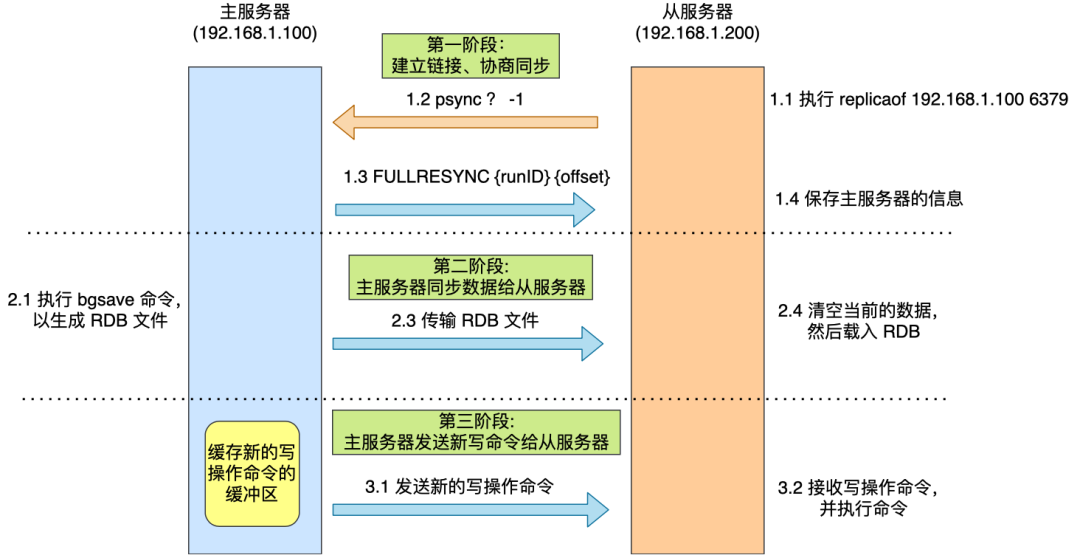
接下来,我在具体介绍每一个阶段都做了什么。
第一阶段:建立链接、协商同步
执行了 replicaof 命令后,从服务器就会给主服务器发送 psync 命令,表示要进行数据同步。
psync 命令包含两个参数,分别是主服务器的 runID 和 复制进度 offset 。
- runID,每个 Redis 服务器在启动时都会自动生产一个随机的 ID 来唯一标识自己。当从服务器和主服务器第一次同步时,因为不知道主服务器的 run ID,所以将其设置为 “?”。
- offset,表示复制的进度,第一次同步时,其值为 -1。
主服务器收到 psync 命令后,会用 FULLRESYNC 作为响应命令返回给对方。
并且这个响应命令会带上两个参数:主服务器的 runID 和主服务器目前的复制进度 offset。从服务器收到响应后,会记录这两个值。
FULLRESYNC 响应命令的意图是采用全量复制的方式,也就是主服务器会把所有的数据都同步给从服务器。
所以,第一阶段的工作时为了全量复制做准备。
那具体怎么全量同步呀呢?我们可以往下看第二阶段。
第二阶段:主服务器同步数据给从服务器
接着,主服务器会执行 bgsave 命令来生成 RDB 文件,然后把文件发送给从服务器。
从服务器收到 RDB 文件后,会先清空当前的数据,然后载入 RDB 文件。
这里有一点要注意,主服务器生成 RDB 这个过程是不会阻塞主线程的,因为 bgsave 命令是产生了一个子进程来做生成 RDB 文件的工作,是异步工作的,这样 Redis 依然可以正常处理命令。
但是,这期间的写操作命令并没有记录到刚刚生成的 RDB 文件中,这时主从服务器间的数据就不一致了。那么为了保证主从服务器的数据一致性,主服务器在下面这三个时间间隙中将收到的写操作命令,写入到 replication buffer 缓冲区里。
- 主服务器生成 RDB 文件期间;
- 主服务器发送 RDB 文件给从服务器期间;
- 「从服务器」加载 RDB 文件期间;
第三阶段:主服务器发送新写操作命令给从服务器
在主服务器生成的 RDB 文件发送完,从服务器加载完 RDB 文件后,然后将 replication buffer 缓冲区里所记录的写操作命令发送给从服务器,然后「从服务器」重新执行这些操作,至此主从服务器的数据就一致了。
至此,主从服务器的第一次同步的工作就完成了。
命令传播
主从服务器在完成第一次同步后,双方之间就会维护一个 TCP 连接。
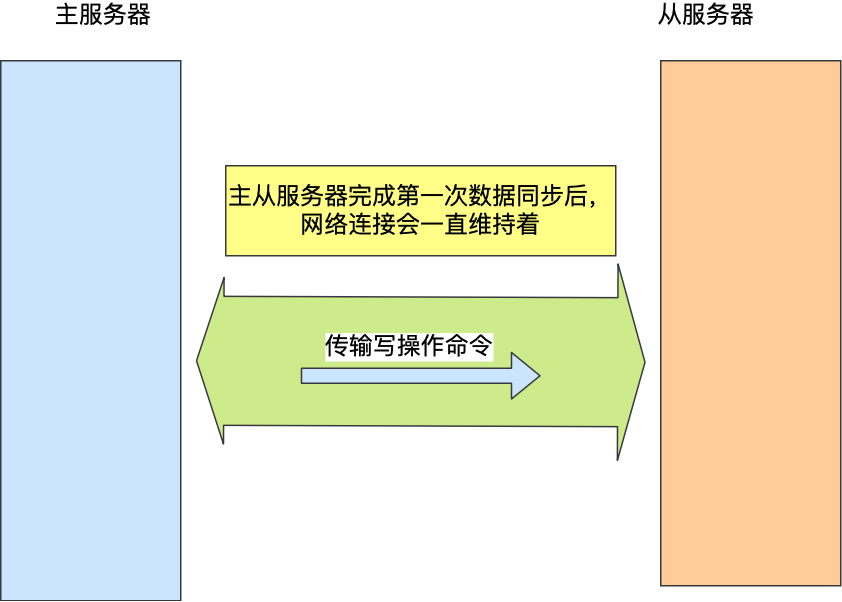
后续主服务器可以通过这个连接继续将写操作命令传播给从服务器,然后从服务器执行该命令,使得与主服务器的数据库状态相同。
而且这个连接是长连接的,目的是避免频繁的 TCP 连接和断开带来的性能开销。
上面的这个过程被称为 基于长连接的命令传播 ,通过这种方式来保证第一次同步后的主从服务器的数据一致性。
从服务器分摊主服务器压力
在前面的分析中,我们可以知道主从服务器在第一次数据同步的过程中,主服务器会做两件耗时的操作:生成 RDB 文件和传输 RDB 文件。
主服务器是可以有多个从服务器的,如果从服务器数量非常多,而且都与主服务器进行全量同步的话,就会带来两个问题:
- 由于是通过 bgsave 命令来生成 RDB 文件的,那么主服务器就会忙于使用 fork() 创建子进程,如果主服务器的内存数据非大,在执行 fork() 函数时是会阻塞主线程的,从而使得 Redis 无法正常处理请求;
- 传输 RDB 文件会占用主服务器的网络带宽,会对主服务器响应命令请求产生影响。
这种情况就好像,刚创业的公司,由于人不多,所以员工都归老板一个人管,但是随着公司的发展,人员的扩充,老板慢慢就无法承担全部员工的管理工作了。
要解决这个问题,老板就需要设立经理职位,由经理管理多名普通员工,然后老板只需要管理经理就好。
Redis 也是一样的,从服务器可以有自己的从服务器,我们可以把拥有从服务器的从服务器当作经理角色,它不仅可以接收主服务器的同步数据,自己也可以同时作为主服务器的形式将数据同步给从服务器,组织形式如下图:
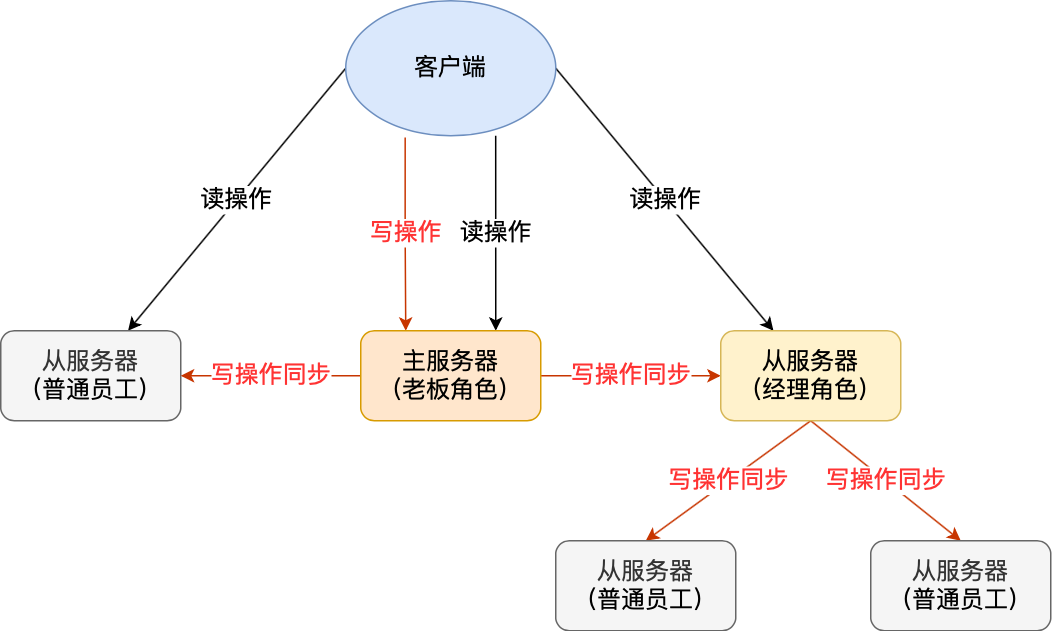
通过这种方式, 主服务器生成 RDB 和传输 RDB 的压力可以分摊到充当经理角色的从服务器 。
那具体怎么做到的呢?
其实很简单,我们在「从服务器」上执行下面这条命令,使其作为目标服务器的从服务器:
replicaof <目标服务器的IP> 6379
此时如果目标服务器本身也是「从服务器」,那么该目标服务器就会成为「经理」的角色,不仅可以接受主服务器同步的数据,也会把数据同步给自己旗下的从服务器,从而减轻主服务器的负担。
增量复制
主从服务器在完成第一次同步后,就会基于长连接进行命令传播。
可是,网络总是不按套路出牌的嘛,说延迟就延迟,说断开就断开。
如果主从服务器间的网络连接断开了,那么就无法进行命令传播了,这时从服务器的数据就没办法和主服务器保持一致了,客户端就可能从「从服务器」读到旧的数据。

那么问题来了,如果此时断开的网络,又恢复正常了,要怎么继续保证主从服务器的数据一致性呢?
在 Redis 2.8 之前,如果主从服务器在命令同步时出现了网络断开又恢复的情况,从服务器就会和主服务器重新进行一次全量复制,很明显这样的开销太大了,必须要改进一波。
所以,从 Redis 2.8 开始,网络断开又恢复后,从主从服务器会采用增量复制的方式继续同步,也就是只会把网络断开期间主服务器接收到的写操作命令,同步给从服务器。
网络恢复后的增量复制过程如下图:

主要有三个步骤:
- 从服务器在恢复网络后,会发送 psync 命令给主服务器,此时的 psync 命令里的 offset 参数不是 -1;
- 主服务器收到该命令后,然后用 CONTINUE 响应命令告诉从服务器接下来采用增量复制的方式同步数据;
- 然后主服务将主从服务器断线期间,所执行的写命令发送给从服务器,然后从服务器执行这些命令。
那么关键的问题来了,主服务器怎么知道要将哪些增量数据发送给从服务器呢?
答案藏在这两个东西里:
- repl_backlog_buffer ,是一个「 环形 」缓冲区,用于主从服务器断连后,从中找到差异的数据;
- replication offset ,标记上面那个缓冲区的同步进度,主从服务器都有各自的偏移量,主服务器使用 master_repl_offset 来记录自己「 写 」到的位置,从服务器使用 slave_repl_offset 来记录自己「 读 」到的位置。
那repl_backlog_buffer 缓冲区是什么时候写入的呢?
在主服务器进行命令传播时,不仅会将写命令发送给从服务器,还会将写命令写入到 repl_backlog_buffer 缓冲区里,因此 这个缓冲区里会保存着最近传播的写命令。
网络断开后,当从服务器重新连上主服务器时,从服务器会通过 psync 命令将自己的复制偏移量 slave_repl_offset 发送给主服务器,主服务器根据自己的 master_repl_offset 和 slave_repl_offset 之间的差距,然后来决定对从服务器执行哪种同步操作:
- 如果判断出从服务器要读取的数据还在 repl_backlog_buffer 缓冲区里,那么主服务器将采用增量同步的方式;
- 相反,如果判断出从服务器要读取的数据已经不存在 repl_backlog_buffer 缓冲区里,那么主服务器将采用全量同步的方式。
当主服务器在 repl_backlog_buffer 中找到主从服务器差异(增量)的数据后,就会将增量的数据写入到 replication buffer 缓冲区,这个缓冲区我们前面也提到过,它是缓存将要传播给从服务器的命令。

repl_backlog_buffer 缓行缓冲区的默认大小是 1M,并且由于它是一个环形缓冲区,所以当缓冲区写满后,主服务器继续写入的话,就会覆盖之前的数据。
因此,当主服务器的写入速度远超于从服务器的读取速度,缓冲区的数据一下就会被覆盖。
那么在网络恢复时,如果从服务器想读的数据已经被覆盖了,主服务器就会采用全量同步,这个方式比增量同步的性能损耗要大很多。
因此,为了避免在网络恢复时,主服务器频繁地使用全量同步的方式,我们应该调整下 repl_backlog_buffer 缓冲区大小,尽可能的大一些,减少出现从服务器要读取的数据被覆盖的概率,从而使得主服务器采用增量同步的方式。
那 repl_backlog_buffer 缓冲区具体要调整到多大呢?
repl_backlog_buffer 最小的大小可以根据这面这个公式估算。

我来解释下这个公式的意思:
- second 为从服务器断线后重新连接上主服务器所需的平均 时间(以秒计算)。
- write_size_per_second 则是主服务器平均每秒产生的写命令数据量大小。
举个例子,如果主服务器平均每秒产生 1 MB 的写命令,而从服务器断线之后平均要 5 秒才能重新连接主服务器。
那么 repl_backlog_buffer 大小就不能低于 5 MB,否则新写地命令就会覆盖旧数据了。
当然,为了应对一些突发的情况,可以将 repl_backlog_buffer 的大小设置为此基础上的 2 倍,也就是 10 MB。
关于 repl_backlog_buffer 大小修改的方法,只需要修改配置文件里下面这个参数项的值就可以。
repl-backlog-size 1mb
测试主从复制
把三个config文件拷贝出来,将daemonize 改为no,将日志文件注销掉,删掉/var/log/redis下所有日志文件
执行三个文件
cd /usr/local/software/redis-6.0.6/bin
redis-server /usr/local/software/redis-6.0.6/bin/6379.conf
# 6380机子上输入命令
127.0.0.1:6380> replicaof 127.0.0.1 6379
OK
# 6379机子出现以下命令
3785:M 23 Jun 2022 21:01:08.636 * Replica 127.0.0.1:6380 asks for synchronization # 要求同步
3785:M 23 Jun 2022 21:01:08.636 * Partial resynchronization not accepted: Replication ID mismatch (Replica asked for 'cca2d056f63f54a9b91a3f0f86ce42c5a6d67b44', my replication IDs are '2fca682d9c7e786b735e02d0f118bb178379931c' and '0000000000000000000000000000000000000000')
3785:M 23 Jun 2022 21:01:08.636 * Replication backlog created, my new replication IDs are '75eb8db26ec2b68b4b0089cc0dd147a396ff9bb7' and '0000000000000000000000000000000000000000'
3785:M 23 Jun 2022 21:01:08.636 * Starting BGSAVE for SYNC with target: disk
3785:M 23 Jun 2022 21:01:08.636 * Background saving started by pid 19014
19014:C 23 Jun 2022 21:01:08.644 * DB saved on disk
19014:C 23 Jun 2022 21:01:08.644 * RDB: 0 MB of memory used by copy-on-write
3785:M 23 Jun 2022 21:01:08.732 * Background saving terminated with success
3785:M 23 Jun 2022 21:01:08.732 * Synchronization with replica 127.0.0.1:6380 succeeded
# 6380机子
8494:S 23 Jun 2022 21:01:08.635 * Connecting to MASTER 127.0.0.1:6379
8494:S 23 Jun 2022 21:01:08.635 * MASTER <-> REPLICA sync started
8494:S 23 Jun 2022 21:01:08.635 * Non blocking connect for SYNC fired the event.
8494:S 23 Jun 2022 21:01:08.635 * Master replied to PING, replication can continue...
8494:S 23 Jun 2022 21:01:08.635 * Trying a partial resynchronization (request cca2d056f63f54a9b91a3f0f86ce42c5a6d67b44:1).
8494:S 23 Jun 2022 21:01:08.636 * Full resync from master: 75eb8db26ec2b68b4b0089cc0dd147a396ff9bb7:0
8494:S 23 Jun 2022 21:01:08.636 * Discarding previously cached master state.
8494:S 23 Jun 2022 21:01:08.732 * MASTER <-> REPLICA sync: receiving 175 bytes from master to disk
8494:S 23 Jun 2022 21:01:08.732 * MASTER <-> REPLICA sync: Flushing old data
8494:S 23 Jun 2022 21:01:08.732 * MASTER <-> REPLICA sync: Loading DB in memory
8494:S 23 Jun 2022 21:01:08.732 * Loading RDB produced by version 6.0.6
8494:S 23 Jun 2022 21:01:08.732 * RDB age 0 seconds
8494:S 23 Jun 2022 21:01:08.732 * RDB memory usage when created 1.84 Mb
8494:S 23 Jun 2022 21:01:08.732 * MASTER <-> REPLICA sync: Finished with success
# 尝试在从机上写入,报错
127.0.0.1:6380> set k2 3
(error) READONLY You can't write against a read only replica.
# 6381机子挂了,重新连接,还是使用rdb
[root@VM-4-2-centos bin]# redis-server ./6381.conf --replicaof 127.0.0.1 6379
# 6381机子挂了,重新连接,使用aof
[root@VM-4-2-centos bin]# redis-server ./6381.conf --replicaof 127.0.0.1 6379 --appendonly yes
# 6379挂了之后,6380自己从从机改为自己独立运行
replicaof no one
# 6381改为追随6380
relicaof 127.0.0.1 6380
结论,只要开启aof,就是全量同步.在此期间主机进行aof,从机要flush old data,然后进行同步
哨兵模式
由于主从复制是读写分离的,当主节点挂掉后,从节点就无法主动选举出主节点,导致写操作无法进行,并且主节点无法进行数据同步。
Redis 在 2.8 版本以后提供的 哨兵( Sentinel )机制 ,它的作用是实现 主从节点故障转移 。它会监测主节点是否存活,如果发现主节点挂了,它就会选举一个从节点切换为主节点,并且把新主节点的相关信息通知给从节点和客户端。
哨兵机制是如何工作的
哨兵其实是一个运行在特殊模式下的 Redis 进程,所以它也是一个节点。从“哨兵”这个名字也可以看得出来,它相当于是“观察者节点”,观察的对象是主从节点。
当然,它不仅仅是观察那么简单,在它观察到有异常的状况下,会做出一些“动作”,来修复异常状态。
哨兵节点主要负责三件事情: 监控、选主、通知 。
所以,我们重点要学习这三件事情:
- 哨兵节点是如何监控节点的?又是如何判断主节点是否真的故障了?
- 根据什么规则选择一个从节点切换为主节点?
- 怎么把新主节点的相关信息通知给从节点和客户端呢?
如何判断主节点故障?
哨兵会每隔 1 秒给所有主从节点发送 PING 命令,当主从节点收到 PING 命令后,会发送一个响应命令给哨兵,这样就可以判断它们是否在正常运行。

如果主节点或者从节点没有在规定的时间内响应哨兵的 PING 命令,哨兵就会将它们标记为「 主观下线 」。这个「规定的时间」是配置项 down-after-milliseconds 参数设定的,单位是毫秒。
主观下线?难道还有客观下线?
是的没错,客观下线只适用于主节点。
之所以针对「主节点」设计「主观下线」和「客观下线」两个状态,是因为有可能「主节点」其实并没有故障,可能只是因为主节点的系统压力比较大或者网络发送了拥塞,导致主节点没有在规定时间内响应哨兵的 PING 命令。
所以,为了减少误判的情况,哨兵在部署的时候不会只部署一个节点,而是用多个节点部署成 哨兵集群 ( 最少需要三台机器来部署哨兵集群 ), 通过多个哨兵节点一起判断,就可以就可以避免单个哨兵因为自身网络状况不好,而误判主节点下线的情况 。同时,多个哨兵的网络同时不稳定的概率较小,由它们一起做决策,误判率也能降低。
具体是怎么判定主节点为「客观下线」的呢?
当一个哨兵判断主节点为「主观下线」后,就会向其他哨兵发起命令,其他哨兵收到这个命令后,就会根据自身和主节点的网络状况,做出赞成投票或者拒绝投票的响应。

当这个哨兵的赞同票数达到哨兵配置文件中的 quorum 配置项设定的值后,这时主节点就会被该哨兵标记为「客观下线」。
例如,现在有 3 个哨兵,quorum 配置的是 2,那么一个哨兵需要 2 张赞成票,就可以标记主节点为“客观下线”了。这 2 张赞成票包括哨兵自己的一张赞成票和另外两个哨兵的赞成票。
PS:quorum 的值一般设置为哨兵个数的二分之一加1,例如 3 个哨兵就设置 2。
哨兵判断完主节点客观下线后,哨兵就要开始在多个「从节点」中,选出一个从节点来做新主节点。
由哪个哨兵进行主从故障转移?
前面说过,为了更加“客观”的判断主节点故障了,一般不会只由单个哨兵的检测结果来判断,而是多个哨兵一起判断,这样可以减少误判概率,所以 哨兵是以哨兵集群的方式存在的 。
问题来了,由哨兵集群中的哪个节点进行主从故障转移呢?
所以这时候,还需要在哨兵集群中选出一个 leeder,让 leeder 来执行主从切换。
选举 leeder 的过程其实是一个投票的过程,在投票开始前,肯定得有个「候选者」。
那谁来作为候选者呢?
哪个哨兵节点判断主节点为「客观下线」,这个哨兵节点就是候选者,所谓的候选者就是想当 Leader 的哨兵。
举个例子,假设有三个哨兵。当哨兵 B 先判断到主节点「主观下线后」,就会给其他实例发送 is-master-down-by-addr 命令。接着,其他哨兵会根据自己和主节点的网络连接情况,做出赞成投票或者拒绝投票的响应。

当哨兵 B 收到赞成票数达到哨兵配置文件中的 quorum 配置项设定的值后,就会将主节点标记为「客观下线」,此时的哨兵 B 就是一个Leader 候选者。
候选者如何选举成为 Leader?
候选者会向其他哨兵发送命令,表明希望成为 Leader 来执行主从切换,并让所有其他哨兵对它进行投票。
每个哨兵只有一次投票机会,如果用完后就不能参与投票了,可以投给自己或投给别人,但是只有候选者才能把票投给自己。
那么在投票过程中,任何一个「候选者」,要满足两个条件:
- 第一,拿到半数以上的赞成票;
- 第二,拿到的票数同时还需要大于等于哨兵配置文件中的 quorum 值。
举个例子,假设哨兵节点有 3 个,quorum 设置为 2,那么任何一个想成为 Leader 的哨兵只要拿到 2 张赞成票,就可以选举成功了。如果没有满足条件,就需要重新进行选举。
这时候有的同学就会问了,如果某个时间点,刚好有两个哨兵节点判断到主节点为客观下线,那这时不就有两个候选者了?这时该如何决定谁是 Leader 呢?
每位候选者都会先给自己投一票,然后向其他哨兵发起投票请求。如果投票者先收到「候选者 A」的投票请求,就会先投票给它,如果投票者用完投票机会后,收到「候选者 B」的投票请求后,就会拒绝投票。这时,候选者 A 先满足了上面的那两个条件,所以「候选者 A」就会被选举为 Leader。
为什么哨兵节点至少要有 3 个?
如果哨兵集群中只有 2 个哨兵节点,此时如果一个哨兵想要成功成为 Leader,必须获得 2 票,而不是 1 票。
所以,如果哨兵集群中有个哨兵挂掉了,那么就只剩一个哨兵了,如果这个哨兵想要成为 Leader,这时票数就没办法达到 2 票,就无法成功成为 Leader,这时是无法进行主从节点切换的。
因此,通常我们至少会配置 3 个哨兵节点。这时,如果哨兵集群中有个哨兵挂掉了,那么还剩下两个个哨兵,如果这个哨兵想要成为 Leader,这时还是有机会达到 2 票的,所以还是可以选举成功的,不会导致无法进行主从节点切换。
当然,你要问,如果 3 个哨兵节点,挂了 2 个怎么办?这个时候得人为介入了,或者增加多一点哨兵节点。
再说一个问题,Redis 1 主 4 从,5 个哨兵 ,quorum 设置为 3,如果 2 个哨兵故障,当主节点宕机时,哨兵能否判断主节点“客观下线”?主从能否自动切换?
- 哨兵集群可以判定主节点“客观下线” 。哨兵集群还剩下 3 个哨兵,当一个哨兵判断主节点“主观下线”后,询问另外 2 个哨兵后,有可能能拿到 3 张赞同票,这时就达到了 quorum 的值,因此,哨兵集群可以判定主节点为“客观下线”。
- 哨兵集群可以完成主从切换 。当有个哨兵标记主节点为「客观下线」后,就会进行选举 Leader 的过程,因为此时哨兵集群还剩下 3 个哨兵,那么还是可以拿到半数以上(5/2+1=3)的票,而且也达到了 quorum 值,满足了选举 Leader 的两个条件, 所以就能选举成功,因此哨兵集群可以完成主从切换。
如果 quorum 设置为 2 ,并且如果有 3 个哨兵故障的话。此时哨兵集群还是可以判定主节点为“客观下线”,但是哨兵不能完成主从切换了,大家可以自己推演下。
如果 quorum 设置为 3,并且如果有 3 个哨兵故障的话,哨兵集群即不能判定主节点为“客观下线”,也不能完成主从切换了。
可以看到,quorum 为 2 的时候,并且如果有 3 个哨兵故障的话,虽然可以判定主节点为“客观下线”,但是不能完成主从切换,这样感觉「判定主节点为客观下线」这件事情白做了一样,既然这样,还不如不要做,quorum 为 3 的时候,就可以避免这种无用功。
所以, quorum 的值建议设置为哨兵个数的二分之一加1 ,例如 3 个哨兵就设置 2,5 个哨兵设置为 3,而且 哨兵节点的数量应该是奇数 。
如何进行主从故障转移
主从故障转移操作包含以下四个步骤:
- 第一步:在已下线主节点(旧主节点)属下的所有「从节点」里面,挑选出一个从节点,并将其转换为主节点。
- 第二步:让已下线主节点属下的所有「从节点」修改复制目标,修改为复制「新主节点」;
- 第三步:将新主节点的 IP 地址和信息,通过「发布者/订阅者机制」通知给客户端;
- 第四步:继续监视旧主节点,当这个旧主节点重新上线时,将它设置为新主节点的从节点;
步骤一:选出新主节点
故障转移操作第一步要做的就是在已下线主节点属下的所有「从节点」中,挑选出一个状态良好、数据完整的从节点,然后向这个「从节点」发送 SLAVEOF no one 命令,将这个「从节点」转换为「主节点」。
那么多「从节点」,到底选择哪个从节点作为新主节点的?
随机的方式好吗?随机的方式,实现起来很简单,但是如果选到一个网络状态不好的从节点作为新主节点,那么可能在将来不久又要做一次主从故障迁移。
所以,我们首先要把网络状态不好的从节点给过滤掉。首先把已经下线的从节点过滤掉,然后把以往网络连接状态不好的从节点也给过滤掉。
怎么判断从节点之前的网络连接状态不好呢?
Redis 有个叫 down-after-milliseconds * 10 配置项,其down-after-milliseconds 是主从节点断连的最大连接超时时间。如果在 down-after-milliseconds 毫秒内,主从节点都没有通过网络联系上,我们就可以认为主从节点断连了。如果发生断连的次数超过了 10 次,就说明这个从节点的网络状况不好,不适合作为新主节点。
至此,我们就把网络状态不好的从节点过滤掉了,接下来要对所有从节点进行三轮考察: 优先级、复制进度、ID 号 。在进行每一轮考察的时候,哪个从节点优先胜出,就选择其作为新主节点。
- 第一轮考察:哨兵首先会根据从节点的优先级来进行排序,优先级越小排名越靠前,
- 第二轮考察:如果优先级相同,则查看复制的下标,哪个从「主节点」接收的复制数据多,哪个就靠前。
- 第三轮考察:如果优先级和下标都相同,就选择从节点 ID 较小的那个。
第一轮考察:优先级最高的从节点胜出
Redis 有个叫 slave-priority 配置项,可以给从节点设置优先级。
每一台从节点的服务器配置不一定是相同的,我们可以根据服务器性能配置来设置从节点的优先级。
比如,如果 「 A 从节点」的物理内存是所有从节点中最大的, 那么我们可以把「 A 从节点」的优先级设置成最高。这样当哨兵进行第一轮考虑的时候,优先级最高的 A 从节点就会优先胜出,于是就会成为新主节点。
第二轮考察:复制进度最靠前的从节点胜出
如果在第一轮考察中,发现优先级最高的从节点有两个,那么就会进行第二轮考察,比较两个从节点哪个复制进度。
什么是复制进度?主从架构中,主节点会将写操作同步给从节点,在这个过程中,主节点会用 master_repl_offset 记录当前的最新写操作在 repl_backlog_buffer 中的位置(如下图中的「主服务器已经写入的数据」的位置),而从节点会用 slave_repl_offset 这个值记录当前的复制进度(如下图中的「从服务器要读的位置」的位置)。
如果某个从节点的 slave_repl_offset 最接近 master_repl_offset,说明它的复制进度是最靠前的,于是就可以将它选为新主节点。
第三轮考察:ID 号小的从节点胜出
如果在第二轮考察中,发现有两个从节点优先级和复制进度都是一样的,那么就会进行第三轮考察,比较两个从节点的 ID 号,ID 号小的从节点胜出。
什么是 ID 号?每个从节点都有一个编号,这个编号就是 ID 号,是用来唯一标识从节点的。
到这里,选主的事情终于结束了。简单给大家总结下:
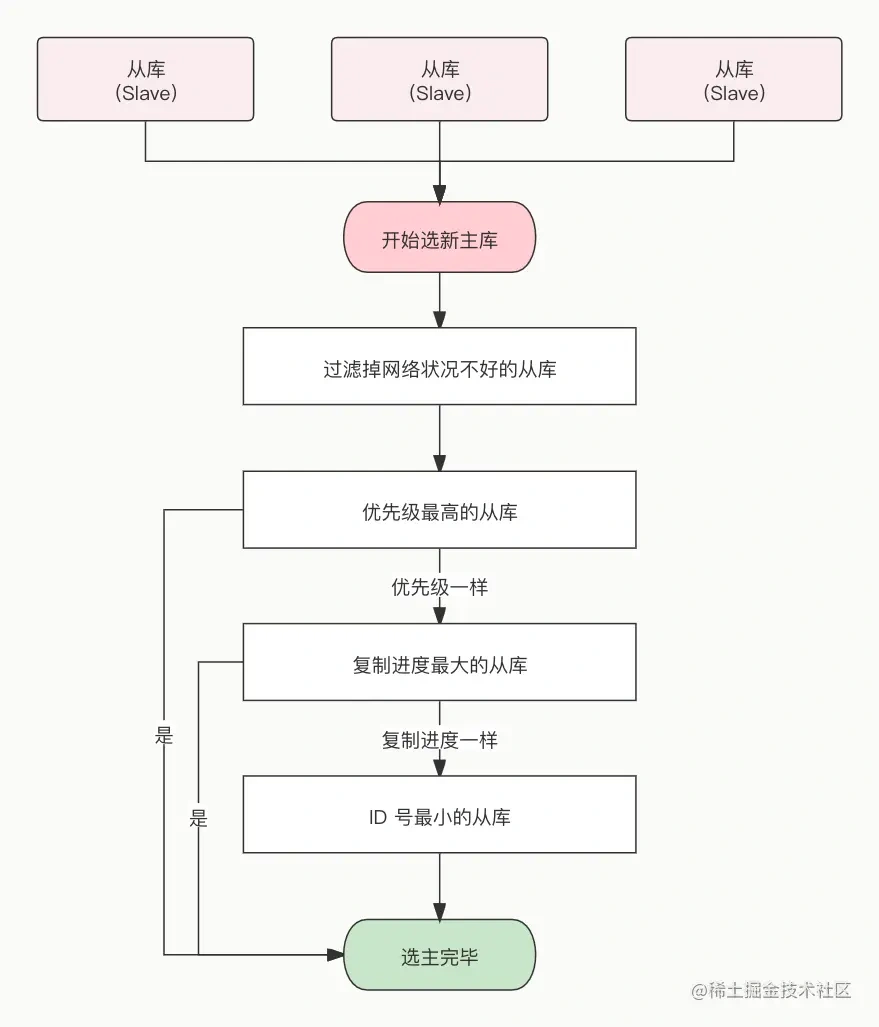
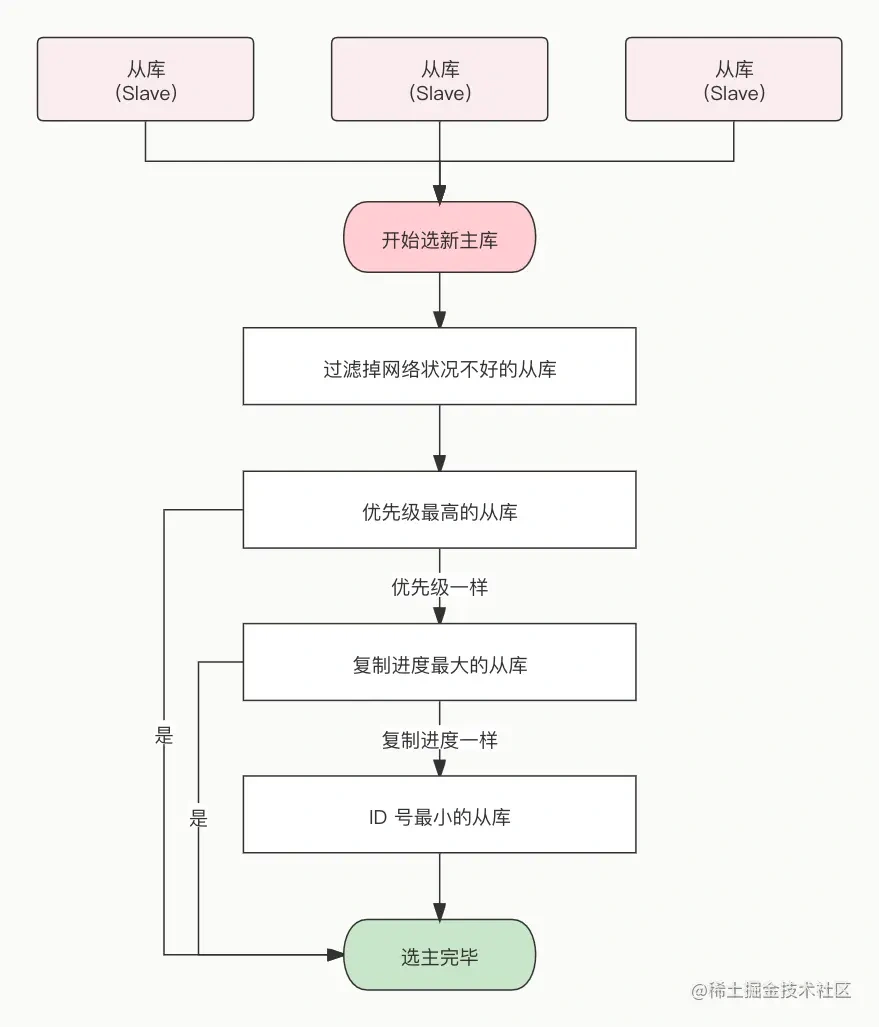
在选举出从节点后,哨兵 leader 向被选中的从节点发送 SLAVEOF no one 命令,让这个从节点解除从节点的身份,将其变为新主节点。
哨兵 leader 向被选中的从节点 server2 发送 SLAVEOF no one 命令,将该从节点升级为新主节点。
在发送 SLAVEOF no one 命令之后,哨兵 leader 会以每秒一次的频率向被升级的从节点发送 INFO 命令(没进行故障转移之前,INFO 命令的频率是每十秒一次),并观察命令回复中的角色信息,当被升级节点的角色信息从原来的 slave 变为 master 时,哨兵 leader 就知道被选中的从节点已经顺利升级为主节点了。
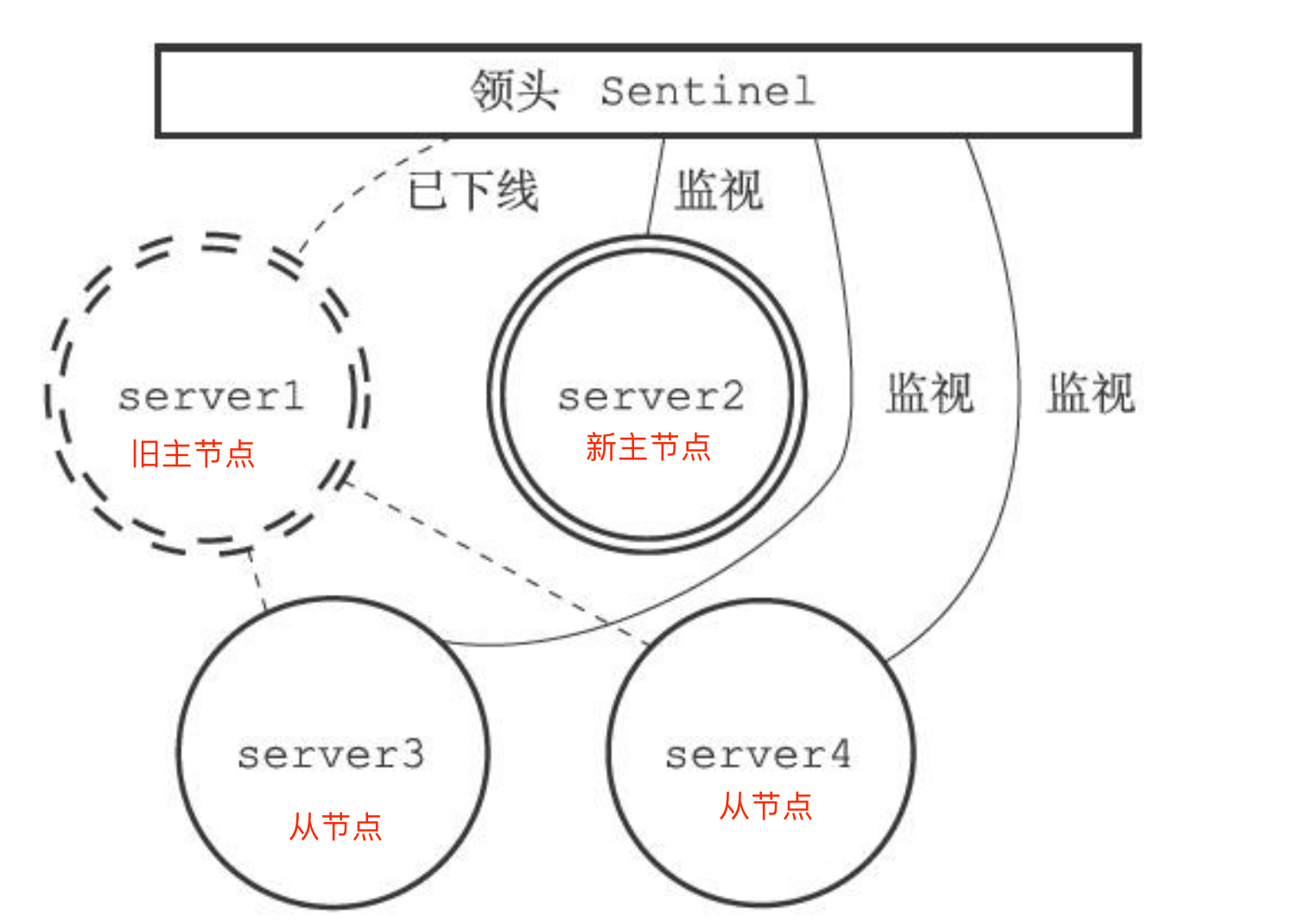 步骤二:将从节点指向新主节点
步骤二:将从节点指向新主节点
当新主节点出现之后,哨兵 leader 下一步要做的就是,让已下线主节点属下的所有「从节点」指向「新主节点」,这一动作可以通过向「从节点」发送 SLAVEOF 命令来实现。
如下图,哨兵 leader 向所有从节点(server3和server4)发送 SLAVEOF ,让它们成为新主节点的从节点。
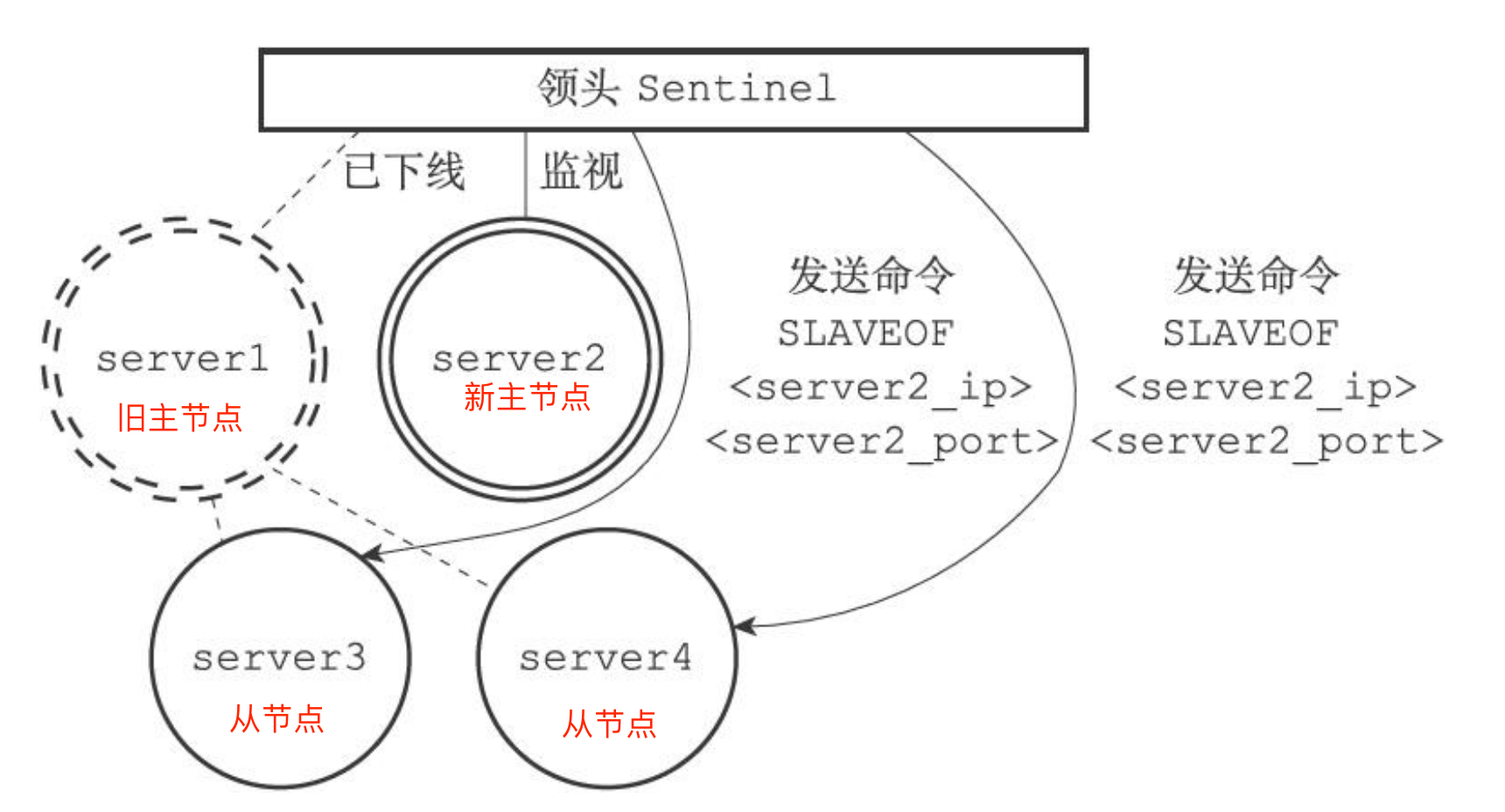
步骤三:通知客户端的主节点已更换
经过前面一系列的操作后,哨兵集群终于完成主从切换的工作,那么新主节点的信息要如何通知给客户端呢?
这主要通过 Redis 的发布者/订阅者机制来实现的。每个哨兵节点提供发布者/订阅者机制,客户端可以从哨兵订阅消息。
哨兵提供的消息订阅频道有很多,不同频道包含了主从节点切换过程中的不同关键事件,几个常见的事件如下:
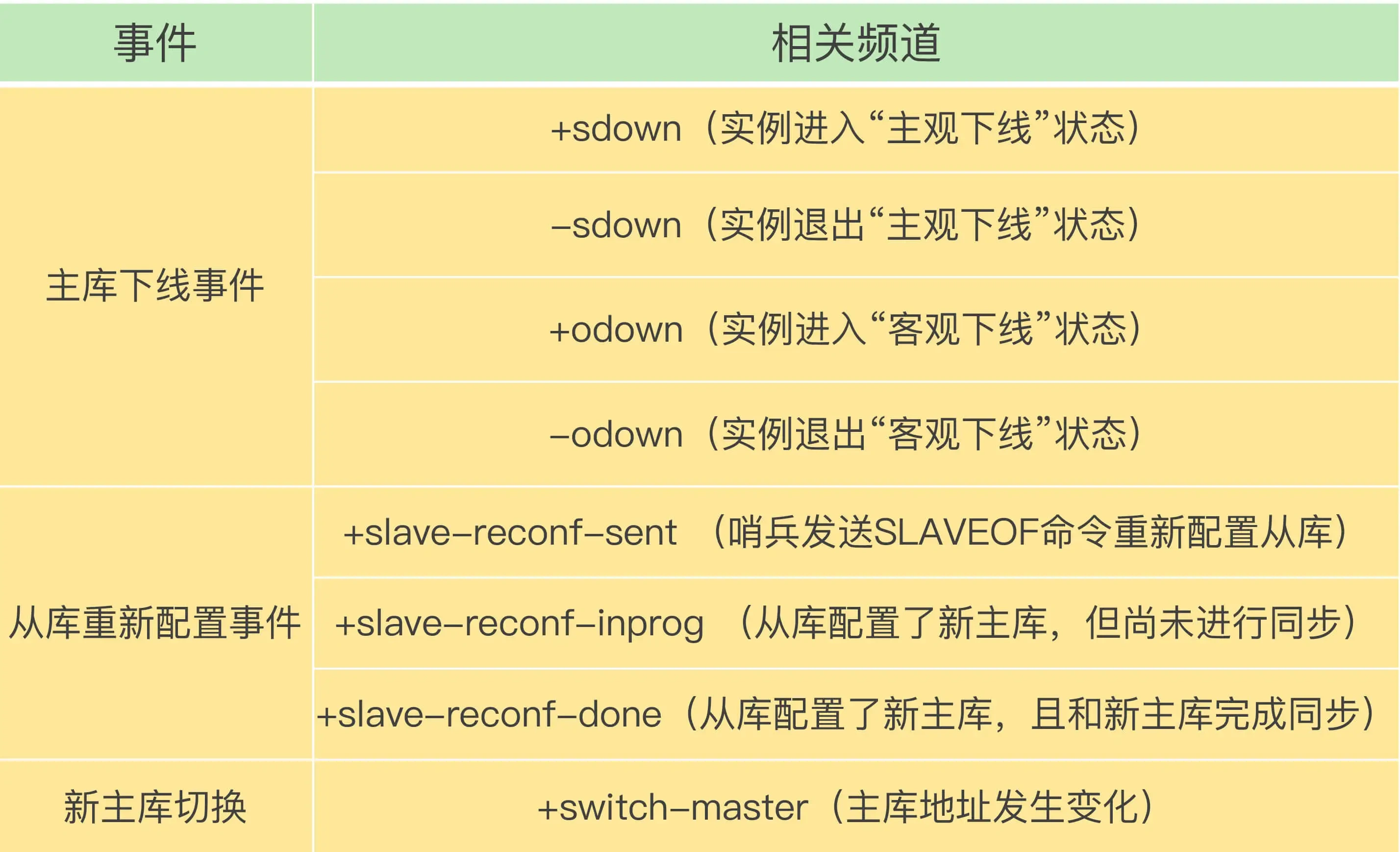
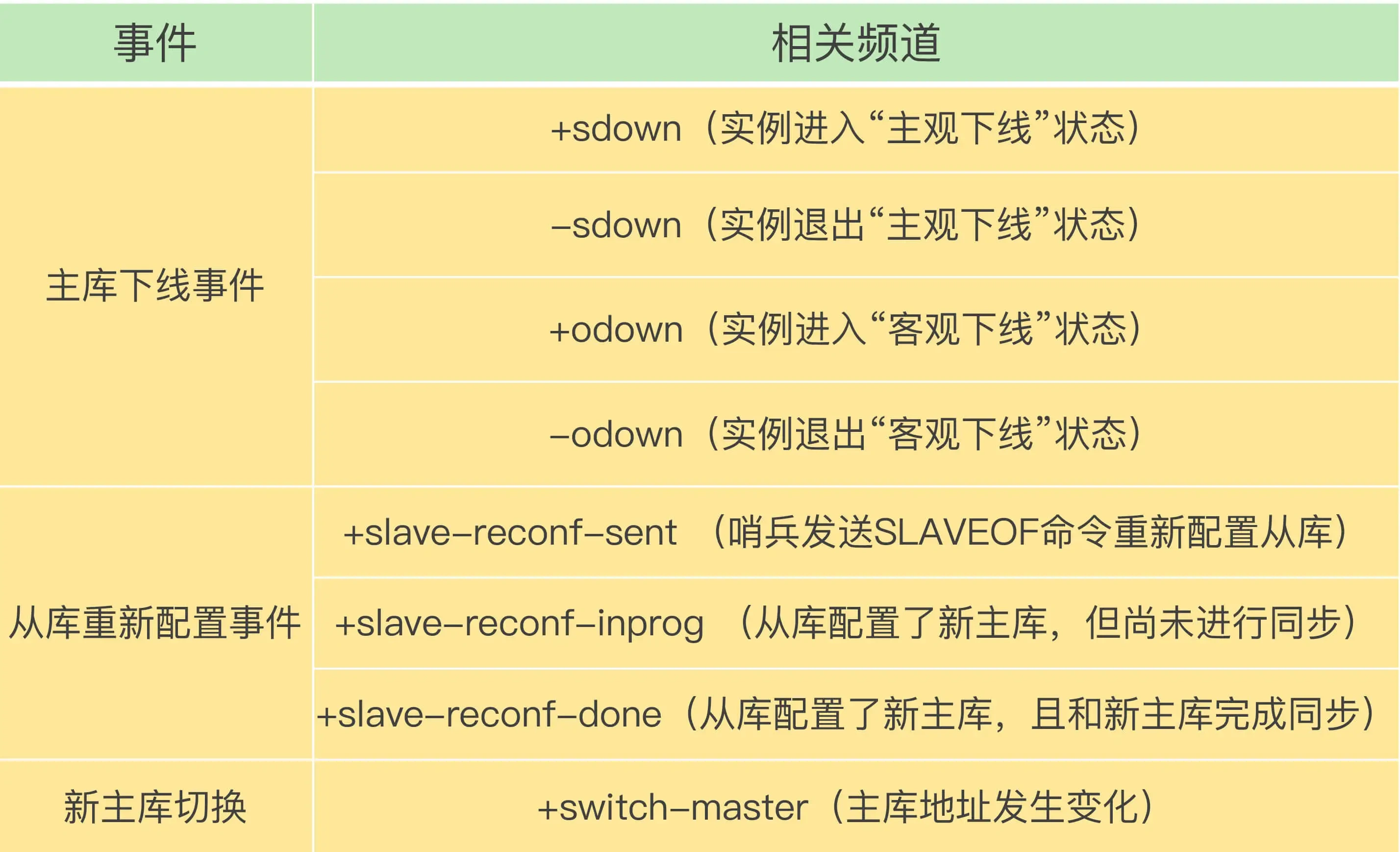
客户端和哨兵建立连接后,客户端会订阅哨兵提供的频道。 主从切换完成后,哨兵就会向 +switch-master 频道发布新主节点的 IP 地址和端口的消息,这个时候客户端就可以收到这条信息,然后用这里面的新主节点的 IP 地址和端口进行通信了 。
通过发布者/订阅者机制机制,有了这些事件通知,客户端不仅可以在主从切换后得到新主节点的连接信息,还可以监控到主从节点切换过程中发生的各个重要事件。这样,客户端就可以知道主从切换进行到哪一步了,有助于了解切换进度。
步骤四:将旧主节点变为从节点
故障转移操作最后要做的是,继续监视旧主节点,当旧主节点重新上线时,哨兵集群就会向它发送 SLAVEOF 命令,让它成为新主节点的从节点。
至此,整个主从节点的故障转移的工作结束。
哨兵集群是如何组成的
前面提到了 Redis 的发布者/订阅者机制,那就不得不提一下哨兵集群的组成方式,因为它也用到了这个技术。
在我第一次搭建哨兵集群的时候,当时觉得很诧异。因为在配置哨兵的信息时,竟然只需要填下面这几个参数,设置主节点名字、主节点的 IP 地址和端口号以及 quorum 值。
sentinel monitor <master-name> <ip> <redis-port> <quorum>
不需要填其他哨兵节点的信息,我就好奇它们是如何感知对方的,又是如何组成哨兵集群的?
后面才了解到, 哨兵节点之间是通过 Redis 的发布者/订阅者机制来相互发现的 。
在主从集群中,主节点上有一个名为 __sentinel__:hello的频道,不同哨兵就是通过它来相互发现,实现互相通信的。
在下图中,哨兵 A 把自己的 IP 地址和端口的信息发布到 __sentinel__:hello 频道上,哨兵 B 和 C 订阅了该频道。那么此时,哨兵 B 和 C 就可以从这个频道直接获取哨兵 A 的 IP 地址和端口号。然后,哨兵 B、C 可以和哨兵 A 建立网络连接。

通过这个方式,哨兵 B 和 C 也可以建立网络连接,这样一来,哨兵集群就形成了。
哨兵集群会对「从节点」的运行状态进行监控,那哨兵集群如何知道「从节点」的信息?
主节点知道所有「从节点」的信息,所以哨兵会每 10 秒一次的频率向主节点发送 INFO 命令来获取所有「从节点」的信息。
如下图所示,哨兵 B 给主节点发送 INFO 命令,主节点接受到这个命令后,就会把从节点列表返回给哨兵。接着,哨兵就可以根据从节点列表中的连接信息,和每个从节点建立连接,并在这个连接上持续地对从节点进行监控。哨兵 A 和 C 可以通过相同的方法和从节点建立连接。

正式通过 Redis 的发布者/订阅者机制,哨兵之间可以相互感知,然后组成集群,同时,哨兵又通过 INFO 命令,在主节点里获得了所有从节点连接信息,于是就能和从节点建立连接,并进行监控了。
测试哨兵模式
# 启动三个redis进程
[root@VM-4-2-centos bin]# redis-server ./6379.conf
[root@VM-4-2-centos bin]# redis-server ./6380.conf --replicaof 127.0.0.1 6379
[root@VM-4-2-centos bin]# redis-server ./6381.conf --replicaof 127.0.0.1 6379
# 启动三个哨兵
[root@VM-4-2-centos bin]# redis-server ./6379_2.conf --sentinel
[root@VM-4-2-centos bin]# redis-server ./6380_2.conf --sentinel
[root@VM-4-2-centos bin]# redis-server ./6381_2.conf --sentinel
出现下面信息
20323:X 23 Jun 2022 22:15:54.687 # Sentinel ID is 859bc747a31557947e44ac5305b97221ebc3a0e7
20323:X 23 Jun 2022 22:15:54.687 # +monitor master mymaster 127.0.0.1 6379 quorum 2
20323:X 23 Jun 2022 22:15:54.687 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
20323:X 23 Jun 2022 22:15:54.693 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
# 关闭6379,等待一段时间,哨兵会选出新的master
哈希环
用代理nginx来负载均衡redis
client----lvs(来负载均衡nginx集群)----nginx(代理redis)---redis
twemproxy
predixy:redis代理
codis
cluster
切片集群模式
当 Redis 缓存数据量大到一台服务器无法缓存时,就需要使用 Redis 切片集群 (Redis Cluster )方案,它将数据分布在不同的服务器上,以此来降低系统对单主节点的依赖,从而提高 Redis 服务的读写性能。
Redis Cluster 方案采用哈希槽(Hash Slot),来处理数据和节点之间的映射关系。在 Redis Cluster 方案中, 一个切片集群共有 16384 个哈希槽 ,这些哈希槽类似于数据分区,每个键值对都会根据它的 key,被映射到一个哈希槽中,具体执行过程分为两大步:
- 根据键值对的 key,按照 CRC16 算法 (opens new window)计算一个 16 bit 的值。
- 再用 16bit 值对 16384 取模,得到 0~16383 范围内的模数,每个模数代表一个相应编号的哈希槽。
接下来的问题就是,这些哈希槽怎么被映射到具体的 Redis 节点上的呢?有两种方案:
- 平均分配: 在使用 cluster create 命令创建 Redis 集群时,Redis 会自动把所有哈希槽平均分布到集群节点上。比如集群中有 9 个节点,则每个节点上槽的个数为 16384/9 个。
- 手动分配: 可以使用 cluster meet 命令手动建立节点间的连接,组成集群,再使用 cluster addslots 命令,指定每个节点上的哈希槽个数。
为了方便你的理解,我通过一张图来解释数据、哈希槽,以及节点三者的映射分布关系。
上图中的切片集群一共有 3 个节点,假设有 4 个哈希槽(Slot 0~Slot 3)时,我们就可以通过命令手动分配哈希槽,比如节点 1 保存哈希槽 0 和 1,节点 2 保存哈希槽 2 和 3。
redis-cli -h 192.168.1.10 –p 6379 cluster addslots 0,1
redis-cli -h 192.168.1.11 –p 6379 cluster addslots 2,3
然后在集群运行的过程中,key1 和 key2 计算完 CRC16 值后,对哈希槽总个数 5 进行取模,再根据各自的模数结果,就可以被映射到对应的节点 1 和节点 3 上了。
需要注意的是,在手动分配哈希槽时,需要把 16384 个槽都分配完,否则 Redis 集群无法正常工作。
集群-代理
Redis Cluster要求至少需要3个master才能组成一个集群,同时每个master至少需要有一个slave节点。各个节点之间保持TCP通信。当master发生了宕机, Redis Cluster自动会将对应的slave节点提拔为master,来重新对外提供服务。
Redis Cluster 功能 : 负载均衡,故障切换,主从复制 。
当redis客户端设置值时,会拿key进行CRC16算法,然后 跟16384取模,得到的就是落在哪个槽位,根据上面表格就得出在哪台节点上。槽公式如下:
slot = CRC16(key) & 16383
Redis集群中,每个节点都会有其余节点ip,负责的槽 等 信息。
twemproxy
[root@VM-4-2-centos twemproxy]# yum install -y git
[root@VM-4-2-centos twemproxy]# git clone https://github.com/twitter/twemproxy.git
# 安装工具
[root@VM-4-2-centos twemproxy]# yum install automake libtool -y
[root@VM-4-2-centos twemproxy]# autoreconf -fvi
[root@VM-4-2-centos twemproxy]# ./configure
[root@VM-4-2-centos twemproxy]# make
[root@VM-4-2-centos src]# # cd src/ 发现有nutcracker文件
[root@VM-4-2-centos scripts]# cp nutcracker.init /etc/init.d/twemproxy
[root@VM-4-2-centos scripts]# cd /etc/init.d/
[root@VM-4-2-centos scripts]# chmod +x twemproxy
[root@VM-4-2-centos ~]# mkdir /etc/nutcracker
# 进入此目录,复制配置文件
[root@VM-4-2-centos conf]# pwd
/usr/local/software/twemproxy/twemproxy/conf
[root@VM-4-2-centos conf]# cp ./* /etc/nutcracker/ # 配置文件就放在这个地方
cd ..
[root@VM-4-2-centos twemproxy]# cd src/
[root@VM-4-2-centos twemproxy]# cp nutcracker /usr/bin
# 进行配置文件的修改
cd /etc/nutcracker/
删除除了alpha模块后所有内容 (快捷键d+G)
保留一下内容
alpha:
listen: 127.0.0.1:22121
hash: fnv1a_64
distribution: ketama
auto_eject_hosts: true
redis: true
server_retry_timeout: 2000
server_failure_limit: 1
servers:
- 127.0.0.1:6379:1
- 127.0.0.1:6380:1
# 准备一个data文件夹,里面创建两个文件夹6379和6380
进入两个文件夹,分别手动启动reids,redis-server --port 6379,redis-server --port 6380
# 启动代理
[root@VM-4-2-centos nutcracker]# service twemproxy start
Reloading systemd: [ OK ]
Starting twemproxy (via systemctl): [ OK ]
# 进入22121(代理的端口)
[root@VM-4-2-centos ~]# redis-cli -p 22121
127.0.0.1:22121>
# 测试写入和读取
127.0.0.1:22121> set k1 1
OK
127.0.0.1:22121> get k1
"1"
# 这个k1到底存在哪里呢?
[root@VM-4-2-centos ~]# redis-cli -p 6379
127.0.0.1:6379> keys *
(empty array)
[root@VM-4-2-centos ~]# redis-cli -p 6380
127.0.0.1:6380> keys *
1) "k1"
# twemproxy代理的弊端
127.0.0.1:22121> keys * # 不支持keys *
Error: Server closed the connection
127.0.0.1:22121> watch k1 # 不支持WATCH
Error: Server closed the connection
127.0.0.1:22121> MULTI # 不支持事务
Error: Server closed the connection
predixy
测试启动两个集群,每个集群一主(36379、46379)一从(36380、46380)。启动三个哨兵(26379、26380、26381)
# 官网
https://github.com/joyieldInc/predixy
https://github.com/joyieldInc/predixy/releases
# 下载
[root@VM-4-2-centos predixy]# pwd
/usr/local/software/predixy
[root@VM-4-2-centos predixy]# wget https://github.com/joyieldInc/predixy/releases/download/1.0.5/predixy-1.0.5-bin-amd64-linux.tar.gz
# 修改predixy.conf配置文件
放开哨兵: Include sentinel.conf
放开绑定的端口: Bind 127.0.0.1:7617
# 编辑sentinel.conf文件
从#SentinelServerPool {光标放到这一行,开始复制
编辑输入 :.,$y
光标到最后一行 按p进行粘贴
删掉#
:.,$s/#//
# 修改哨兵,哨兵是一个集群
Sentinels {
+ 127.0.0.1:26379
+ 127.0.0.1:26380
+ 127.0.0.1:26381
}
Group ooxx {
}
Group xxoo {
}
# 进入哨兵的配置文件目录
[root@VM-4-2-centos bin]# pwd
/usr/local/software/redis-6.0.6/bin
# 修改三个哨兵配置文件
[root@VM-4-2-centos bin]# vim 6379_2.conf
port 26379
sentinel monitor ooxx 127.0.0.1 36379 2
sentinel monitor xxoo 127.0.0.1 46379 2
[root@VM-4-2-centos bin]# vim 6380_2.conf
port 26380
sentinel monitor ooxx 127.0.0.1 36379 2
sentinel monitor xxoo 127.0.0.1 46379 2
[root@VM-4-2-centos bin]# vim 6380_2.conf
port 26381
sentinel monitor ooxx 127.0.0.1 36379 2
sentinel monitor xxoo 127.0.0.1 46379 2
含义就是26379这个哨兵,监控36369和46379集群的这两个master
# 启动三个哨兵
[root@VM-4-2-centos bin]# redis-server 6379_2.conf --sentinel
[root@VM-4-2-centos bin]# redis-server 6380_2.conf --sentinel
[root@VM-4-2-centos bin]# redis-server 6381_2.conf --sentinel
# 启动两个主redis
[root@VM-4-2-centos 36379]# redis-server --port 36379
[root@VM-4-2-centos 46379]# redis-server --port 46379
# 启动两个从redis
[root@VM-4-2-centos 36380]# redis-server --port 36380 --replicaof 127.0.0.1 36379
[root@VM-4-2-centos 46380]# redis-server --port 46380 --replicaof 127.0.0.1 46379
# 启动predixy代理,代理发现三个哨兵,哨兵发现主从关系
[root@VM-4-2-centos bin]# ./predixy ../conf/predixy.conf
2022-06-25 10:53:56.651513 N Proxy.cpp:112 predixy listen in 127.0.0.1:7617
2022-06-25 10:53:56.651583 N Proxy.cpp:143 predixy running with Name:PredixyExample Workers:1
2022-06-25 10:53:56.651665 N Handler.cpp:454 h 0 create connection pool for server 127.0.0.1:26380
2022-06-25 10:53:56.651679 N ConnectConnectionPool.cpp:42 h 0 create server connection 127.0.0.1:26380 5
2022-06-25 10:53:56.651731 N Handler.cpp:454 h 0 create connection pool for server 127.0.0.1:26379
2022-06-25 10:53:56.651741 N ConnectConnectionPool.cpp:42 h 0 create server connection 127.0.0.1:26379 6
2022-06-25 10:53:56.651771 N Handler.cpp:454 h 0 create connection pool for server 127.0.0.1:26381
2022-06-25 10:53:56.651779 N ConnectConnectionPool.cpp:42 h 0 create server connection 127.0.0.1:26381 7
2022-06-25 10:53:56.651948 N StandaloneServerPool.cpp:422 sentinel server pool group ooxx create master server 127.0.0.1:36379
2022-06-25 10:53:56.651972 N StandaloneServerPool.cpp:472 sentinel server pool group ooxx create slave server 127.0.0.1:36380
2022-06-25 10:53:56.651987 N StandaloneServerPool.cpp:472 sentinel server pool group xxoo create slave server 127.0.0.1:46380
2022-06-25 10:53:56.652008 N StandaloneServerPool.cpp:422 sentinel server pool group xxoo create master server 127.0.0.1:46379
# 查看,7617是predixy代理的端口号
[root@VM-4-2-centos ~]# redis-cli -p 7617
127.0.0.1:7617> set k1 aaaa
OK
127.0.0.1:7617> get k1
"aaaa"
127.0.0.1:7617> set k2 bbbb
OK
# 查看k1和k2存在哪个集群里面
[root@VM-4-2-centos ~]# redis-cli -p 36379
127.0.0.1:36379> keys *
1) "k1"
[root@VM-4-2-centos ~]# redis-cli -p 46379
127.0.0.1:46379> keys *
1) "k2"
# 将数据放到指定的集群里
127.0.0.1:7617> set {oo}k1 asasa
OK
127.0.0.1:7617> set {oo}k2 asasa
OK
127.0.0.1:46379> keys *
1) "{oo}k2"
2) "k2"
3) "{oo}k1"
# 但是操作不允许,因为这是集群,group有两个集群,所以不允许事务这些操作,如果在predixy配置文件中只保留一个pool,那么就允许
127.0.0.1:7617> watch k1
(error) ERR forbid transaction in current server pool
127.0.0.1:7617> MULTI
(error) ERR forbid transaction in current server pool
自带集群
[root@VM-4-2-centos create-cluster]# pwd
/usr/local/software/redis-6.0.6/utils/create-cluster
./create-cluster start
./create-cluster create
redis-cli -c -p 30001
./create-cluster stop
./create-cluster clean
# 手动创建集群,slot 槽点
redis-cli --cluster create 127.0.0.1:30001 127.0.0.1:30002 127.0.0.1:30003 127.0.0.1:30004 127.0.0.1:30005 127.0.0.1:30006 --cluster-replica 1
# 移动槽位
redis-cli --cluster reshard 127.0.0.1:30001
七:分布式锁
redis key-value
exits key ==1如果key存在,那就说明有人拿到锁,正在做
==0 那就set去抢占锁
但是exits和set没法保证原子性,因为这是两个语句
使用setnx,指令的执行是单线程的,原子的。但是setnx只能是string类型的
lua脚本:保证多个指令的原子性,并且能拿到中间指令的执行结果作为后续判断。
为什么不用事务去保证原子性?事务是多个指令一起执行,不能获得中间结果作为后续判断
锁要设置过期时间:防止死锁
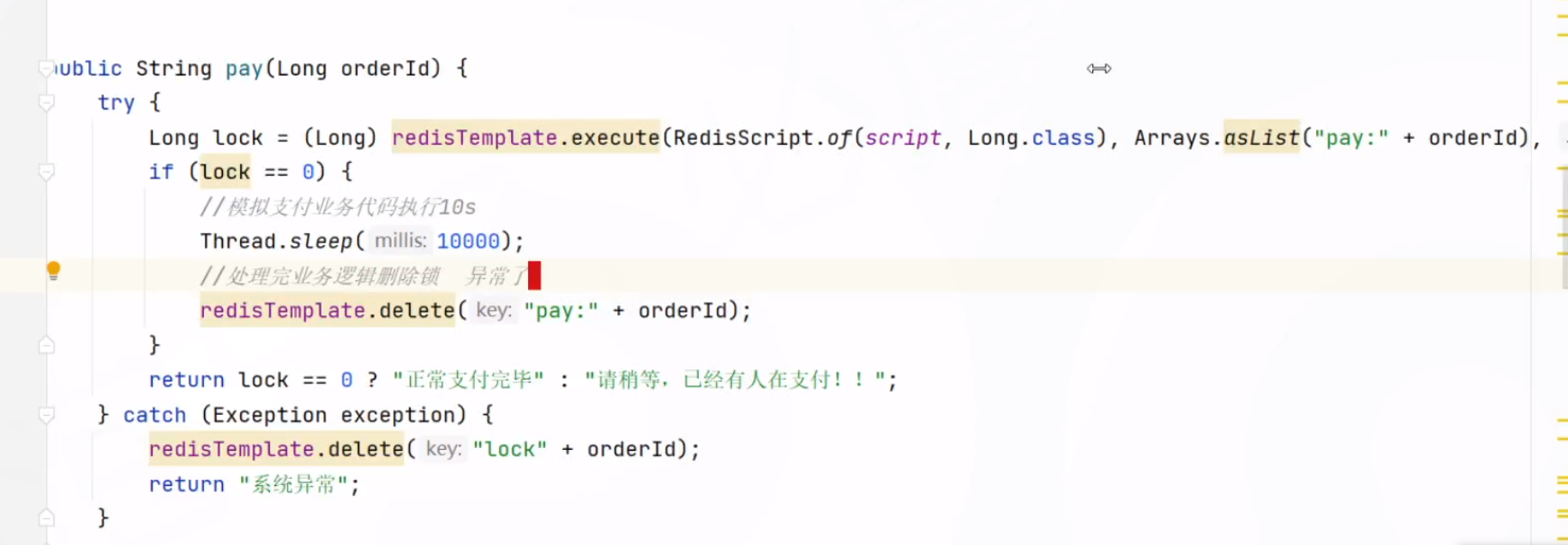
一:实现重入锁怎么办?
1.能做锁-不同线程的互斥 key
2.记录线程信息,判断当前的线程是否为获得锁的线程 field
3.记录重入的次数 value+1
二:假如时间过期后,业务没做完怎么办?
续期
定期检查,如果锁没释放,看是否在做业务逻辑,可以去续期
定时调度,不能一直调度,key必须存在才行
看门狗
时间轮-是延时执行
redisson是怎么解决的?
八:缓存穿透、击穿、雪崩
认知
用户的数据一般都是存储于数据库,数据库的数据是落在磁盘上的,磁盘的读写速度可以说是计算机里最慢的硬件了。
当用户的请求,都访问数据库的话,请求数量一上来,数据库很容易就奔溃的了,所以为了避免用户直接访问数据库,会用 Redis 作为缓存层。
因为 Redis 是内存数据库,我们可以将数据库的数据缓存在 Redis 里,相当于数据缓存在内存,内存的读写速度比硬盘快好几个数量级,这样大大提高了系统性能。
引入了缓存层,就会有缓存异常的三个问题,分别是 缓存雪崩、缓存击穿、缓存穿透 。
缓存穿透
什么是缓存穿透
当用户访问的数据, 既不在缓存中,也不在数据库中 ,导致请求在访问缓存时,发现缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据,没办法构建缓存数据,来服务后续的请求。那么当有大量这样的请求到来时,数据库的压力骤增,这就是缓存穿透的问题。
redis作为缓存,大量请求访问数据库和缓存不存在的数据。结果无法存入缓存,对数据库造成很大压力。
缓存穿透发生的情况
缓存穿透的发生一般有这两种情况:
- 业务误操作,缓存中的数据和数据库中的数据都被误删除了,所以导致缓存和数据库中都没有数据;
- 黑客恶意攻击,故意大量访问某些读取不存在数据的业务;
如何应对缓存穿透
应对缓存穿透的方案,常见的方案有三种。
- 第一种方案,非法请求的限制;
- 第二种方案,缓存空值或者默认值;如果查询不存在的数据,就设置key为null
- 第三种方案,使用布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在;
布隆过滤器(第一种客户端包含布隆过滤器,第二种客户端包含算法,bitmap放到redis中。第三种redis集成布隆过滤器)。问题:只能增加,不能删除。布谷鸟
第一种方案,非法请求的限制
当有大量恶意请求访问不存在的数据的时候,也会发生缓存穿透,因此在 API 入口处我们要判断求请求参数是否合理,请求参数是否含有非法值、请求字段是否存在,如果判断出是恶意请求就直接返回错误,避免进一步访问缓存和数据库。
第二种方案,缓存空值或者默认值
当我们线上业务发现缓存穿透的现象时,可以针对查询的数据,在缓存中设置一个空值或者默认值,这样后续请求就可以从缓存中读取到空值或者默认值,返回给应用,而不会继续查询数据库。
第三种方案,使用布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在
我们可以在写入数据库数据时,使用布隆过滤器做个标记,然后在用户请求到来时,业务线程确认缓存失效后,可以通过查询布隆过滤器快速判断数据是否存在,如果不存在,就不用通过查询数据库来判断数据是否存在。
即使发生了缓存穿透,大量请求只会查询 Redis 和布隆过滤器,而不会查询数据库,保证了数据库能正常运行,Redis 自身也是支持布隆过滤器的。
布隆过滤器
布隆过滤器由「初始值都为 0 的位图数组」和「 N 个哈希函数」两部分组成。当我们在写入数据库数据时,在布隆过滤器里做个标记,这样下次查询数据是否在数据库时,只需要查询布隆过滤器,如果查询到数据没有被标记,说明不在数据库中。
布隆过滤器会通过 3 个操作完成标记:
- 第一步,使用 N 个哈希函数分别对数据做哈希计算,得到 N 个哈希值;
- 第二步,将第一步得到的 N 个哈希值对位图数组的长度取模,得到每个哈希值在位图数组的对应位置。
- 第三步,将每个哈希值在位图数组的对应位置的值设置为 1;
举个例子,假设有一个位图数组长度为 8,哈希函数 3 个的布隆过滤器。
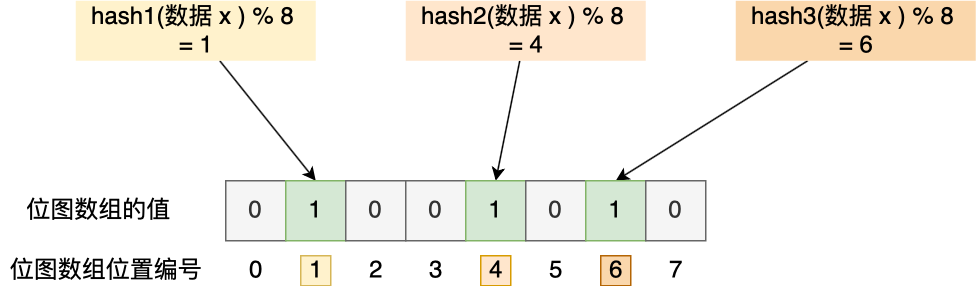
在数据库写入数据 x 后,把数据 x 标记在布隆过滤器时,数据 x 会被 3 个哈希函数分别计算出 3 个哈希值,然后在对这 3 个哈希值对 8 取模,假设取模的结果为 1、4、6,然后把位图数组的第 1、4、6 位置的值设置为 1。 当应用要查询数据 x 是否数据库时,通过布隆过滤器只要查到位图数组的第 1、4、6 位置的值是否全为 1,只要有一个为 0,就认为数据 x 不在数据库中 。
布隆过滤器由于是基于哈希函数实现查找的,高效查找的同时 存在哈希冲突的可能性 ,比如数据 x 和数据 y 可能都落在第 1、4、6 位置,而事实上,可能数据库中并不存在数据 y,存在误判的情况。
所以,查询布隆过滤器说数据存在,并不一定证明数据库中存在这个数据,但是查询到数据不存在,数据库中一定就不存在这个数据。
缓存击穿
什么是缓存击穿
业务通常会有几个数据会被频繁地访问,比如秒杀活动,这类被频地访问的数据被称为热点数据。
如果缓存中的某个热点数据过期了,此时大量的请求访问了该热点数据,就无法从缓存中读取,直接访问数据库,数据库很容易就被高并发的请求冲垮,这就是缓存击穿的问题。
redis作为缓存时,key有过期时间,开启LRU和LFU,可能会将冷数据缓存清除掉
客户端–访问缓存redis----redis的数据缓存key过期,这时候有大量的请求(高并发)来访问这个key,结果全部转接到db上了。叫做缓存击穿。
也就是key过期,导致大量 并发访问数据库。
解决缓存击穿
- 互斥锁方案,保证同一时间只有一个业务线程更新缓存,未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值。加锁可能会发生死锁,所以可以加上锁的过期时间。用多线程,一个线程取db,一个线程监控是否取到数据,更新锁时间。
- 不给热点数据设置过期时间,由后台异步更新缓存,或者在热点数据准备要过期前,提前通知后台线程更新缓存以及重新设置过期时间。也就是热点数据永不过期。
缓存雪崩
什么是缓存雪崩?
为了保证缓存中的数据与数据库中的数据一致性,会给 Redis 里的数据设置过期时间,当缓存数据过期后,用户访问的数据如果不在缓存里,业务系统需要重新生成缓存,因此就会访问数据库,并将数据更新到 Redis 里,这样后续请求都可以直接命中缓存。
那么,当大量缓存数据在同一时间过期(失效)或者 Redis 故障宕机时,如果此时有大量的用户请求,都无法在 Redis 中处理,于是全部请求都直接访问数据库,从而导致数据库的压力骤增,严重的会造成数据库宕机,从而形成一系列连锁反应,造成整个系统崩溃,这就是缓存雪崩的问题。
发生缓存雪崩的情况
发生缓存雪崩有两个原因:
- 大量数据同时过期;
- Redis 故障宕机;
解决缓存雪崩
大量数据同时过期
解决方法:
- 均匀设置过期时间;或者随机过期时间(与时点性无关)
- 互斥锁;
- 双 key 策略;
- 后台更新缓存;
- 热点数据永不过期
1. 均匀设置过期时间
如果要给缓存数据设置过期时间,应该避免将大量的数据设置成同一个过期时间。我们可以在对缓存数据设置过期时间时, 给这些数据的过期时间加上一个随机数 ,这样就保证数据不会在同一时间过期。
2. 互斥锁
当业务线程在处理用户请求时, 如果发现访问的数据不在 Redis 里,就加个互斥锁,保证同一时间内只有一个请求来构建缓存 (从数据库读取数据,再将数据更新到 Redis 里),当缓存构建完成后,再释放锁。未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值。
实现互斥锁的时候,最好设置 超时时间 ,不然第一个请求拿到了锁,然后这个请求发生了某种意外而一直阻塞,一直不释放锁,这时其他请求也一直拿不到锁,整个系统就会出现无响应的现象。
3. 双 key 策略
我们对缓存数据可以使用两个 key,一个是 主 key,会设置过期时间 ,一个是 备 key,不会设置过期 ,它们只是 key 不一样,但是 value 值是一样的,相当于给缓存数据做了个副本。
当业务线程访问不到「主 key 」的缓存数据时,就直接返回「备 key 」的缓存数据,然后在更新缓存的时候,同时更新「主 key 」和「备 key 」的数据。
双 key 策略的好处是,当主 key 过期了,有大量请求获取缓存数据的时候,直接返回备 key 的数据,这样可以快速响应请求。而不用因为 key 失效而导致大量请求被锁阻塞住(采用了互斥锁,仅一个请求来构建缓存),后续再通知后台线程,重新构建主 key 的数据。
4. 后台更新缓存
业务线程不再负责更新缓存,缓存也不设置有效期,而是 让缓存“永久有效”,并将更新缓存的工作交由后台线程定时更新 。
事实上,缓存数据不设置有效期,并不是意味着数据一直能在内存里,因为 当系统内存紧张的时候,有些缓存数据会被“淘汰” ,而在缓存被“淘汰”到下一次后台定时更新缓存的这段时间内,业务线程读取缓存失败就返回空值,业务的视角就以为是数据丢失了。
解决上面的问题的方式有两种。
第一种方式,后台线程不仅负责定时更新缓存,而且也负责 频繁地检测缓存是否有效 ,检测到缓存失效了,原因可能是系统紧张而被淘汰的,于是就要马上从数据库读取数据,并更新到缓存。
这种方式的检测时间间隔不能太长,太长也导致用户获取的数据是一个空值而不是真正的数据,所以检测的间隔最好是毫秒级的,但是总归是有个间隔时间,用户体验一般。
第二种方式,在业务线程发现缓存数据失效后(缓存数据被淘汰), 通过消息队列发送一条消息通知后台线程更新缓存 ,后台线程收到消息后,在更新缓存前可以判断缓存是否存在,存在就不执行更新缓存操作;不存在就读取数据库数据,并将数据加载到缓存。这种方式相比第一种方式缓存的更新会更及时,用户体验也比较好。
在业务刚上线的时候,我们最好提前把数据缓起来,而不是等待用户访问才来触发缓存构建,这就是所谓的 缓存预热 ,后台更新缓存的机制刚好也适合干这个事情
redis宕机
针对 Redis 故障宕机而引发的缓存雪崩问题,常见的应对方法有下面这几种:
- 服务熔断或请求限流机制;
- 构建 Redis 缓存高可靠集群;
1. 服务熔断或请求限流机制
因为 Redis 故障宕机而导致缓存雪崩问题时,我们可以启动服务熔断机制, 暂停业务应用对缓存服务的访问,直接返回错误 ,不用再继续访问数据库,从而降低对数据库的访问压力,保证数据库系统的正常运行,然后等到 Redis 恢复正常后,再允许业务应用访问缓存服务。
服务熔断机制是保护数据库的正常允许,但是暂停了业务应用访问缓存服系统,全部业务都无法正常工作
为了减少对业务的影响,我们可以启用请求限流机制, 只将少部分请求发送到数据库进行处理,再多的请求就在入口直接拒绝服务 ,等到 Redis 恢复正常并把缓存预热完后,再解除请求限流的机制。
2. 构建 Redis 缓存高可靠集群
服务熔断或请求限流机制是缓存雪崩发生后的应对方案,我们最好通过 主从节点的方式构建 Redis 缓存高可靠集群 。
如果 Redis 缓存的主节点故障宕机,从节点可以切换成为主节点,继续提供缓存服务,避免了由于 Redis 故障宕机而导致的缓存雪崩问题。
总结
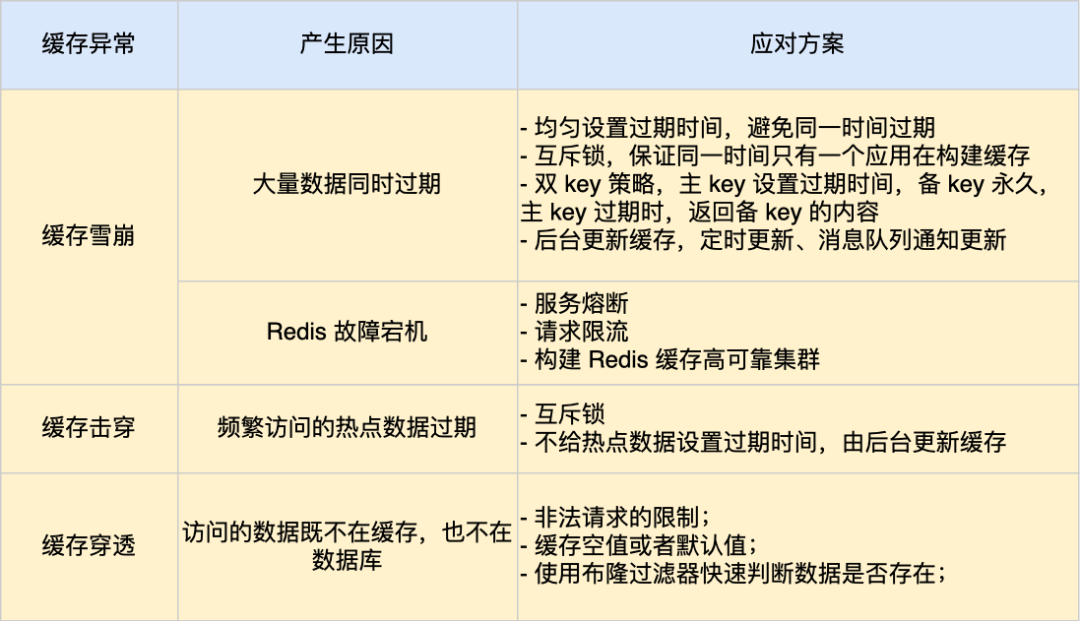
九:springboot
依赖
# 创建项目时的依赖
<!-- redis-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
服务器上redis的bind和protect-mode要改
yml
spring:
redis:
host: xxx.xxx.xxx.xxx
port: 6379
pojo
package com.xqm.redis.pojo;
public class Person {
private String name;
private Integer age;
public Person() {
}
public Person(String name, Integer age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age='" + age + '\'' +
'}';
}
}
template
package com.xqm.redis.config;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
@Configuration
public class MyTemplate {
@Bean
public StringRedisTemplate test(RedisConnectionFactory factory){
StringRedisTemplate stringRedisTemplate = new StringRedisTemplate(factory);
stringRedisTemplate.setHashValueSerializer(new Jackson2JsonRedisSerializer<Object>(Object.class));
return stringRedisTemplate;
}
}
redisConfig
package com.xqm.redis.config;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.xqm.redis.pojo.Person;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.data.redis.connection.RedisConnection;
import org.springframework.data.redis.core.HashOperations;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.ValueOperations;
import org.springframework.data.redis.hash.Jackson2HashMapper;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.stereotype.Component;
import java.util.Map;
@Component
public class RedisConfig {
/**
* 127.0.0.1:6379> keys *
* 1) "\xac\xed\x00\x05t\x00\x02k1"
*/
@Autowired
private RedisTemplate redisTemplate;
/**
* 127.0.0.1:6379> keys *
* 1) "k1"
*/
@Autowired
@Qualifier("test")
private StringRedisTemplate stringRedisTemplate;
@Autowired
ObjectMapper objectMapper;
@Autowired
private MyTemplate myTemplate;
/**
* 高级api
*/
public void testRedis() {
stringRedisTemplate.opsForValue().set("k1", "hello");
System.out.println(stringRedisTemplate.opsForValue().get("k1"));
}
/**
* 低级api
*/
public void testRedis1() {
RedisConnection connection = redisTemplate.getConnectionFactory().getConnection();
connection.set("hello".getBytes(),"hello".getBytes());
System.out.println(new String(connection.get("hello".getBytes())));
HashOperations<String, Object, Object> opsForHash = stringRedisTemplate.opsForHash();
opsForHash.put("smd","name","张三");
opsForHash.put("smd","age","22");
System.out.println(opsForHash.get("smd","name"));
System.out.println(opsForHash.entries("smd"));
}
public void testRedis2() {
Person person=new Person("张三",22);
Jackson2HashMapper jackson2HashMapper = new Jackson2HashMapper(objectMapper, false);
// 如果这里用stringRedisTemplate会发生序列化错误
redisTemplate.opsForHash().putAll("person", jackson2HashMapper.toHash(person));
// System.out.println(redisTemplate.opsForHash().entries("person"));
Map map = redisTemplate.opsForHash().entries("person");
Person person1 = objectMapper.convertValue(map, Person.class);
System.out.println(person1.getName());
}
public void testRedis3() {
Person person=new Person("张三",22);
Jackson2HashMapper jackson2HashMapper = new Jackson2HashMapper(objectMapper, false);
// stringRedisTemplate.setHashValueSerializer(new Jackson2JsonRedisSerializer<Object>(Object.class));
stringRedisTemplate.opsForHash().putAll("person", jackson2HashMapper.toHash(person));
Map map = stringRedisTemplate.opsForHash().entries("person");
Person person1 = objectMapper.convertValue(map, Person.class);
System.out.println(person1.getName());
}
}
十:redis相关面试题
redis主从节点时长连接还是短链接?
长连接
怎么判断 redis 某个节点是否正常工作?
redis 判断接点是否正常工作,基本都是通过互相的 ping-pong 心态检测机制,如果有一半以上的节点去 ping 一个节点的时候没有 pong 回应,集群就会认为这个节点挂掉了,会断开与这个节点的连接。
redis 主从节点发送的心态间隔是不一样的,而且作用也有一点区别:
- redis 主节点默认每隔 10 秒对从节点发送 ping 命令,判断从节点的存活性和连接状态,可通过参数repl-ping-slave-period控制发送频率。
- redis 从节点每隔 1 秒发送 replconf ack{offset} 命令,给主节点上报自身当前的复制偏移量,目的是为了:
- 实时监测主从节点网络状态;
- 上报自身复制偏移量, 检查复制数据是否丢失, 如果从节点数据丢失, 再从主节点的复制缓冲区中拉取丢失数据。
主从复制架构中,过期key如何处理?
主节点处理了一个key或者通过淘汰算法淘汰了一个key,这个时间主节点模拟一条del命令发送给从节点,从节点收到该命令后,就进行删除key的操作。
redis 是同步复制还是异步复制?
redis 主节点每次收到写命令之后,先写到内部的缓冲区,然后异步发送给从节点。
主从复制中两个 Buffer(replication buffer 、repl backlog buffer)有什么区别?
replication buffer 、repl backlog buffer 区别如下:
- replication buffer 是在全量复制阶段会出现,主库会给每个新连接的从库,分配一个 replication buffer;repl backlog buffer 是在增量复制阶段出现,一个主库只分配一个repl backlog buffer;
- 这两个 Buffer 都有大小限制的,当缓冲区满了之后。repl backlog buffer,因为是环形结构,会直接 覆盖起始位置数据 ,replication buffer则会导致连接断开,删除缓存,从库重新连接, 重新开始全量复制 。
redis 主从切换如何减少数据丢失?
异步复制同步丢失
对于 redis 主节点与从节点之间的数据复制,是异步复制的,当客户端发送写请求给主节点的时候,客户端会返回 ok,接着主节点将写请求异步同步给各个从节点,但是如果此时主节点还没来得及同步给从节点时发生了断电,那么主节点内存中的数据会丢失。
可以有 2 种解决方案:
- 第一种:客户端将数据暂时写入本地缓存和磁盘中,在一段时间后将本地缓存或者磁盘的数据发送给主节点,来保证数据不丢失;
- 第二种:客户端将数据写入到消息队列中,发送一个延时消费消息,比如10分钟后再消费消息队列中的数据,然后再写到主节点。
集群产生脑裂数据丢失
先来理解集群的脑裂现象,这就好比一个人有两个大脑,那么到底受谁控制呢?
那么在 redis 中,集群脑裂产生数据丢失的现象是怎样的呢?
在 redis 主从架构中,部署方式一般是「一主多从」,主节点提供写操作,从节点提供读操作。
如果主节点的网络突然发生了问题,它与所有的从节点都失联了,但是此时的主节点和客户端的网络是正常的,这个客户端并不知道 redis 内部已经出现了问题,还在照样的向这个失联的主节点写数据(过程A),此时这些数据被旧主节点缓存到了缓冲区里,因为主从节点之间的网络问题,这些数据都是无法同步给从节点的。
这时,哨兵也发现主节点失联了,它就认为主节点挂了(但实际上主节点正常运行,只是网络出问题了),于是哨兵就会在从节点中选举出一个 leeder 作为主节点,这时集群就有两个主节点了 —— 脑裂出现了 。
这时候网络突然好了,哨兵因为之前已经选举出一个新主节点了,它就会把旧主节点降级为从节点(A),然后从节点(A)会向新主节点请求数据同步, 因为第一次同步是全量同步的方式,此时的从节点(A)会清空掉自己本地的数据,然后再做全量同步。所以,之前客户端在过程 A 写入的数据就会丢失了,也就是集群产生脑裂数据丢失的问题 。
总结一句话就是:由于网络问题,集群节点之间失去联系。主从数据不同步;重新平衡选举,产生两个主服务。等网络恢复,旧主节点会降级为从节点,再与新主节点进行同步复制的时候,由于从节点会清空自己的缓冲区,所以导致之前客户端写入的数据丢失了。
解决方案:
当主节点发现从节点下线或者通信超时的总数量小于阈值时,那么禁止主节点进行写数据,直接把错误返回给客户端。
在 redis 的配置文件中有两个参数我们可以设置:
- min-slaves-to-write x,主节点必须要有至少 x 个从节点连接,如果小于这个数,主节点会禁止写数据。
- min-slaves-max-lag x,主从数据复制和同步的延迟不能超过 x 秒,如果超过,主节点会禁止写数据。
我们可以把 min-slaves-to-write 和 min-slaves-max-lag 这两个配置项搭配起来使用,分别给它们设置一定的阈值,假设为 N 和 T。
这两个配置项组合后的要求是,主库连接的从库中至少有 N 个从库,和主库进行数据复制时的 ACK 消息延迟不能超过 T 秒,否则,主库就不会再接收客户端的写请求了。
即使原主库是假故障,它在假故障期间也无法响应哨兵心跳,也不能和从库进行同步,自然也就无法和从库进行 ACK 确认了。这样一来,min-slaves-to-write 和 min-slaves-max-lag 的组合要求就无法得到满足, 原主库就会被限制接收客户端写请求,客户端也就不能在原主库中写入新数据了 。
等到新主库上线时,就只有新主库能接收和处理客户端请求,此时,新写的数据会被直接写到新主库中。而原主库会被哨兵降为从库,即使它的数据被清空了,也不会有新数据丢失。我再来给你举个例子。
假设我们将 min-slaves-to-write 设置为 1,把 min-slaves-max-lag 设置为 12s,把哨兵的 down-after-milliseconds 设置为 10s,主库因为某些原因卡住了 15s,导致哨兵判断主库客观下线,开始进行主从切换。同时,因为原主库卡住了 15s,没有一个从库能和原主库在 12s 内进行数据复制,原主库也无法接收客户端请求了。这样一来,主从切换完成后,也只有新主库能接收请求,不会发生脑裂,也就不会发生数据丢失的问题了。
redis 主从如何做到故障自动切换?
主节点挂了 ,从节点是无法自动升级为主节点的,这个过程需要人工处理,在此期间 redis 无法对外提供写操作。
此时,redis 哨兵机制就登场了,哨兵在发现主节点出现故障时,由哨兵自动完成故障发现和故障转移,并通知给应用方,从而实现高可用性。
Redis线程模型
1.Redis是单线程吗
Redis 单线程指的是「接收客户端请求->解析请求 ->进行数据读写等操作->发送数据给客户端」这个过程是由一个线程(主线程)来完成的 ,这也是我们常说 Redis 是单线程的原因。
但是, Redis 程序并不是单线程的 ,Redis 在启动的时候,是会 启动后台线程 (BIO)的:
- Redis 在 2.6 版本 ,会启动 2 个后台线程,分别处理关闭文件、AOF 刷盘这两个任务;
- Redis 在 4.0 版本之后 ,新增了一个新的后台线程,用来异步释放 Redis 内存,也就是 lazyfree 线程。例如执行 unlink key / flushdb async / flushall async 等命令,会把这些删除操作交给后台线程来执行,好处是不会导致 Redis 主线程卡顿。因此,当我们要删除一个大 key 的时候,不要使用 del 命令删除,因为 del 是在主线程处理的,这样会导致 Redis 主线程卡顿,因此我们应该使用 unlink 命令来异步删除大key。
之所以 Redis 为「关闭文件、AOF 刷盘、释放内存」这些任务创建单独的线程来处理,是因为这些任务的操作都是很耗时的,如果把这些任务都放在主线程来处理,那么 Redis 主线程就很容易发生阻塞,这样就无法处理后续的请求了。
后台线程相当于一个消费者,生产者把耗时任务丢到任务队列中,消费者(BIO)不停轮询这个队列,拿出任务就去执行对应的方法即可。
关闭文件、AOF 刷盘、释放内存这三个任务都有各自的任务队列:
- BIO_CLOSE_FILE,关闭文件任务队列:当队列有任务后,后台线程会调用 close(fd) ,将文件关闭;
- BIO_AOF_FSYNC,AOF刷盘任务队列:当 AOF 日志配置成 everysec 选项后,主线程会把 AOF 写日志操作封装成一个任务,也放到队列中。当发现队列有任务后,后台线程会调用 fsync(fd),将 AOF 文件刷盘,
- BIO_LAZY_FREE,lazy free 任务队列:当队列有任务后,后台线程会 free(obj) 释放对象 / free(dict) 删除数据库所有对象 / free(skiplist) 释放跳表对象;
2.Redis 单线程模式是怎样的?
Redis 6.0 版本之前的单线模式如下图:

图中的蓝色部分是一个事件循环,是由主线程负责的,可以看到网络 I/O 和命令处理都是单线程。 Redis 初始化的时候,会做下面这几件事情:
- 首先,调用 epoll_create() 创建一个 epoll 对象和调用 socket() 一个服务端 socket
- 然后,调用 bind() 绑定端口和调用 listen() 监听该 socket;
- 然后,将调用 epoll_ctl() 将 listen socket 加入到 epoll,同时注册「连接事件」处理函数。
初始化完后,主线程就进入到一个 事件循环函数 ,主要会做以下事情:
- 首先,先调用 处理发送队列函数 ,看是发送队列里是否有任务,如果有发送任务,则通过 write 函数将客户端发送缓存区里的数据发送出去,如果这一轮数据没有发送完,就会注册写事件处理函数,等待 epoll_wait 发现可写后再处理 。
- 接着,调用 epoll_wait 函数等待事件的到来:
- 如果是连接事件到来,则会调用 连接事件处理函数 ,该函数会做这些事情:调用 accpet 获取已连接的 socket -> 调用 epoll_ctl 将已连接的 socket 加入到 epoll -> 注册「读事件」处理函数;
- 如果是读事件到来,则会调用 读事件处理函数 ,该函数会做这些事情:调用 read 获取客户端发送的数据 -> 解析命令 -> 处理命令 -> 将客户端对象添加到发送队列 -> 将执行结果写到发送缓存区等待发送;
- 如果是写事件到来,则会调用 写事件处理函数 ,该函数会做这些事情:通过 write 函数将客户端发送缓存区里的数据发送出去,如果这一轮数据没有发送完,就会继续注册写事件处理函数,等待 epoll_wait 发现可写后再处理 。
以上就是 Redis 单线模式的工作方式,如果你想看源码解析,可以参考这一篇:为什么单线程的 Redis 如何做到每秒数万 QPS ?(opens new window)
3.Redis 采用单线程为什么还这么快?
官方使用基准测试的结果是, 单线程的 Redis 吞吐量可以达到 10W/每秒 ,如下图所示:
 之所以 Redis 采用单线程(网络 I/O 和执行命令)那么快,有如下几个原因:
之所以 Redis 采用单线程(网络 I/O 和执行命令)那么快,有如下几个原因:
- Redis 的大部分操作 都在内存中完成 ,并且采用了高效的数据结构,因此 Redis 瓶颈可能是机器的内存或者网络带宽,而并非 CPU,既然 CPU 不是瓶颈,那么自然就采用单线程的解决方案了;
- Redis 采用单线程模型可以 避免了多线程之间的竞争 ,省去了多线程切换带来的时间和性能上的开销,而且也不会导致死锁问题。
- Redis 采用了 I/O 多路复用机制处理大量的客户端 Socket 请求,IO 多路复用机制是指一个线程处理多个 IO 流,就是我们经常听到的 select/epoll 机制。简单来说,在 Redis 只运行单线程的情况下,该机制允许内核中,同时存在多个监听 Socket 和已连接 Socket。内核会一直监听这些 Socket 上的连接请求或数据请求。一旦有请求到达,就会交给 Redis 线程处理,这就实现了一个 Redis 线程处理多个 IO 流的效果。
4.Redis 6.0 之前为什么使用单线程?
我们都知道单线程的程序是无法利用服务器的多核 CPU 的,那么早期 Redis 版本的主要工作(网络 I/O 和执行命令)为什么还要使用单线程呢?我们不妨先看一下Redis官方给出的FAQ (opens new window)。
 核心意思是: CPU 并不是制约 Redis 性能表现的瓶颈所在 ,更多情况下是受到内存大小和网络I/O的限制,所以 Redis 核心网络模型使用单线程并没有什么问题,如果你想要使用服务的多核CPU,可以在一台服务器上启动多个节点或者采用分片集群的方式。
核心意思是: CPU 并不是制约 Redis 性能表现的瓶颈所在 ,更多情况下是受到内存大小和网络I/O的限制,所以 Redis 核心网络模型使用单线程并没有什么问题,如果你想要使用服务的多核CPU,可以在一台服务器上启动多个节点或者采用分片集群的方式。
除了上面的官方回答,选择单线程的原因也有下面的考虑。
使用了单线程后,可维护性高,多线程模型虽然在某些方面表现优异,但是它却引入了程序执行顺序的不确定性,带来了并发读写的一系列问题, 增加了系统复杂度、同时可能存在线程切换、甚至加锁解锁、死锁造成的性能损耗 。
5.Redis 6.0 之后为什么引入了多线程?
虽然 Redis 的主要工作(网络 I/O 和执行命令)一直是单线程模型,但是 在 Redis 6.0 版本之后,也采用了多个 I/O 线程来处理网络请求 , 这是因为随着网络硬件的性能提升,Redis 的性能瓶颈有时会出现在网络 I/O 的处理上 。
所以为了提高网络 I/O 的并行度,Redis 6.0 对于网络 I/O 采用多线程来处理。但是对于命令的执行,Redis 仍然使用单线程来处理,所以大家不要误解 Redis 有多线程同时执行命令。
Redis 官方表示, Redis 6.0 版本引入的多线程 I/O 特性对性能提升至少是一倍以上 。
Redis 6.0 版本支持的 I/O 多线程特性,默认情况下 I/O 多线程只针对发送响应数据(write client socket),并不会以多线程的方式处理读请求(read client socket)。要想开启多线程处理客户端读请求,就需要把 Redis.conf 配置文件中的 io-threads-do-reads 配置项设为 yes。
//读请求也使用io多线程
io-threads-do-reads yes
同时, Redis.conf 配置文件中提供了 IO 多线程个数的配置项。
// io-threads N,表示启用 N-1 个 I/O 多线程(主线程也算一个 I/O 线程)
io-threads 4
关于线程数的设置,官方的建议是如果为 4 核的 CPU,建议线程数设置为 2 或 3,如果为 8 核 CPU 建议线程数设置为 6,线程数一定要小于机器核数,线程数并不是越大越好。
因此, Redis 6.0 版本之后,Redis 在启动的时候,默认情况下会创建 6 个线程:
- Redis-server : Redis的主线程,主要负责执行命令;
- bio_close_file、bio_aof_fsync、bio_lazy_free:三个后台线程,分别异步处理关闭文件任务、AOF刷盘任务、释放内存任务;
- io_thd_1、io_thd_2、io_thd_3:三个 I/O 线程,io-threads 默认是 4 ,所以会启动 3(4-1)个 I/O 多线程,用来分担 Redis 网络 I/O 的压力。
Redis实战
Redis 如何实现延迟队列?
延迟队列是指把当前要做的事情,往后推迟一段时间再做。延迟队列的常见使用场景有以下几种:
在淘宝、京东等购物平台上下单,超过一定时间未付款,订单会自动取消;
打车的时候,在规定时间没有车主接单,平台会取消你的单并提醒你暂时没有车主接单;
点外卖的时候,如果商家在10分钟还没接单,就会自动取消订单;
在 Redis 可以使用有序集合(ZSet)的方式来实现延迟消息队列的,ZSet 有一个 Score 属性可以用来存储延迟执行的时间。
使用 zadd score1 value1 命令就可以一直往内存中生产消息。再利用 zrangebysocre 查询符合条件的所有待处理的任务, 通过循环执行队列任务即可。
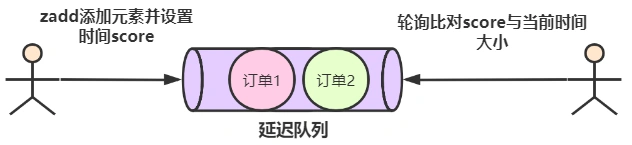
Redis 的大 key 如何处理?
什么是 Redis 大 key?
大 key 并不是指 key 的值很大,而是 key 对应的 value 很大。
一般而言,下面这两种情况被称为大 key:
- String 类型的值大于 10 KB;
- Hash、List、Set、ZSet 类型的元素的个数超过 5000个;
大 key 会造成什么问题?
大 key 会带来以下四种影响:
- 客户端超时阻塞。由于 Redis 执行命令是单线程处理,然后在操作大 key 时会比较耗时,那么就会阻塞 Redis,从客户端这一视角看,就是很久很久都没有响应。
- 引发网络阻塞。每次获取大 key 产生的网络流量较大,如果一个 key 的大小是 1 MB,每秒访问量为 1000,那么每秒会产生 1000MB 的流量,这对于普通千兆网卡的服务器来说是灾难性的。
- 阻塞工作线程。如果使用 del 删除大 key 时,会阻塞工作线程,这样就没办法处理后续的命令。
- 内存分布不均。集群模型在 slot 分片均匀情况下,会出现数据和查询倾斜情况,部分有大 key 的 Redis 节点占用内存多,QPS 也会比较大。
如何找到大 key ?
1、redis-cli --bigkeys 查找大key
可以通过 redis-cli --bigkeys 命令查找大 key:
redis-cli -h 127.0.0.1 -p6379 -a "password" -- bigkeys
使用的时候注意事项:
- 最好选择在从节点上执行该命令。因为主节点上执行时,会阻塞主节点;
- 如果没有从节点,那么可以选择在 Redis 实例业务压力的低峰阶段进行扫描查询,以免影响到实例的正常运行;或者可以使用 -i 参数控制扫描间隔,避免长时间扫描降低 Redis 实例的性能。
该方式的不足之处:
- 这个方法只能返回每种类型中最大的那个 bigkey,无法得到大小排在前 N 位的 bigkey;
- 对于集合类型来说,这个方法只统计集合元素个数的多少,而不是实际占用的内存量。但是,一个集合中的元素个数多,并不一定占用的内存就多。因为,有可能每个元素占用的内存很小,这样的话,即使元素个数有很多,总内存开销也不大;
2、使用 SCAN 命令查找大 key
使用 SCAN 命令对数据库扫描,然后用 TYPE 命令获取返回的每一个 key 的类型。
对于 String 类型,可以直接使用 STRLEN 命令获取字符串的长度,也就是占用的内存空间字节数。
对于集合类型来说,有两种方法可以获得它占用的内存大小:
- 如果能够预先从业务层知道集合元素的平均大小,那么,可以使用下面的命令获取集合元素的个数,然后乘以集合元素的平均大小,这样就能获得集合占用的内存大小了。List 类型:
LLEN命令;Hash 类型:HLEN命令;Set 类型:SCARD命令;Sorted Set 类型:ZCARD命令; - 如果不能提前知道写入集合的元素大小,可以使用
MEMORY USAGE命令(需要 Redis 4.0 及以上版本),查询一个键值对占用的内存空间。
3、使用 RdbTools 工具查找大 key
使用 RdbTools 第三方开源工具,可以用来解析 Redis 快照(RDB)文件,找到其中的大 key。
比如,下面这条命令,将大于 10 kb 的 key 输出到一个表格文件。
rdb dump.rdb -c memory --bytes 10240 -f redis.csv
如何删除大 key?
删除操作的本质是要释放键值对占用的内存空间,不要小瞧内存的释放过程。
释放内存只是第一步,为了更加高效地管理内存空间,在应用程序释放内存时,操作系统需要把释放掉的内存块插入一个空闲内存块的链表,以便后续进行管理和再分配。这个过程本身需要一定时间,而且会阻塞当前释放内存的应用程序。
所以,如果一下子释放了大量内存,空闲内存块链表操作时间就会增加,相应地就会造成 Redis 主线程的阻塞,如果主线程发生了阻塞,其他所有请求可能都会超时,超时越来越多,会造成 Redis 连接耗尽,产生各种异常。
因此,删除大 key 这一个动作,我们要小心。具体要怎么做呢?这里给出两种方法:
- 分批次删除
- 异步删除(Redis 4.0版本以上)
1、分批次删除
对于 删除大 Hash ,使用 hscan 命令,每次获取 100 个字段,再用 hdel 命令,每次删除 1 个字段。
Python代码:
def del_large_hash():
r = redis.StrictRedis(host='redis-host1', port=6379)
large_hash_key ="xxx" #要删除的大hash键名
cursor = '0'
while cursor != 0:
# 使用 hscan 命令,每次获取 100 个字段
cursor, data = r.hscan(large_hash_key, cursor=cursor, count=100)
for item in data.items():
# 再用 hdel 命令,每次删除1个字段
r.hdel(large_hash_key, item[0])
对于 删除大 List ,通过 ltrim 命令,每次删除少量元素。
Python代码:
def del_large_list():
r = redis.StrictRedis(host='redis-host1', port=6379)
large_list_key = 'xxx' #要删除的大list的键名
while r.llen(large_list_key)>0:
#每次只删除最右100个元素
r.ltrim(large_list_key, 0, -101)
对于 删除大 Set ,使用 sscan 命令,每次扫描集合中 100 个元素,再用 srem 命令每次删除一个键。
Python代码:
def del_large_set():
r = redis.StrictRedis(host='redis-host1', port=6379)
large_set_key = 'xxx' # 要删除的大set的键名
cursor = '0'
while cursor != 0:
# 使用 sscan 命令,每次扫描集合中 100 个元素
cursor, data = r.sscan(large_set_key, cursor=cursor, count=100)
for item in data:
# 再用 srem 命令每次删除一个键
r.srem(large_size_key, item)
对于 删除大 ZSet ,使用 zremrangebyrank 命令,每次删除 top 100个元素。
Python代码:
def del_large_sortedset():
r = redis.StrictRedis(host='large_sortedset_key', port=6379)
large_sortedset_key='xxx'
while r.zcard(large_sortedset_key)>0:
# 使用 zremrangebyrank 命令,每次删除 top 100个元素
r.zremrangebyrank(large_sortedset_key,0,99)
2、异步删除
从 Redis 4.0 版本开始,可以采用异步删除法, 用 unlink 命令代替 del 来删除 。
这样 Redis 会将这个 key 放入到一个异步线程中进行删除,这样不会阻塞主线程。
Redis 管道有什么用?
管道技术(Pipeline)是客户端提供的一种批处理技术,用于一次处理多个 Redis 命令,从而提高整个交互的性能。
普通命令模式,如下图所示:
管道模式,如下图所示:
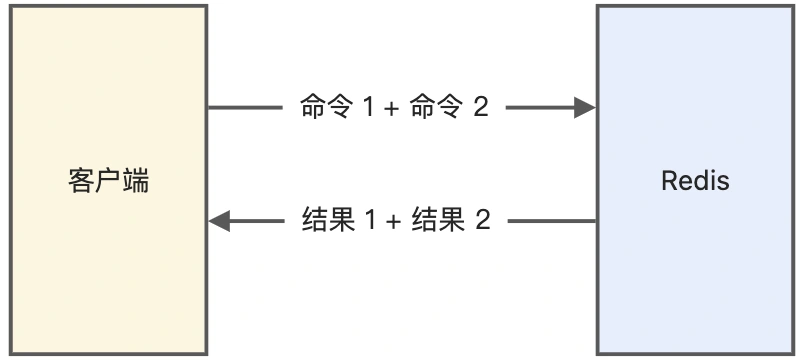
使用 管道技术可以解决多个命令执行时的网络等待 ,它是把多个命令整合到一起发送给服务器端处理之后统一返回给客户端,这样就免去了每条命令执行后都要等待的情况,从而有效地提高了程序的执行效率。
但使用管道技术也要注意避免发送的命令过大,或管道内的数据太多而导致的网络阻塞。
要注意的是,管道技术本质上是客户端提供的功能,而非 Redis 服务器端的功能。
Redis 事务支持回滚吗?
Redis 中并没有提供回滚机制 ,虽然 Redis 提供了 DISCARD 命令,但是这个命令只能用来主动放弃事务执行,把暂存的命令队列清空,起不到回滚的效果。
下面是 DISCARD 命令用法:
#读取 count 的值4
127.0.0.1:6379> GET count
"1"
#开启事务
127.0.0.1:6379> MULTI
OK
#发送事务的第一个操作,对count减1
127.0.0.1:6379> DECR count
QUEUED
#执行DISCARD命令,主动放弃事务
127.0.0.1:6379> DISCARD
OK
#再次读取a:stock的值,值没有被修改
127.0.0.1:6379> GET count
"1"
事务执行过程中,如果命令入队时没报错,而事务提交后,实际执行时报错了,正确的命令依然可以正常执行,所以这可以看出 Redis 并不一定保证原子性 (原子性:事务中的命令要不全部成功,要不全部失败)。
比如下面这个例子:
#获取name原本的值
127.0.0.1:6379> GET name
"xiaolin"
#开启事务
127.0.0.1:6379> MULTI
OK
#设置新值
127.0.0.1:6379(TX)> GET name xialincoding
QUEUED
#注意,这条命令是错误的
# expire 过期时间正确来说是数字,并不是‘10s’字符串,但是还是入队成功了
127.0.0.1:6379(TX)> EXPIRE name 10s
QUEUED
#提交事务,执行报错
#可以看到 set 执行成功,而 expire 执行错误。
127.0.0.1:6379(TX)> EXEC
1) OK
2) (error) ERR value is not an integer or out of range
#可以看到,name 还是被设置为新值了
127.0.0.1:6379> GET name
"xialincoding"
为什么Redis 不支持事务回滚?
Redis 官方文档 (opens new window)的解释如下:
 大概的意思是,作者不支持事务回滚的原因有以下两个:
大概的意思是,作者不支持事务回滚的原因有以下两个:
- 他认为 Redis 事务的执行时,错误通常都是编程错误造成的,这种错误通常只会出现在开发环境中,而很少会在实际的生产环境中出现,所以他认为没有必要为 Redis 开发事务回滚功能;
- 不支持事务回滚是因为这种复杂的功能和 Redis 追求的简单高效的设计主旨不符合。
这里不支持事务回滚,指的是不支持事务运行时错误的事务回滚。